Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Gigabyte GA-7PESH1 BIOS
As the server team at Gigabyte is essentially a different company to the consumer motherboard team, there is little cross talk and parity between the two. When the consumer motherboard side used the C606 server chipset for the Gigabyte X79S-UP5, the whole package got the consumer motherboard BIOS, software and utilities. With this C602 enabled GA-7PESH1, utilities such as the BIOS and software are designed in the server department and are not as well designed as their consumer counterparts.
In terms of the BIOS, this means we get a reskinned Aptio Setup Utility from American Megatrends, rather than the 3D BIOS implementation. Aesthetically the BIOS is prehistoric in terms of recent trends, but the server based platform has a lot more to deal with – having just a list of options make it very easy to add/subtract functionality as required.
Updating the BIOS is a hassle from the off – there is no update feature in the BIOS itself, and the utilities provided by Gigabyte are limited to DOS bootable USB sticks only. This means sourcing a DOS bootable USB stick in order to put the software onboard. There are a few utilities online that will streamline this process, but due to some memory issues I initially had with the motherboard, thankfully Gigabyte talked me through the exact procedure.
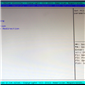
The front screen of the BIOS is basic at best, telling us the BIOS version, the total memory installed and the system date. Despite the market orientation for such a product, some indication as to what the motherboard is and the CPUs that are installed, at the bare minimum, would have been nice.
Apologies for the quality of the BIOS images – the BIOS has no ‘Print Screen to USB’ utility, and thus these images are taken with my DSLR in less-than-ideal lighting conditions.
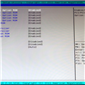
The Advanced menu tab has options relating to PCI Configuration, Trusted Computing (TPM), CPU identification and configuration (such as Hyperthreading and Power Management), error logging, SATA configuration, Super IO configuration and Serial Port options.
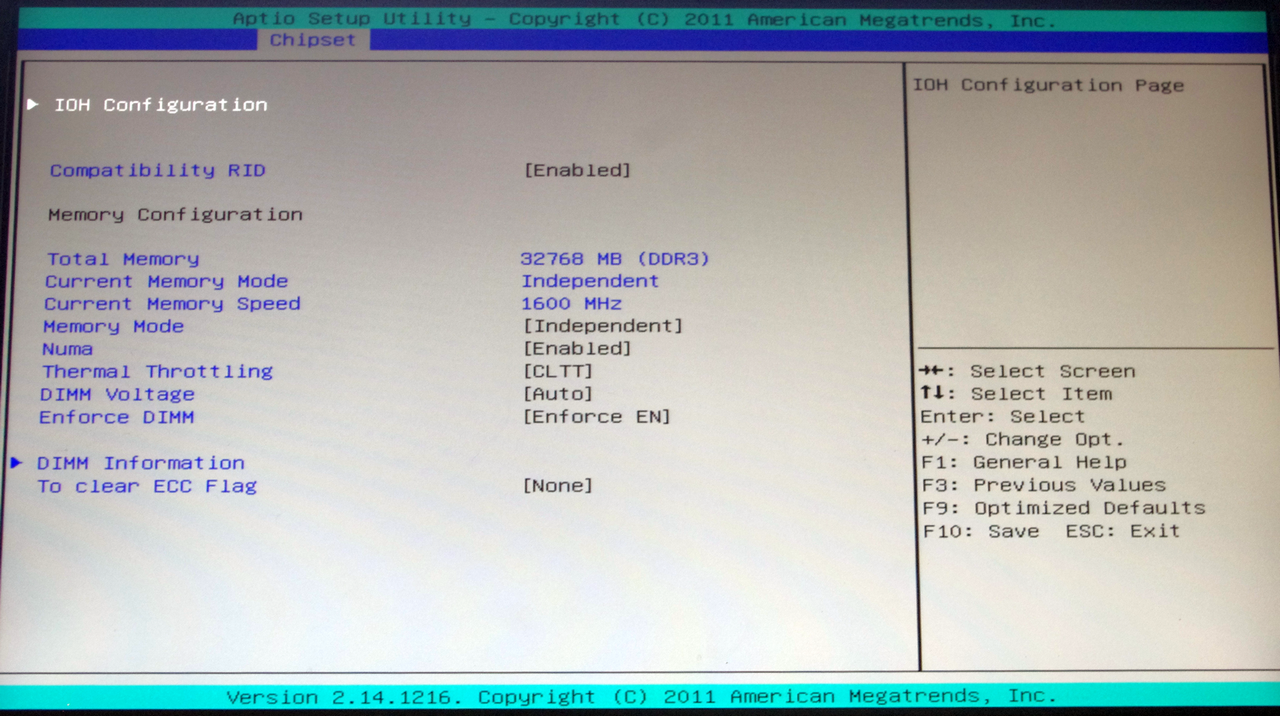
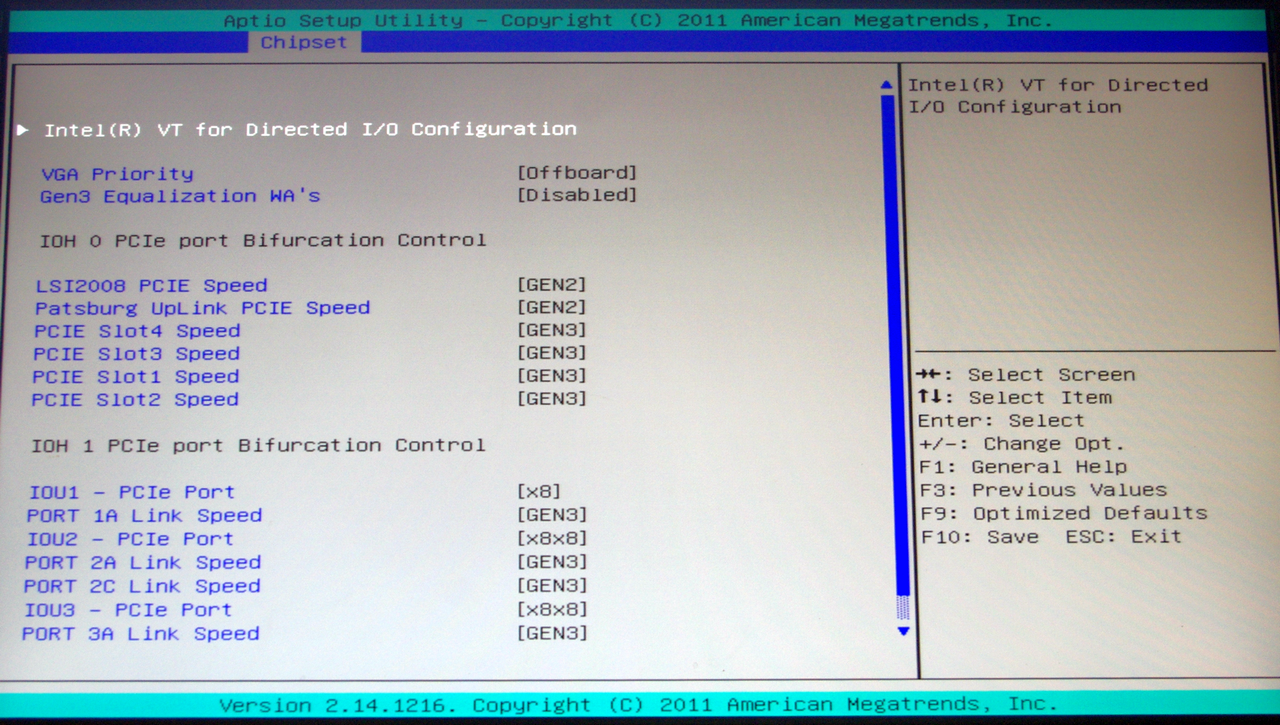
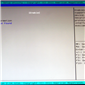
The Chipset tab option gives us access to North Bridge/South Bridge options, such as the memory controller, VT-d, PCIe lane counts and memory detection.
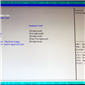
In order to access the server management features, after an ethernet cable has been plugged into the server management port, the IP for login details can be found in the server management tab:
Other options in the BIOS are for boot priority and boot override.








64 Comments
View All Comments
Hulk - Saturday, January 5, 2013 - link
I had no idea you were so adept with mathematics. "Consider a point in space..." Reading this brought me back to Finite Element Analysis in college! I am very impressed. Being a ME I would have preferred some flow models using the Navier-Stokes equations, but hey I like chemistry as well.IanCutress - Saturday, January 5, 2013 - link
I never did any FEM so wouldn't know where to start. The next angle of testing would have been using a C++ AMP Fluid Dynamics Simulation and adjusting the code from the SDK example like with the n-Body testing. If there is enough interest, I could spend a few days organising it for the normal motherboard reviews :)Ian
mayankleoboy1 - Saturday, January 5, 2013 - link
How the frick did you get the i7-3770K to *5.4GHZ* ? :shock:How the frick did you get the i7-3770K to *5.0GHZ* ? :shock:
IanCutress - Saturday, January 5, 2013 - link
A few members of the Overclock.net HWBot team helped testing by running my benchmark while they were using DICE/LN2/Phase Change for overclocking contests (i.e. not 24/7 runs). The i7-3770K will go over 7 GHz if (a) you get a good chip, (b) cool it down enough, and (c) know what you are doing. If you're interested in competitive overclocking, head over to HWBot, Xtreme Systems or Overclock.net - there are plenty of people with info to help you get started.Ian
JlHADJOE - Tuesday, January 8, 2013 - link
The incredible performance of those overclocked Ivy bridge systems here really hammers home the importance of raw IPC. You can spend a lot of time optimizing code, but IPC is free speed when it's available.jd_tiger - Saturday, January 5, 2013 - link
http://www.youtube.com/watch?v=Ccoj5lhLmSQsmonsees - Saturday, January 5, 2013 - link
You might try modifying your algorithm to pin the data to a specific core (therefore cache) to keep the thrashing as low as possible. Google "processor affinity c++". I will admit this adds complexity to your straightforward algorithm. In C#, I would use a parallel loop with a range partition to do it as a starting point: http://msdn.microsoft.com/en-us/library/dd560853.a...nickgully - Saturday, January 5, 2013 - link
Mr. Cutress,Do you think with all the virtualized CPU available, researchers will still build their own system as it is something concrete to put into a grant application, versus the power-by-the-hour of cloud computing?
Thanks.
IanCutress - Saturday, January 5, 2013 - link
We examined both scenarios. Our university had cluster time to buy, and there is always the Amazon cloud. In our calculation, getting a 16 thread machine from Dell paid for itself in under six months of continuous running, and would not require a large adjustment in the way people were currently coding (i.e. staying in Windows rather than moving to Linux), and could also be passed down the research group when newer hardware is released.If you are using production level code and manipulating it each time to get results, and you can guarantee the results will be good each time, then power-by-the-hour could work. As we were constantly writing and testing new code for different scenarios, the build/buy your own workstation won out. Having your own system also helps in building GPU codes, if you want to buy a better GPU card it is easier to swap out rather than relying on a cloud computing upgrade.
Ian
jtv - Sunday, January 6, 2013 - link
One big consideration is who the researchers are. I work in x-ray spectroscopy (as a computational theorist). Experimentalists in this field use some of our codes without wanting to bother with having big computational resources. We have looked at trying to provide some of our codes through some cloud-based service so that it can be used on demand.Otherwise I would agree with Ian's reply. When I'm improving code, debugging code, or trying to implement new theoretical approaches I absolutely want my own hardware to do it on.