The NVIDIA GTC 2024 Keynote Live Blog (Starts at 1:00pm PT/20:00 UTC)
by Ryan Smith & Gavin Bonshor on March 18, 2024 3:00 PM EST
We're here in sunny San Jose California for the return of an event that's been a long-time coming: NVIDIA's in-person GTC. The Spring 2024 event, NVIDIA's marquee event for the year, promises to be a big one for NVIDIA, as the company is due to deliver updates on its all-important datacenter accelerator products – the successor to the GH100 GPU and its Hopper architecture – along with NVIDIA's other professional/enterprise hardware, networking gear, and, of course, a slew of software stack updates.
In the 5 years since NVIDIA was last able to hold a Spring GTC in person, a great deal has changed for the company. They're now the third biggest company in the world, thanks to explosive sales growth (and even further growth expectations) due in large part to the combination of GPT-3/4 and other transformer models, and NVIDIA's transformer-optimized H100 accelerator. As a result, NVIDIA is riding high in Silicon Valley, but to keep doing so they also will need to deliver the next big thing to push the envelope on performance, and keep a number of hungry competitors off their turf.
Headlining today's keynote is, of course, NVIDIA CEO Jensen Huang, whose kick-off address has finally outgrown the San Jose Convention Center. As a result, Huang is filling up the local SAP Center arena instead. Suffice it to say, it's a bigger venue for a bigger audience for a much bigger company.
So come join the AnandTech crew for our live blog coverage of NVIDIA's biggest enterprise keynote in years. The presentation kicks off at 1pm Pacific, 4pm Eastern, 20:00 UTC.

04:04PM EDT - This is Ryan. Apologies for the late start here folks, it's been an interesting time getting everyone down to the floor and settled. (I'm told the capacity of SAP Arena for concerts is 18,500 people. With this floor layout, there may be closer to 20,000 here)
04:04PM EDT - So without further ado, here's Jensen!
04:04PM EDT - "This is not a concert. You have arrived at a developers conference"

04:04PM EDT - "I sense a very heavy weight in the room all of a sudden"
04:05PM EDT - Jensen is recapping the many technologies to be seen here. "Even artificial intelligence"

04:06PM EDT - Showing off a iist of exhibitors. It's a very big list of names
04:07PM EDT - "The computer is the single most important instrument in society today"

04:07PM EDT - How did we get here? Jensen drew a comic flow chart
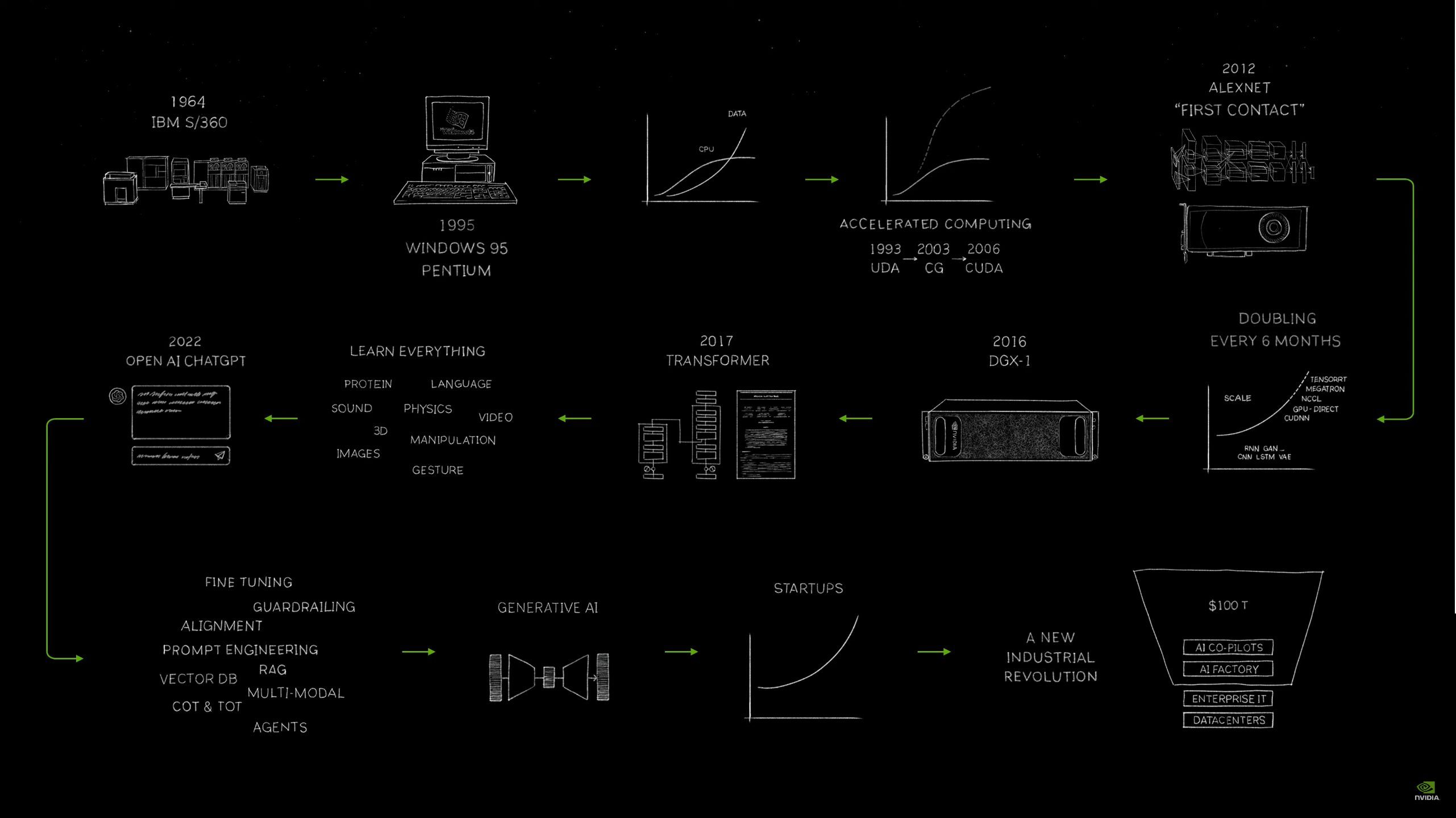
04:09PM EDT - CUDA became a success... eventually. A bit later than Jensen would have liked
04:09PM EDT - 2023: Generative AI emerged, and a new industry begins
04:09PM EDT - "The software never existed before, it is a brand new category"
04:10PM EDT - Comparing generative AI to the industrial revolution and the age of energy
04:11PM EDT - "We're going to talk about how we're doing computing next"

04:11PM EDT - As well as software and applications in this industry. And how to start preparing for what's next
04:11PM EDT - Everything we'll be shown today is a simulation, not an animation
04:12PM EDT - "It's being animated with robotics. It's being animated with artificial intelligence"
04:12PM EDT - "Everything is homemade"
04:13PM EDT - Rolling a demo reel of GPU-accelerated applications

04:13PM EDT - Warp, PhysX Flow, Photoshop, and more
04:15PM EDT - NVIDIA's GPUs are only worth using because of the software written for them. So NVIDIA has always made it a point to showcase what the software development community has been up to

04:15PM EDT - "General purpose computing has run out of steam"
04:15PM EDT - Need new ways to keep growing computing. Keep consuming computing
04:16PM EDT - It's not about driving down the cost, it's about driving up the scale

04:16PM EDT - Jensen would like to simulate everything they do in digital twin virtual environments
04:17PM EDT - NVIDIA will have partners joining them today
04:17PM EDT - Jensen will be announcing several important partnerships
04:17PM EDT - Ansys

04:18PM EDT - Sysopsys. NVIDIA's very first software partner. Literally
04:18PM EDT - Accelerating computational lithography

04:18PM EDT - TSMC is announcing today that they're going into production with cuLitho

04:19PM EDT - Cadence, the EDA tool maker, is joining Club GPU as well
04:20PM EDT - Going to connect Cadence's digital twin platform to Omniverse
04:20PM EDT - Omniverse will be the fundamental operating system for digital twins
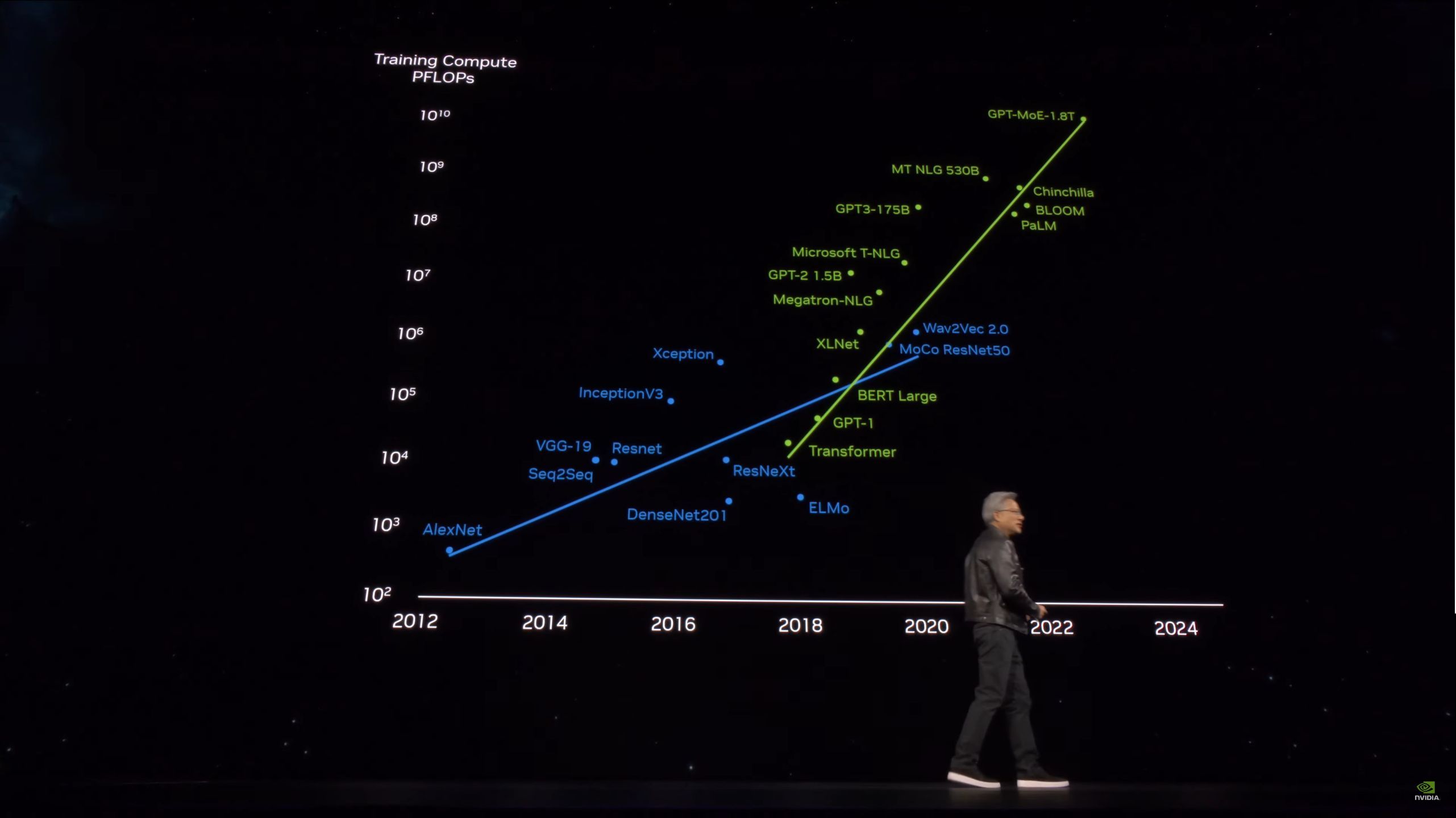
04:20PM EDT - Now recapping the history of large language models, and the hardware driving them
04:21PM EDT - Doubling the parameter count requires increasing the token count
04:21PM EDT - 1.8T parameters is the current largest model. This requires several billion tokens to train
04:22PM EDT - Even a PetaFLOP GPU would take 30 billion seconds to train that model. That's 1000 years

04:22PM EDT - "What we need are bigger GPUs" "Much much bigger GPUs"
04:22PM EDT - The answer is to put a whole bunch of GPUs together

04:23PM EDT - As well as developing technologies like NVLink and tensor cores
04:23PM EDT - To help the world build these bigger systems, NVIDIA has to build them first
04:24PM EDT - "We need even larger models"

04:26PM EDT - "We're going to have to build even bigger GPUs"
04:26PM EDT - And here's Blackwell. "A very, very big GPU"
04:27PM EDT - Named after David Backwell, the mathematician and game theorist
04:27PM EDT - Now rolling a video
04:27PM EDT - Two dies on one package, full cache coherency
04:27PM EDT - 208B transistors

04:27PM EDT - 192GB HBM3E@8Gbps
04:27PM EDT - 1.8TB/sec NVLink bandwidth per chip

04:28PM EDT - Available as an accelerator and as a Grace Blackwell Superchip

04:28PM EDT - NVLink 5. Which comes with a new switch chip


04:29PM EDT - And NVDIA is building a rack-scale offering using GB200 and the new NVLink opertions, GB200 NVL72
04:29PM EDT - NVLink 5 scales up to 576 GPUs

04:29PM EDT - "Blackwell is not a chip. It's the name of a platform"
04:30PM EDT - Holding up Blackwell next to a GH100 GPU

04:30PM EDT - "It's okay, Hopper"

04:30PM EDT - "You're very good. Good girl"

04:31PM EDT - 10TBps link between the dies
04:31PM EDT - No memory locality issues or cache issues. CUDA sees it as a single GPU

04:32PM EDT - The chip goes into two types of systems. B100, which is designed to be drop-in compatible with H100/H200 HGX systems

04:33PM EDT - Jensen showing off Blackwell boards... and trying not to drop them

04:33PM EDT - GB200. 1 Grace CPU + 2 Blackwell GPUs (4 GPU dies)

04:33PM EDT - GB200 is memory coherent

04:34PM EDT - "This is s miracle"
04:34PM EDT - NVLink on top, PCIe Gen 6 on the bottom

04:34PM EDT - And that's Grace Blackwell
04:34PM EDT - "But there's more!"
04:35PM EDT - "We need a whole lot of new features"
04:35PM EDT - Second generation transformer engine
04:35PM EDT - Automaticaly and dynamically recast numerical formats to a lower precision when possible

04:36PM EDT - AI is about probability. Need to figure out when you can use lower precisions and when you can't
04:36PM EDT - Support down to FP4
04:36PM EDT - 5th generation NVLink

04:38PM EDT - Jensen is also pushing the importance of reliability. No massive cluster is going to stay up 100% of the time, especially running weeks on end
04:38PM EDT - So NVIDIA has added a RAS engine that can do a full, in-system self-test of a node
04:39PM EDT - Security remains a popular subject as well. Protecting the results of a model training, protecting the model itself. Which means supporting full speed encryption throughout
04:40PM EDT - Blackwell also adds a line decompression engine that can sustain 800GB/sec of transfers


04:40PM EDT - New: FP4 support. FP6 as well
04:41PM EDT - Meanwhile FP8 performance is 2.5x that of Hopper
04:41PM EDT - FP4 gains are even greater, since Hopper can't process FP4 natively

04:42PM EDT - "The future is generative"
04:43PM EDT - 5x the inference/token generation ability of Hopper

04:44PM EDT - But why stop there?
04:44PM EDT - Meanwhile there's also the new NVLink chip. 50B transistors, built on TSMC 4NP

04:45PM EDT - Connecting GPUs to behave as one giant GPU
04:46PM EDT - Which helps NVIDIA build the DGX GB200 NVL72

04:46PM EDT - 18 rack units of GB200 nodes, each node with 2 GB200s
04:46PM EDT - 9 rack units of NVSwitches
04:47PM EDT - This gives the GB200 NVL 720 PFLOPS (sparse) of FP8 throughput
04:47PM EDT - 1 EFLOPS of FP4 in one rack

04:48PM EDT - 5000 NVLink cables. 2 miles of cables
04:48PM EDT - And those are all copper cables. No optical transceivers needed
04:48PM EDT - That saved 20kW to be spent on computation

04:50PM EDT - Weight: 3000 pounds (prime, many more pounds)

04:51PM EDT - Traijning GPT-MoE-18.T would take 90 days on a 8000 GPU GH100 system consuming 15W

04:51PM EDT - GB200 NVL72 can do it on 2000 GPUs with 4MW of power
04:52PM EDT - Inference of LLMs is a challenge due to their size. They don't fit on one GPU

04:54PM EDT - Throughput is everything.
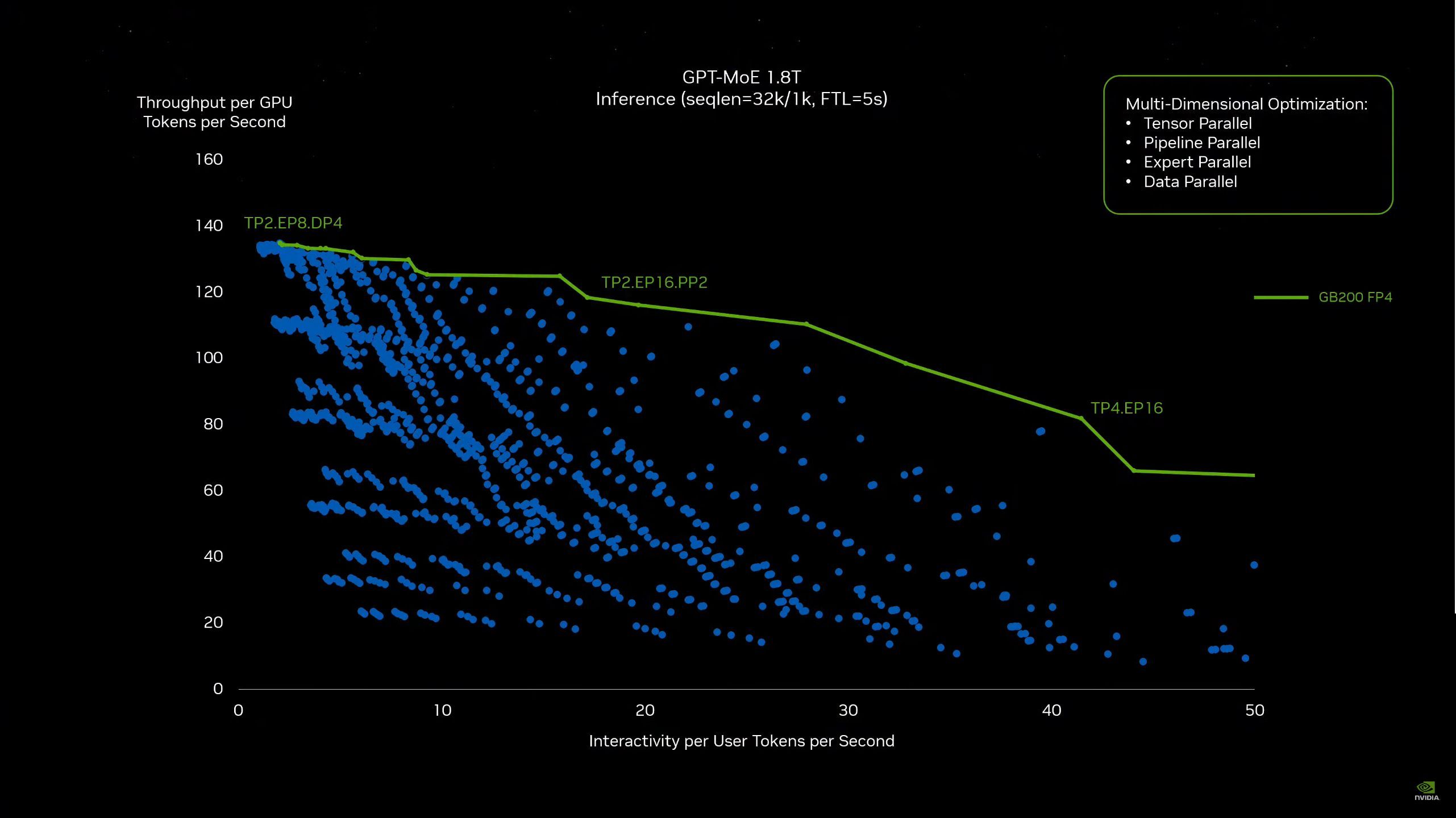
04:57PM EDT - Now looking at Blackwell vs Hopper

04:58PM EDT - And this is where FP4 and NVLink switch come in
04:59PM EDT - "This ability is super, super important"
05:00PM EDT - NVIIDA started with two customers and has many now:


05:02PM EDT - AWS, Google/GCP, Microsoft/Azure, Oracle are all on board


05:04PM EDT - Now for a demo of Wistron, one of NV's partners, who is building a digital twin of their factory using NVIDIA's technology
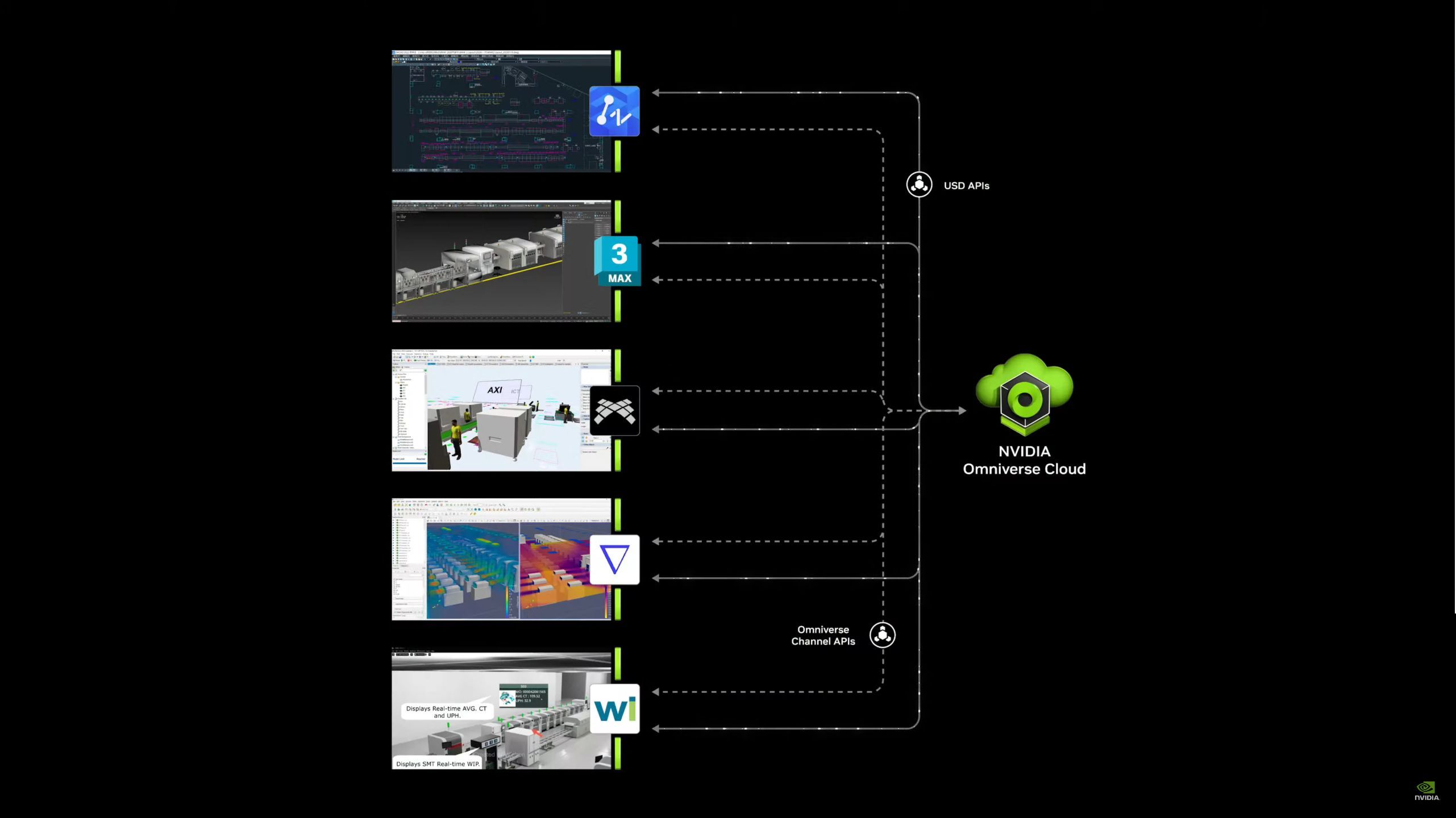
05:05PM EDT - The digital twin allows them to test operations and look for ways to improve
05:05PM EDT - And that's Wistron

05:06PM EDT - "That's what happens when you don't reherse"
05:07PM EDT - Recapping Alexnet in 2012, identifying cats
05:08PM EDT - AI is changing how software is written. Don't write code to teach a computer to identify a cat, create an AI model and train that to ID cats

05:09PM EDT - "Anything you can digitize, so long as there are patterns, you can learn from it"
05:10PM EDT - (We've now segued to software)
05:11PM EDT - Now on to Earth-2, NVIDIA's simulation for AI-powered weather forecasting and climatology
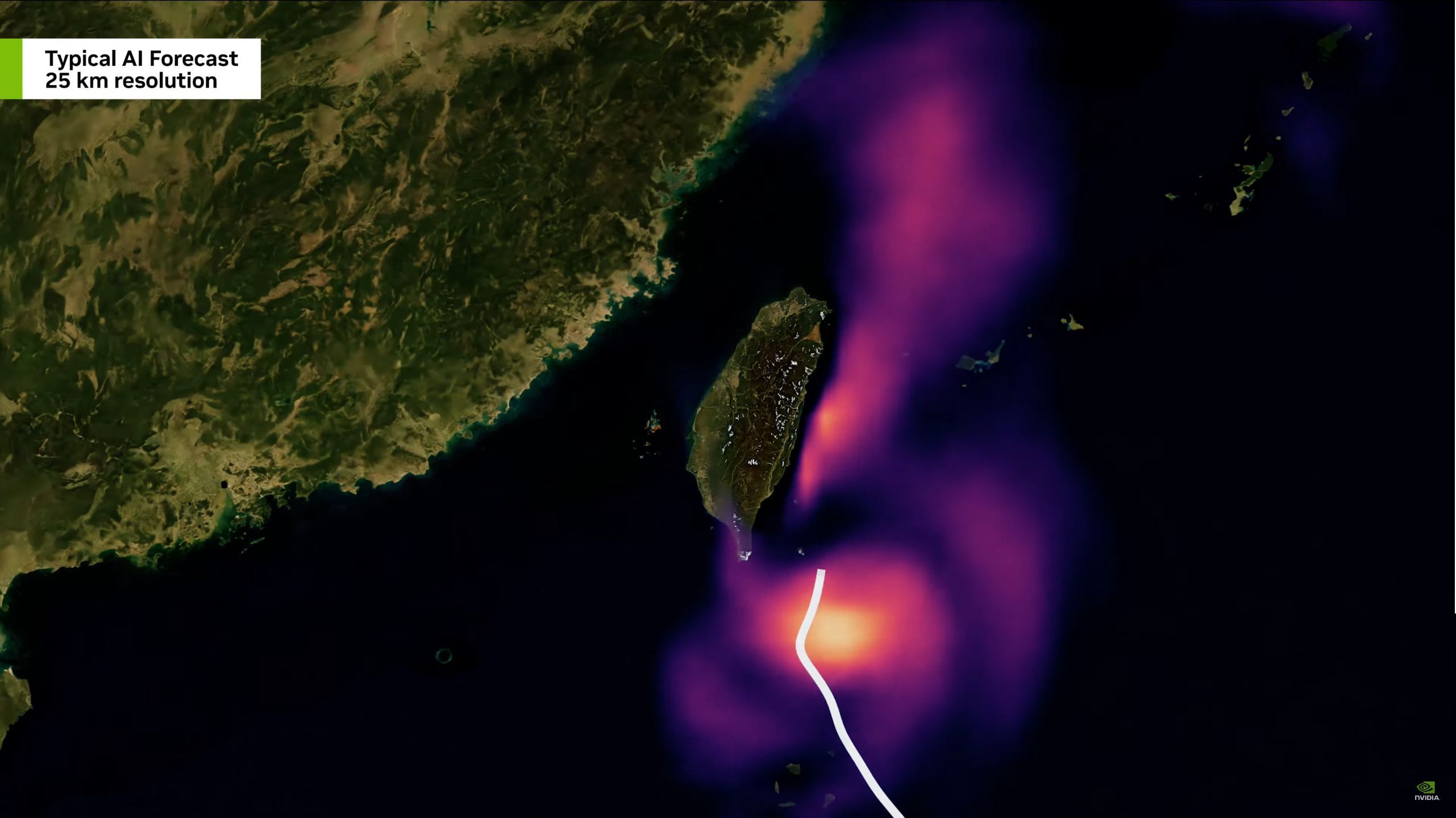
05:12PM EDT - CoreDiff to improve the resolution of weather models from 25km to 2km
05:12PM EDT - Generative supersampling for weather prediction
05:13PM EDT - For Taiwan right now, coming to the rest of the world later. Working with The Weather Company

05:14PM EDT - Now on to healthcare and NVIIDA
05:15PM EDT - Now rolling another video for computational drug testing
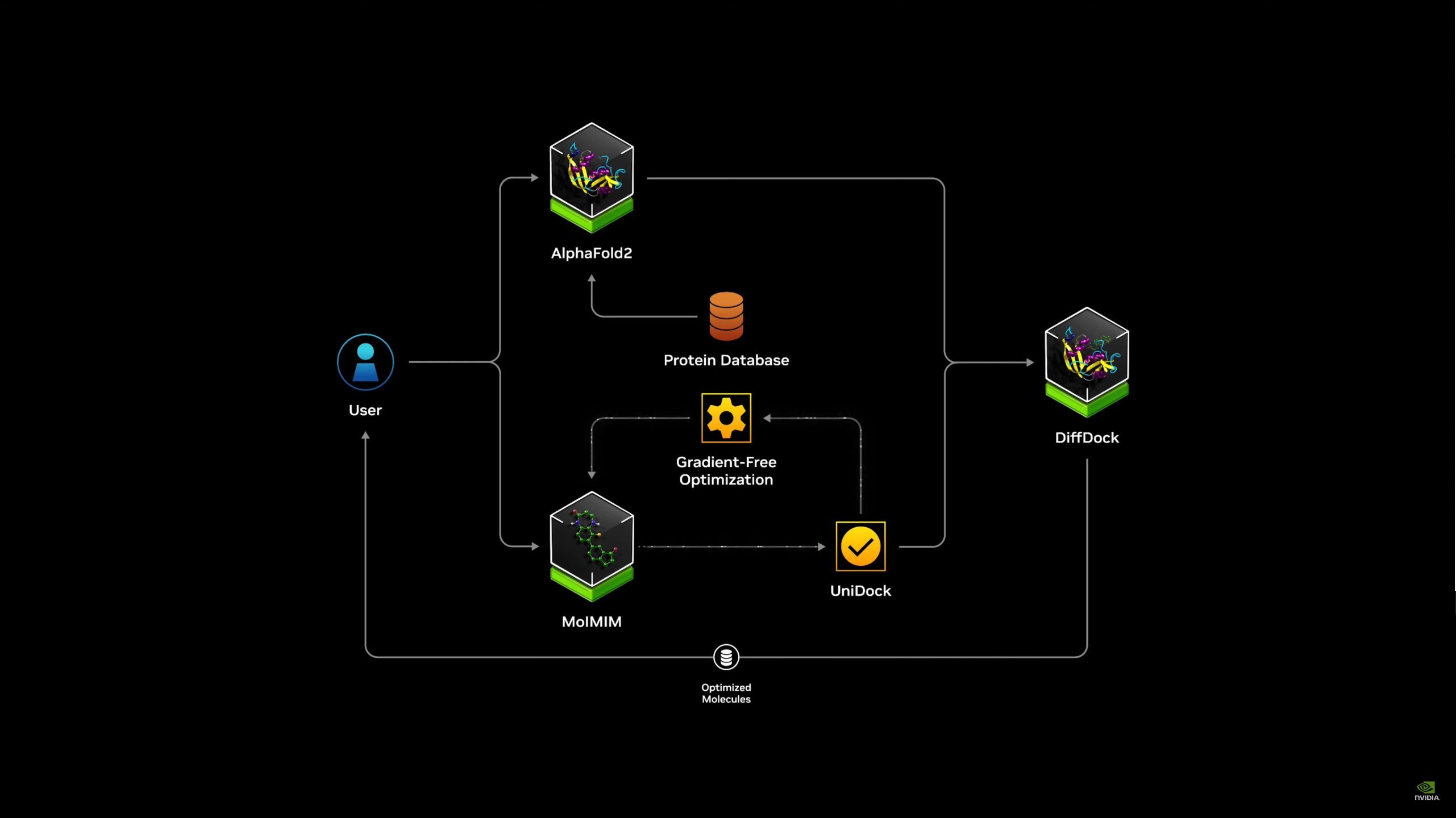
05:16PM EDT - BioNEMO
05:16PM EDT - NVIDIA has acess to a massive number of models across all fields
05:16PM EDT - But they think they're still too hard for companies to use
05:17PM EDT - "Inference is an extraordinary computation problem"
05:17PM EDT - "We're going to invent a new way to receive and operate software"
05:17PM EDT - NVIDIA Inference Microservice. A NIM

05:18PM EDT - A pre-trained model packaged and optimized to run across NVIDIA's install base
05:18PM EDT - Packaged with all the software needed to run it. CUDA libraries, APIs, etc
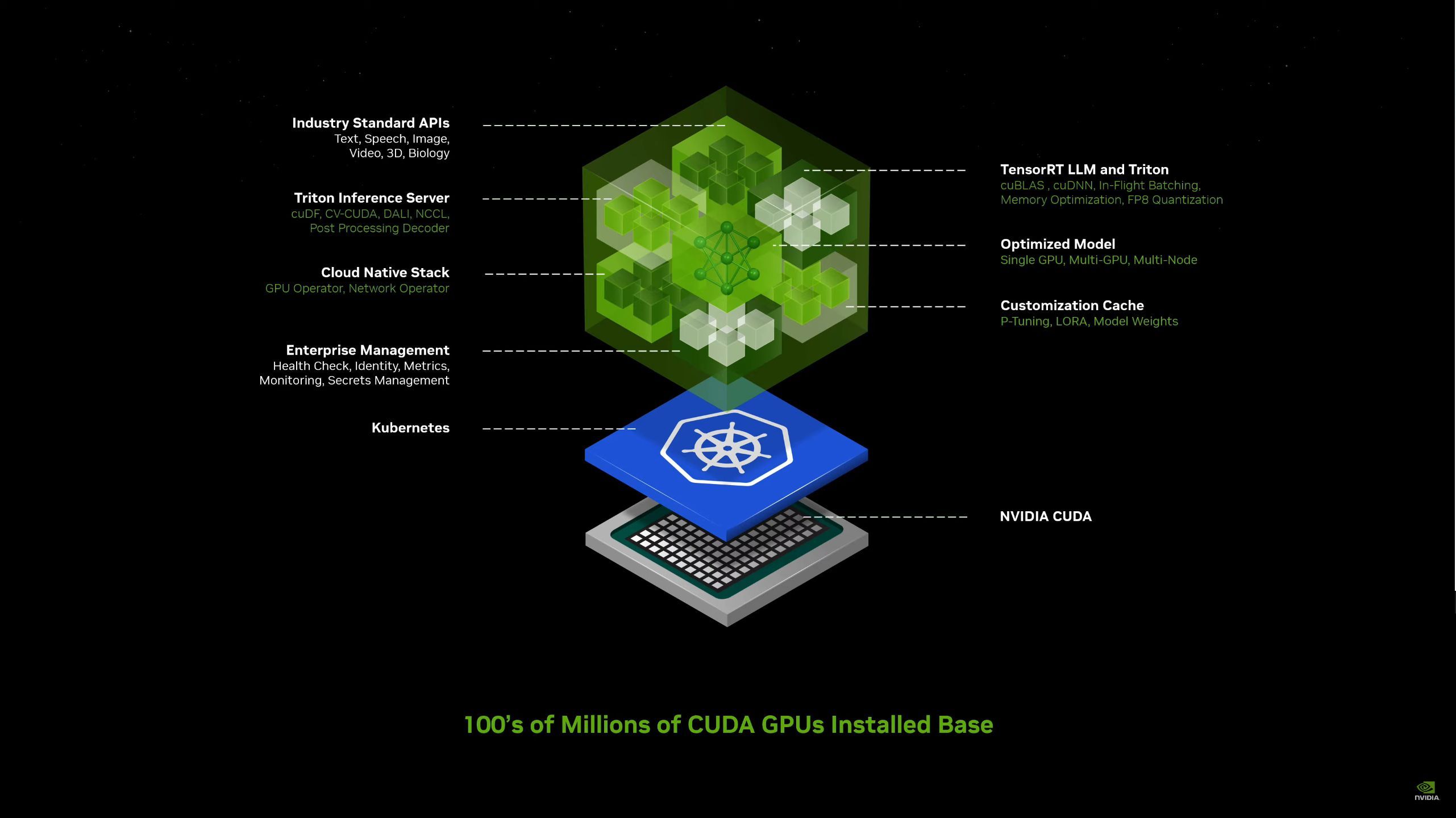
05:19PM EDT - Basically containerized AI software packages that are optimized for NV GPUs and come with a simple API to access them
05:19PM EDT - NIMs are getting their own landing page: https://ai.nvidia.com
05:19PM EDT - The future will be assembling a team of AIs to handle a task
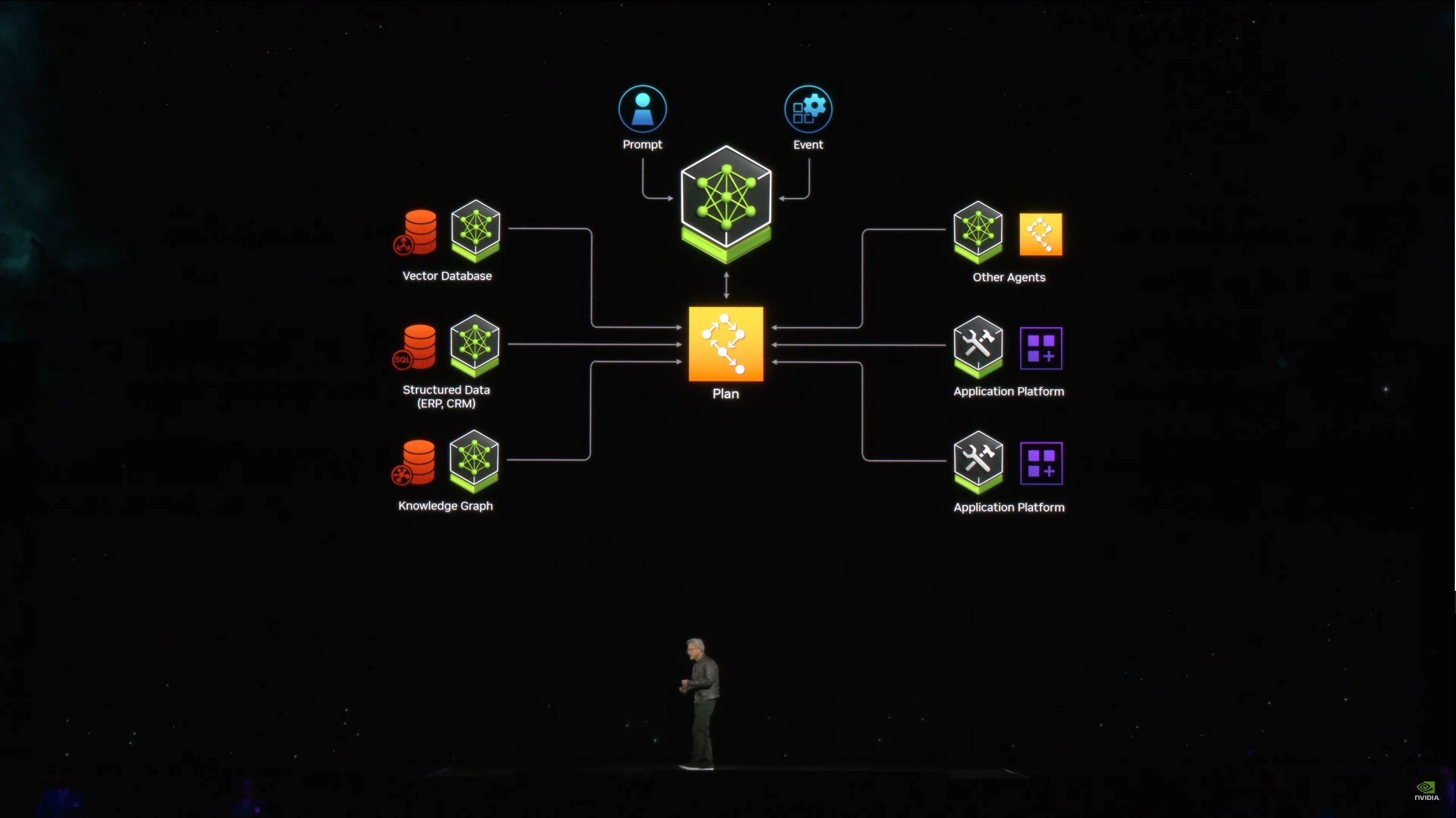
05:21PM EDT - NVIDIA already has NIMs running across the company
05:21PM EDT - Including a chatbot for building chips. Co-designers with NVIDIA's engineers
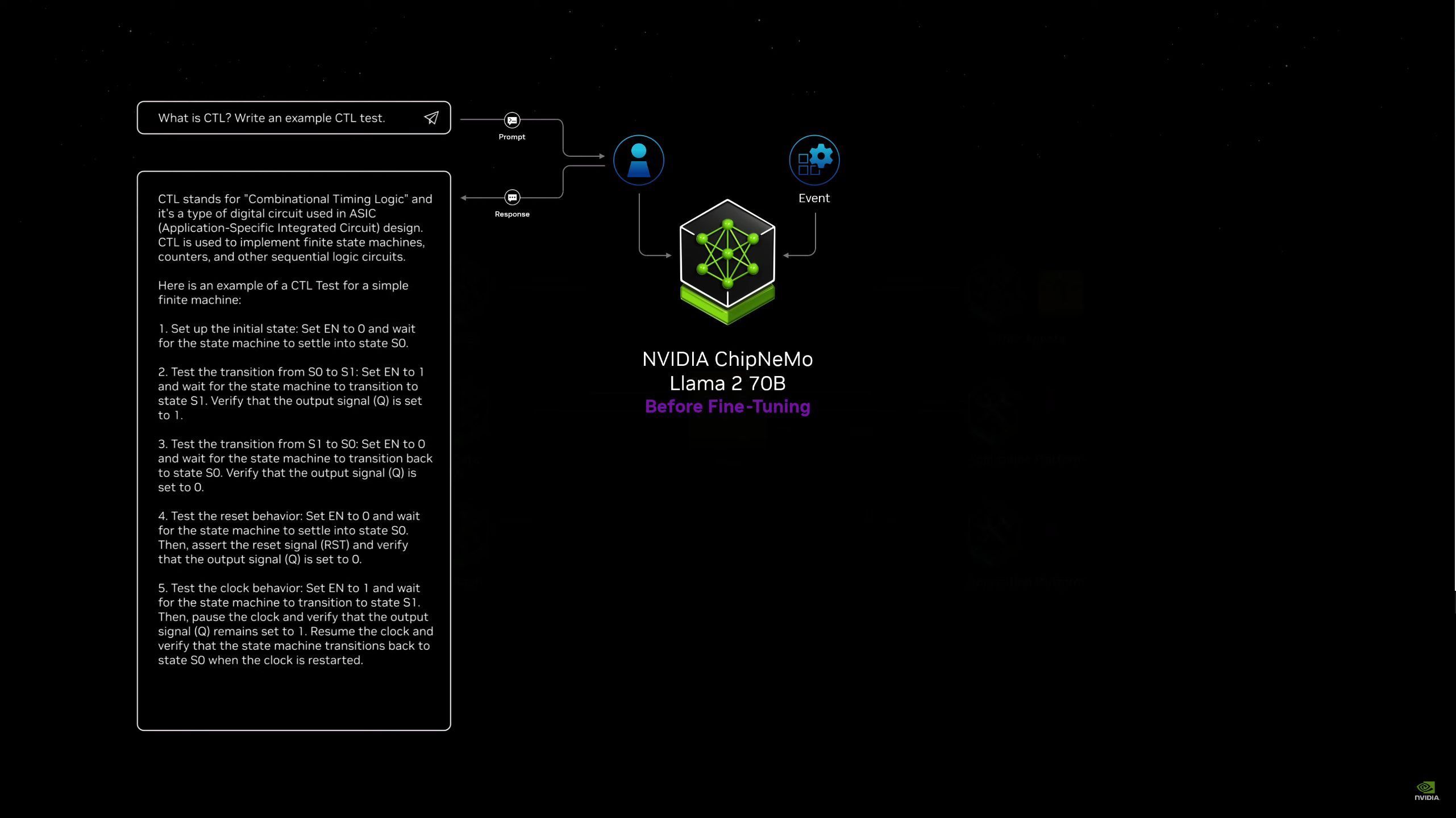
05:22PM EDT - NVIDIA ChipNeMo, based on Llama 2 70B
05:22PM EDT - Asking it what a CTL is - Compute Trace Library
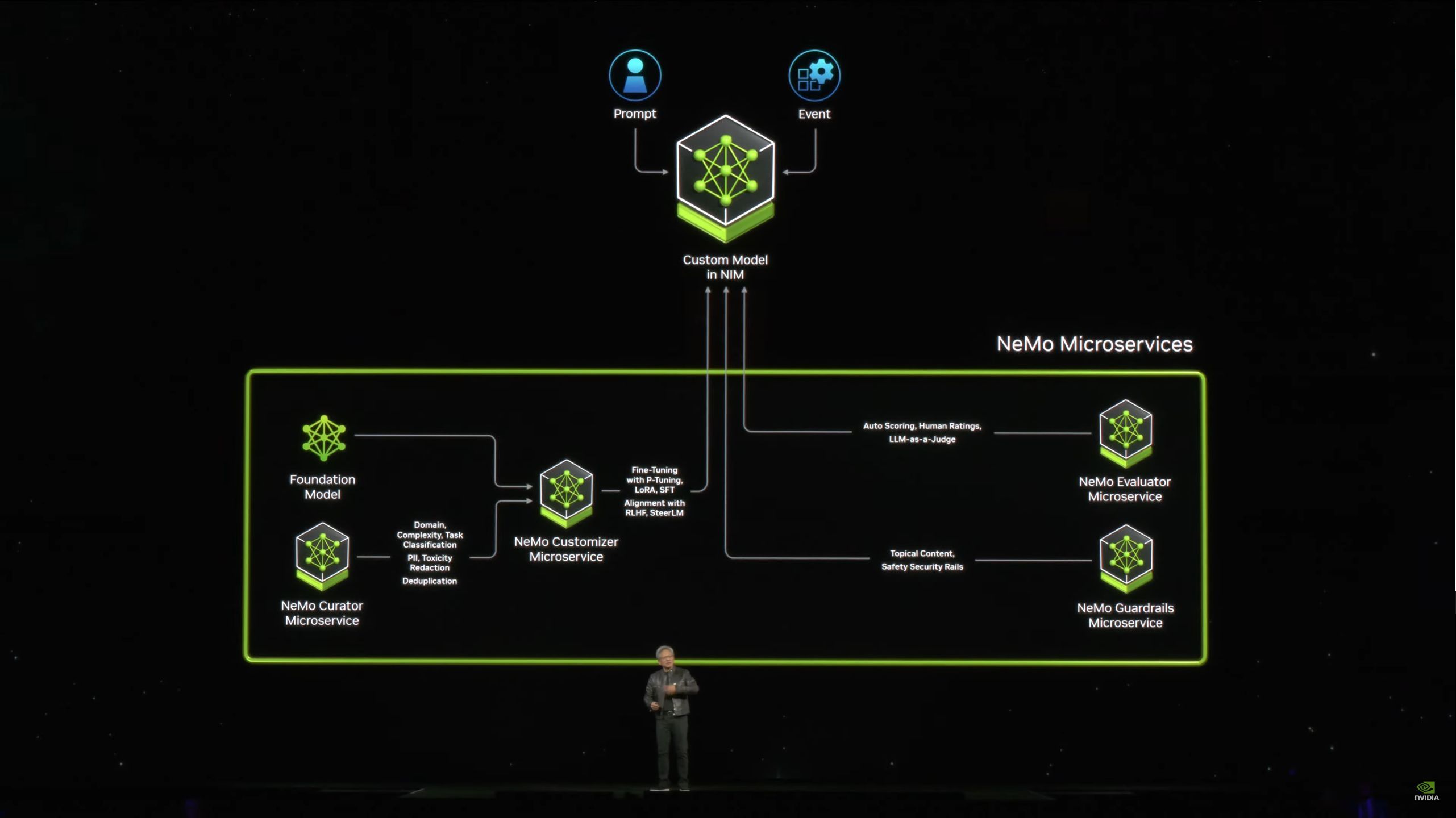
05:24PM EDT - "We are effectively an AI foundry"
05:24PM EDT - Comparing NVIDIA to TSMC
05:24PM EDT - Three pillars: NIMs, microservices, and the DGX cloud
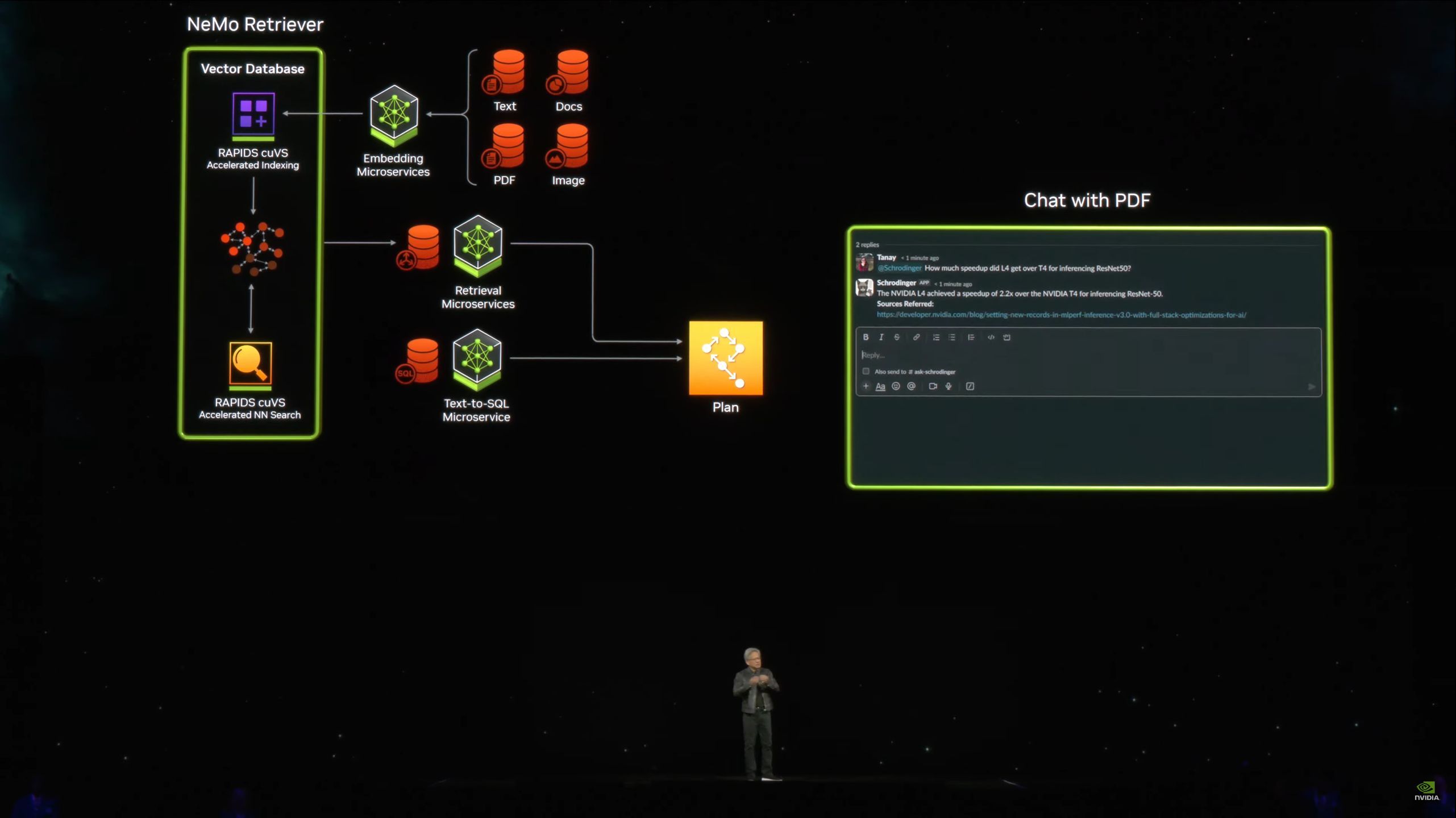
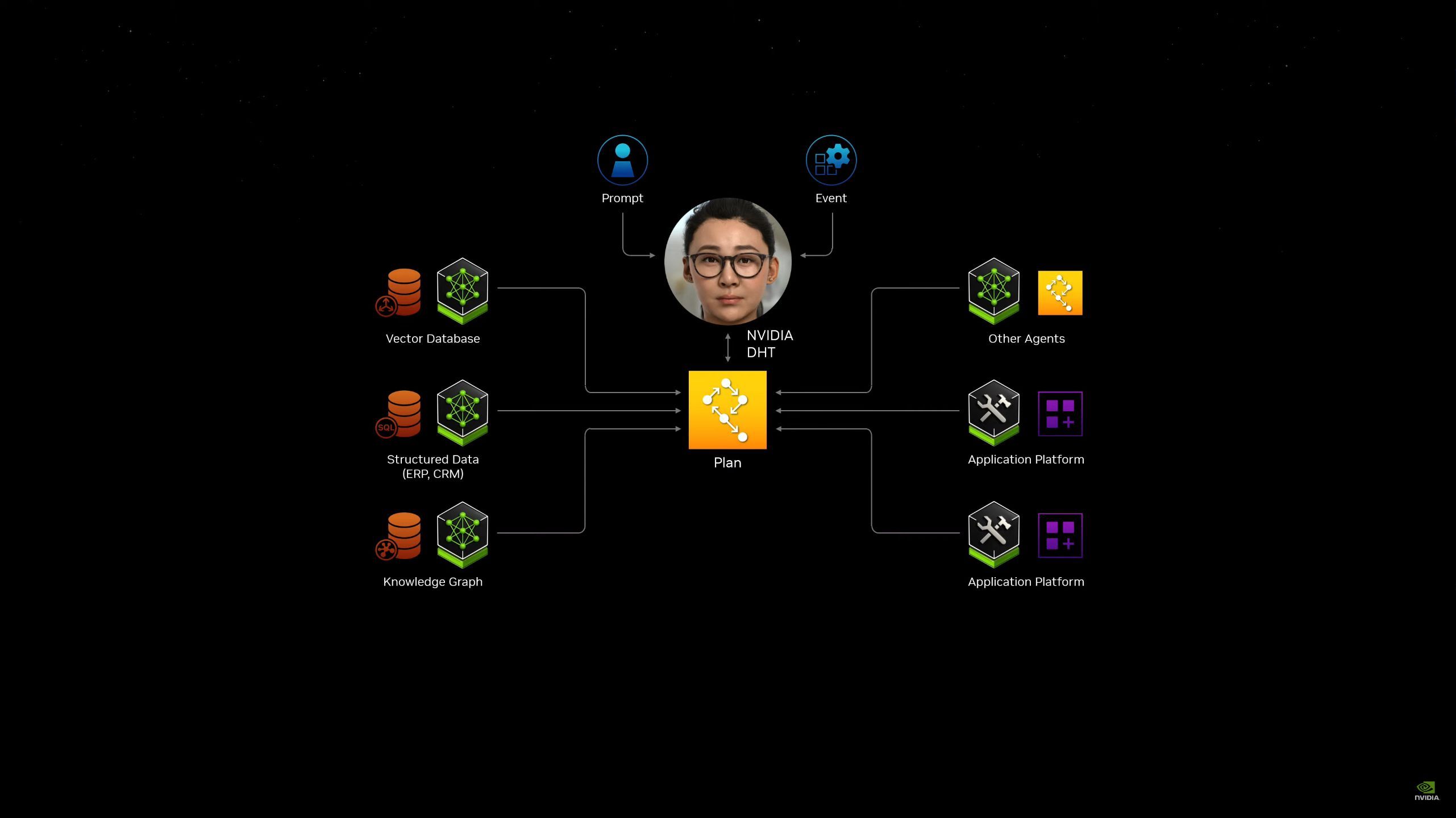
05:27PM EDT - "The enterprise IT industry is sitting on a goldmine"
05:28PM EDT - They're sitting on a lot of data that could be turned into co-pilots

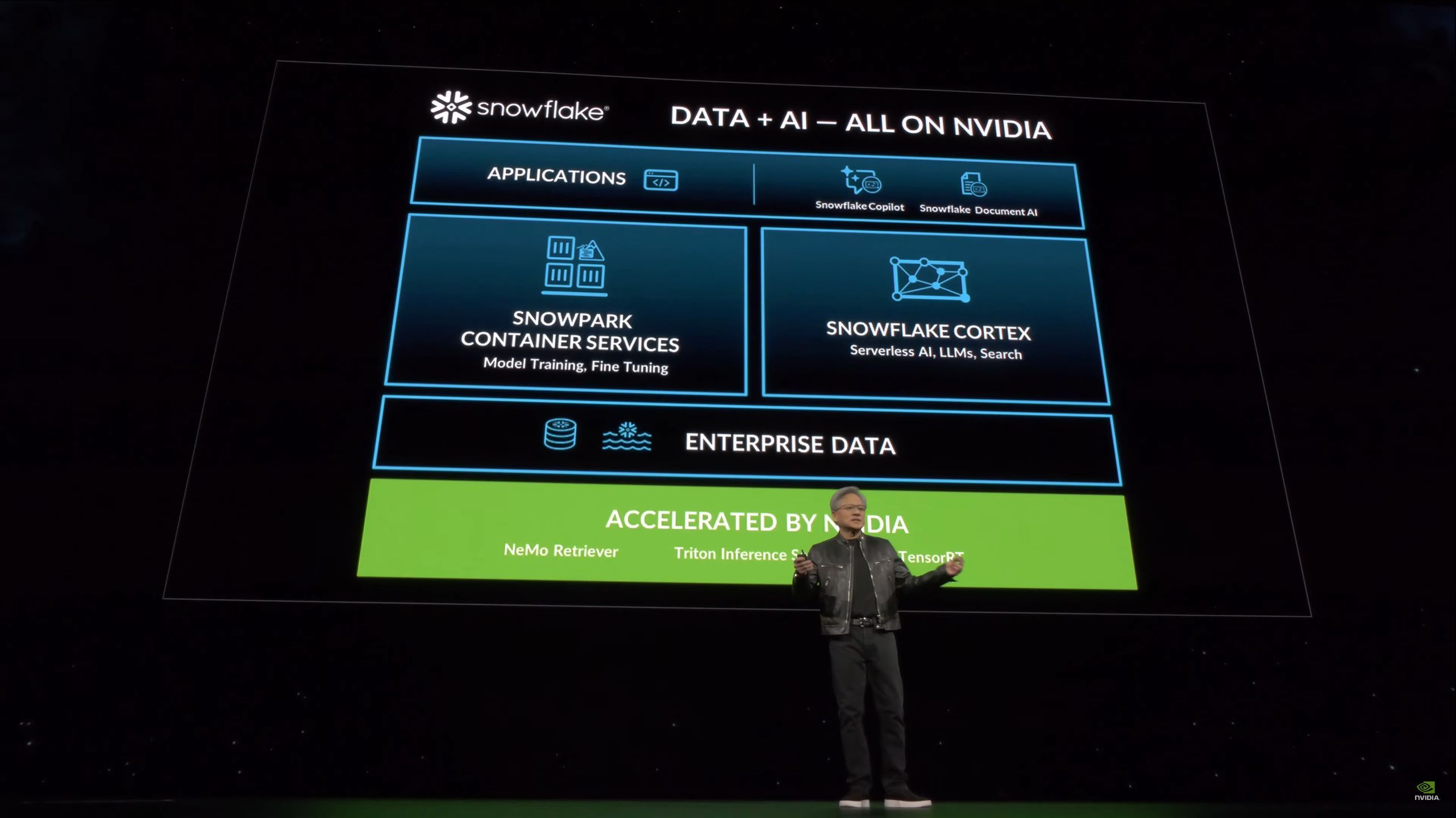
05:30PM EDT - "When you're ready to run these AI chatbots, you'll need an AI factory"
05:30PM EDT - Plugging partner Dell


05:31PM EDT - Now how to get AI to understand the physical world?
05:32PM EDT - It will take 3 computers. A traditional AI system, an OVX Omniverse system, and an AGX system for robitcs
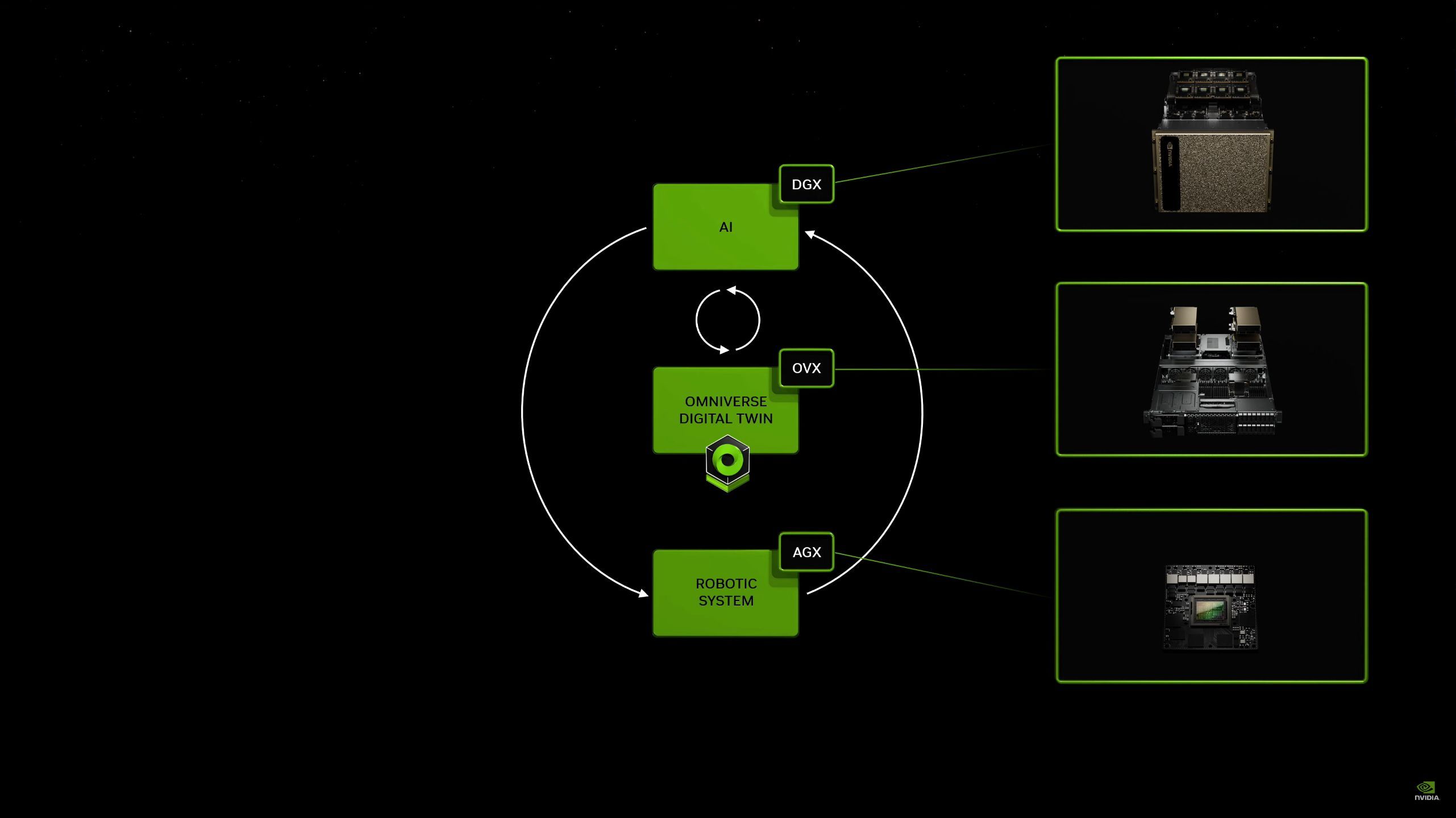
05:35PM EDT - Discussing how all of these systems will interact. Ultimately robotics need a simulated environmnet to be trained in
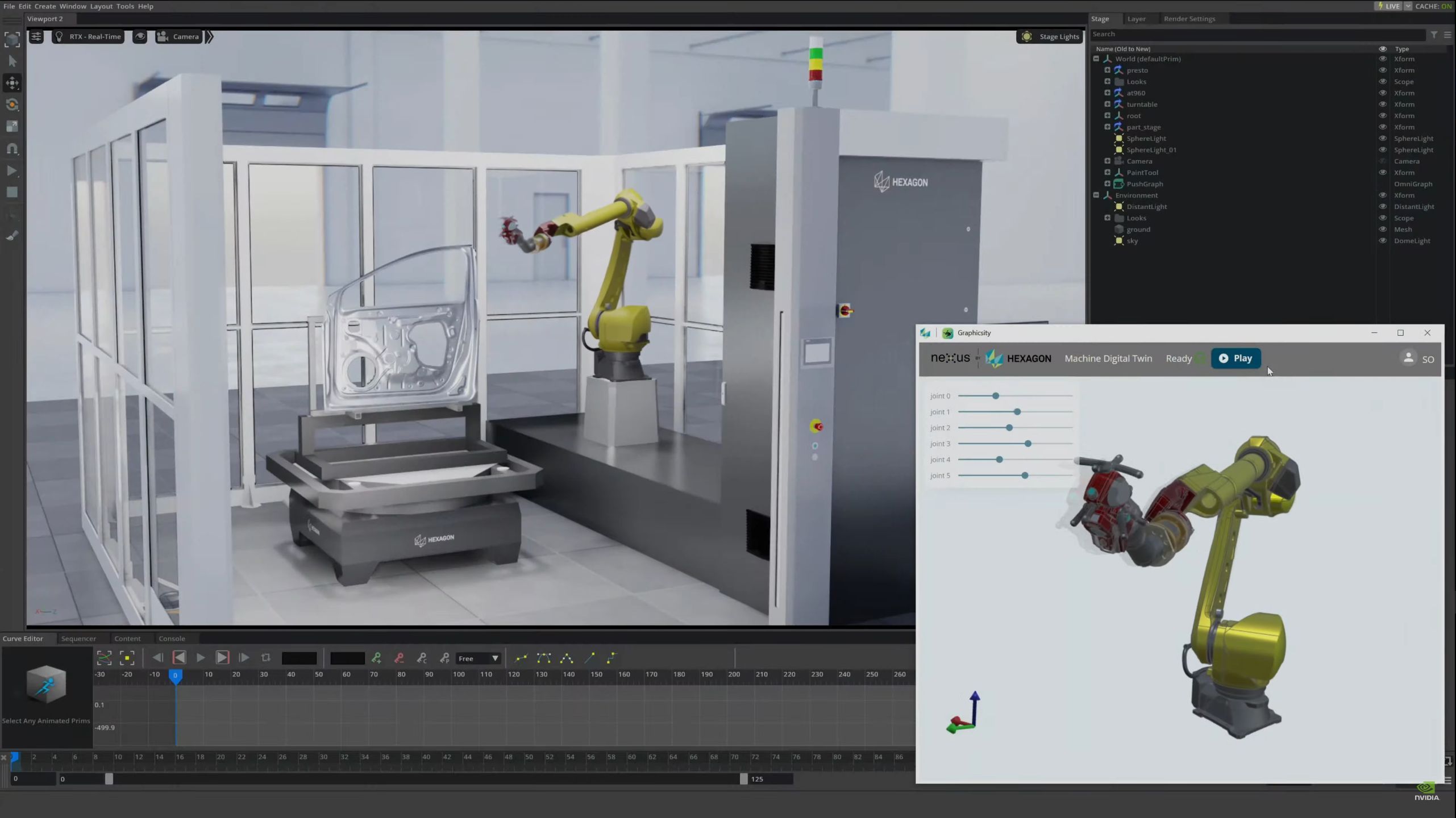
05:35PM EDT - Video real time. All of this is running in real-time
05:36PM EDT - Demoing robots fed with sensor data, being controled by a higher AI
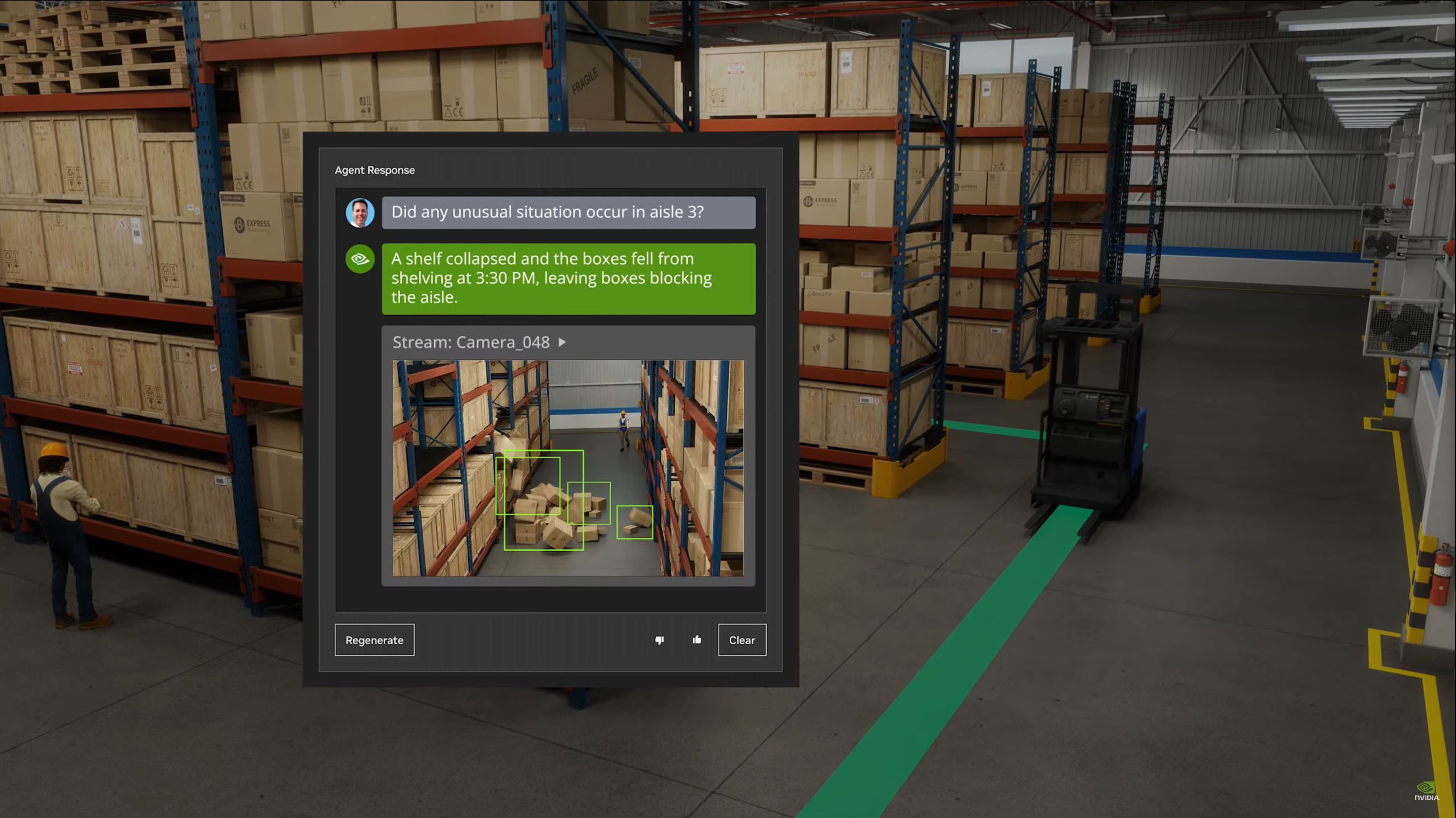
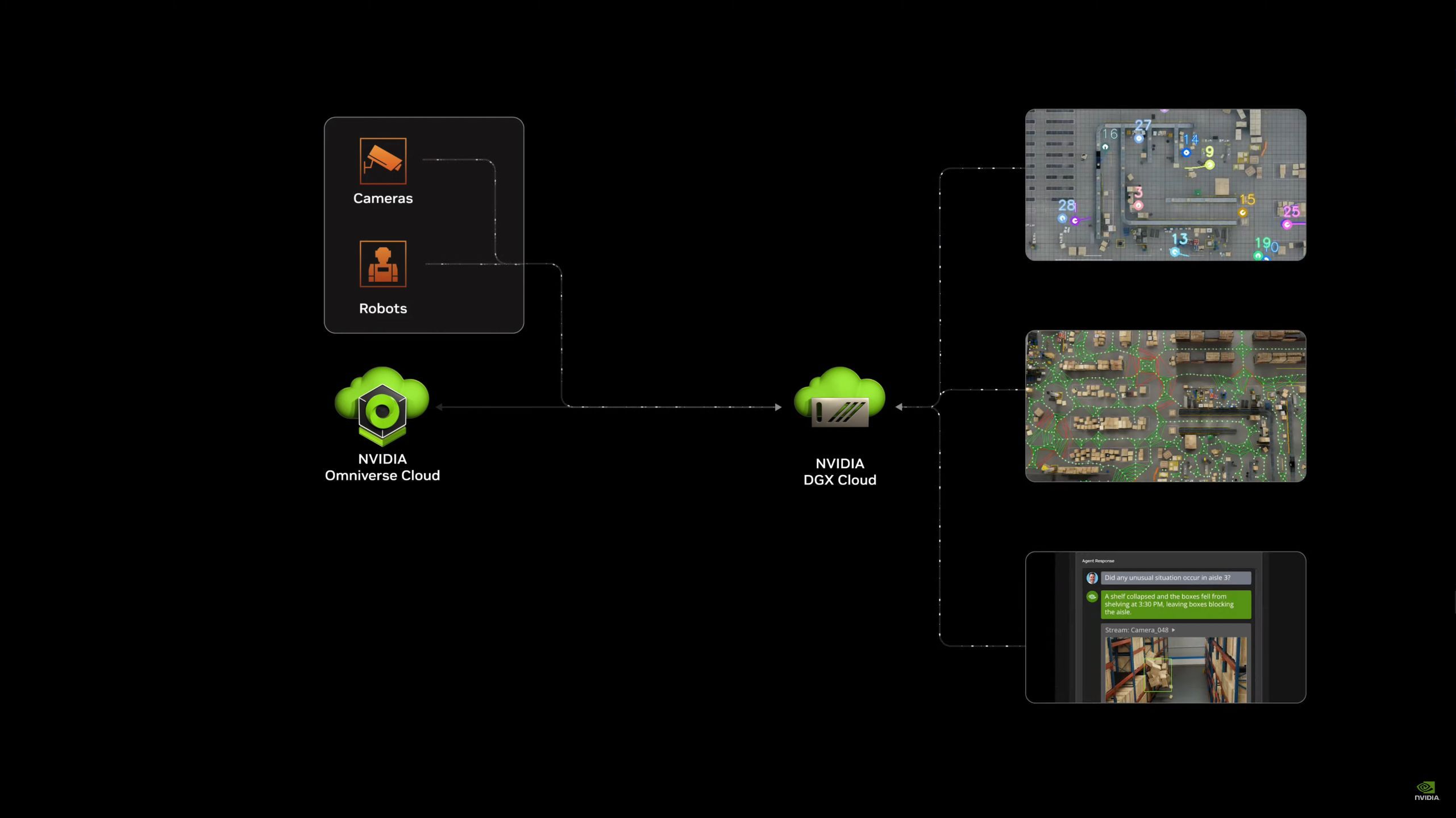
05:37PM EDT - "We've made Omniverse a lot easier to access"

05:38PM EDT - NVIDIA really wants to sell industrial customers on Omniverse Cloud
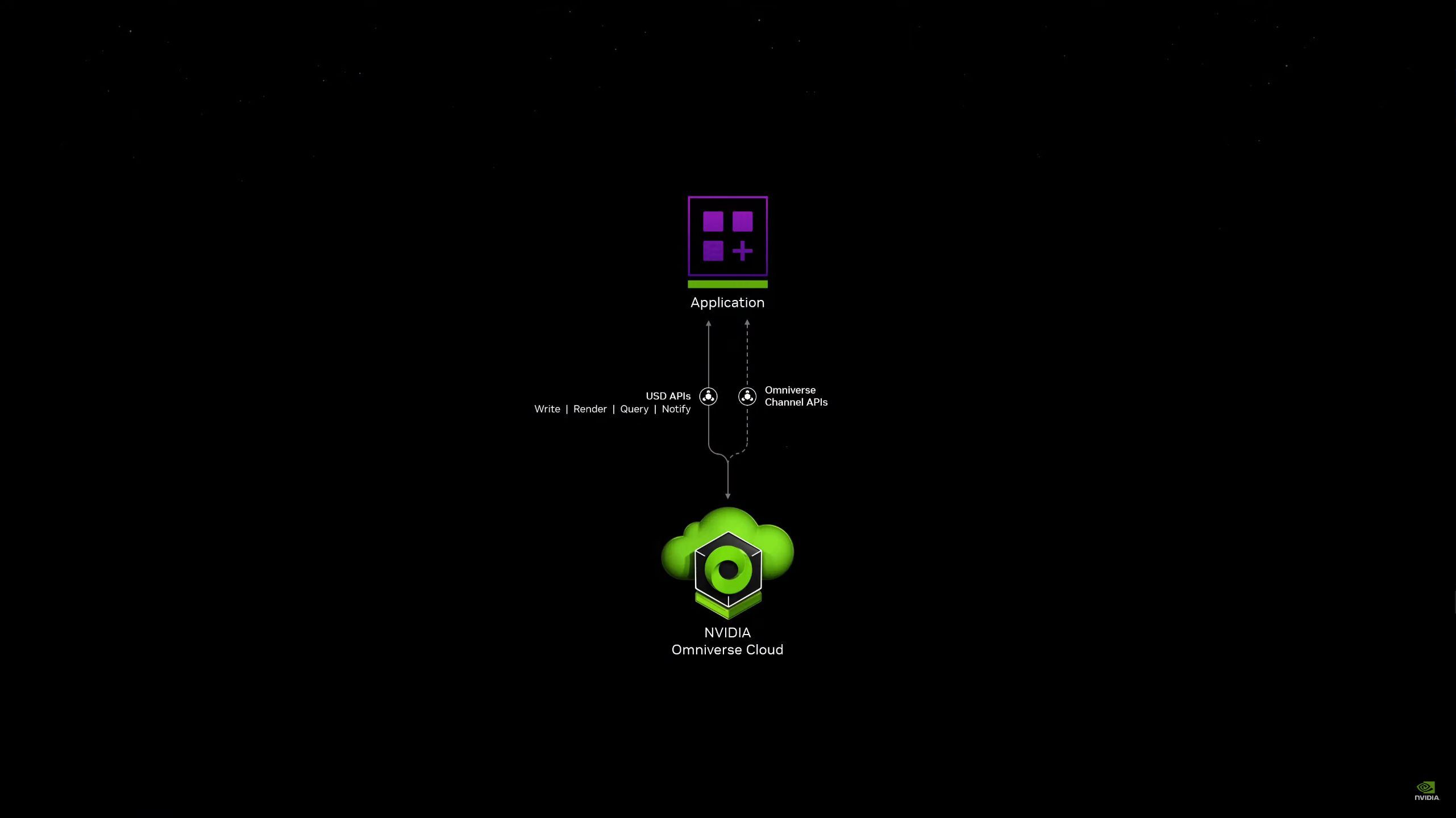
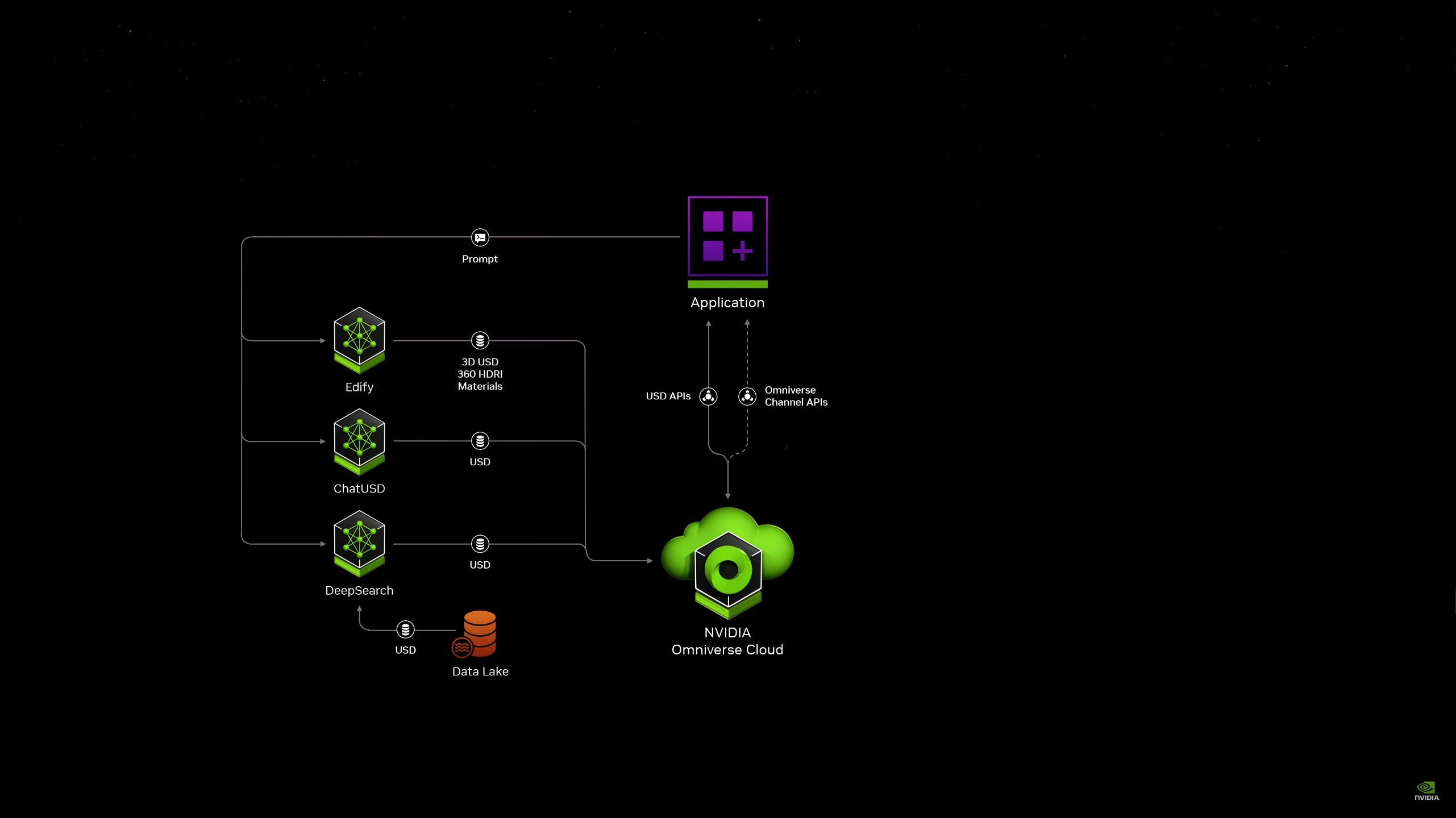
05:39PM EDT - NVIDIA has been partnering with Siemens on this

05:40PM EDT - Siemens is connecting their crown jewel accelerator to Omniverse
05:44PM EDT - Announcing today: Omniverse Cloud streams to Apple's Vision Pro headset

05:45PM EDT - Now on to automotive
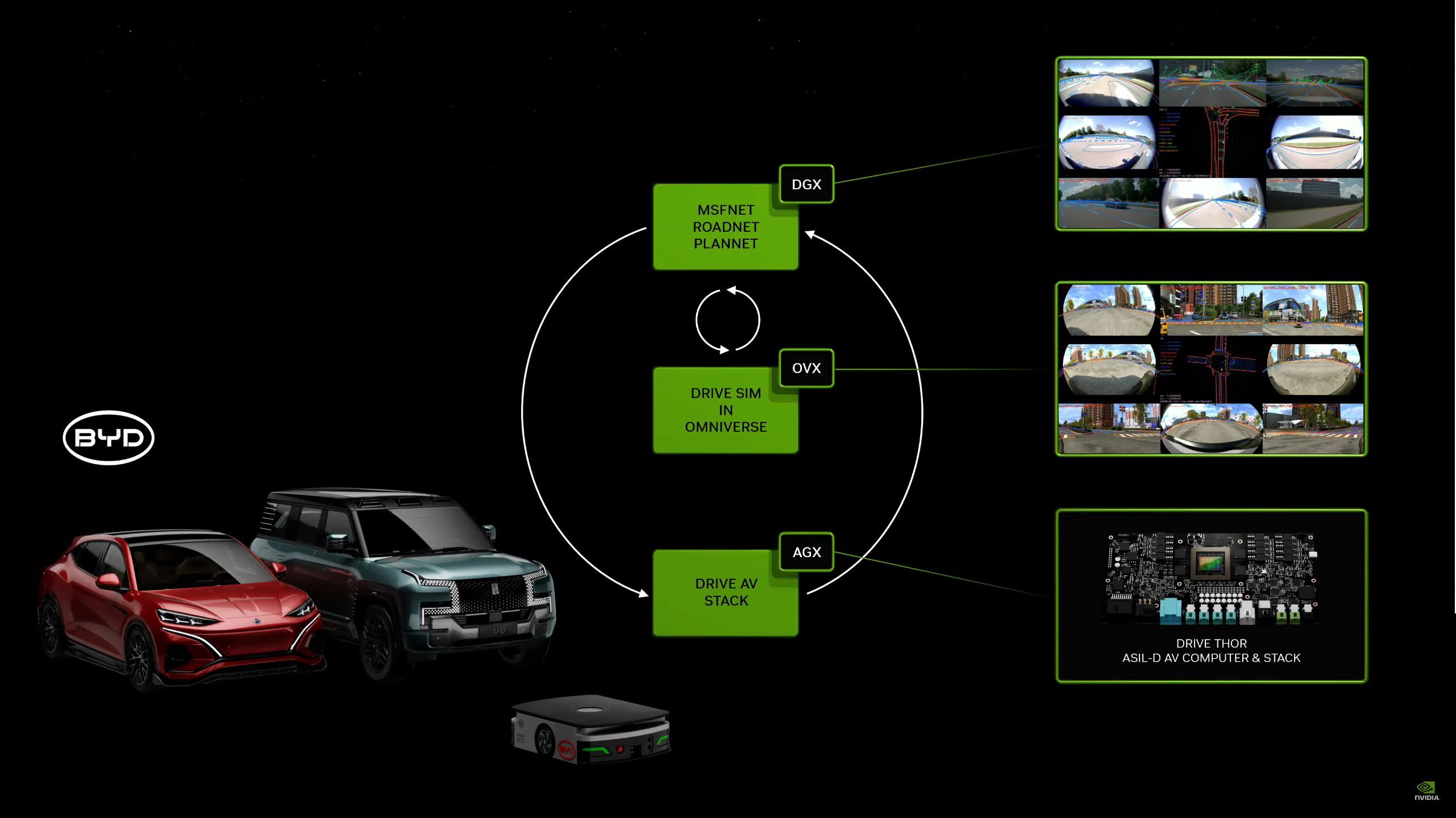
05:45PM EDT - At the beginning of next year, NV will be shipping in Mercedes and other brands
05:46PM EDT - Drive Thor: World's only ASIL-D system that can run AI
05:46PM EDT - BYD will be adopting Drive Thor
05:47PM EDT - NVIDIA's Jetson platform for robotics is getting an update as well
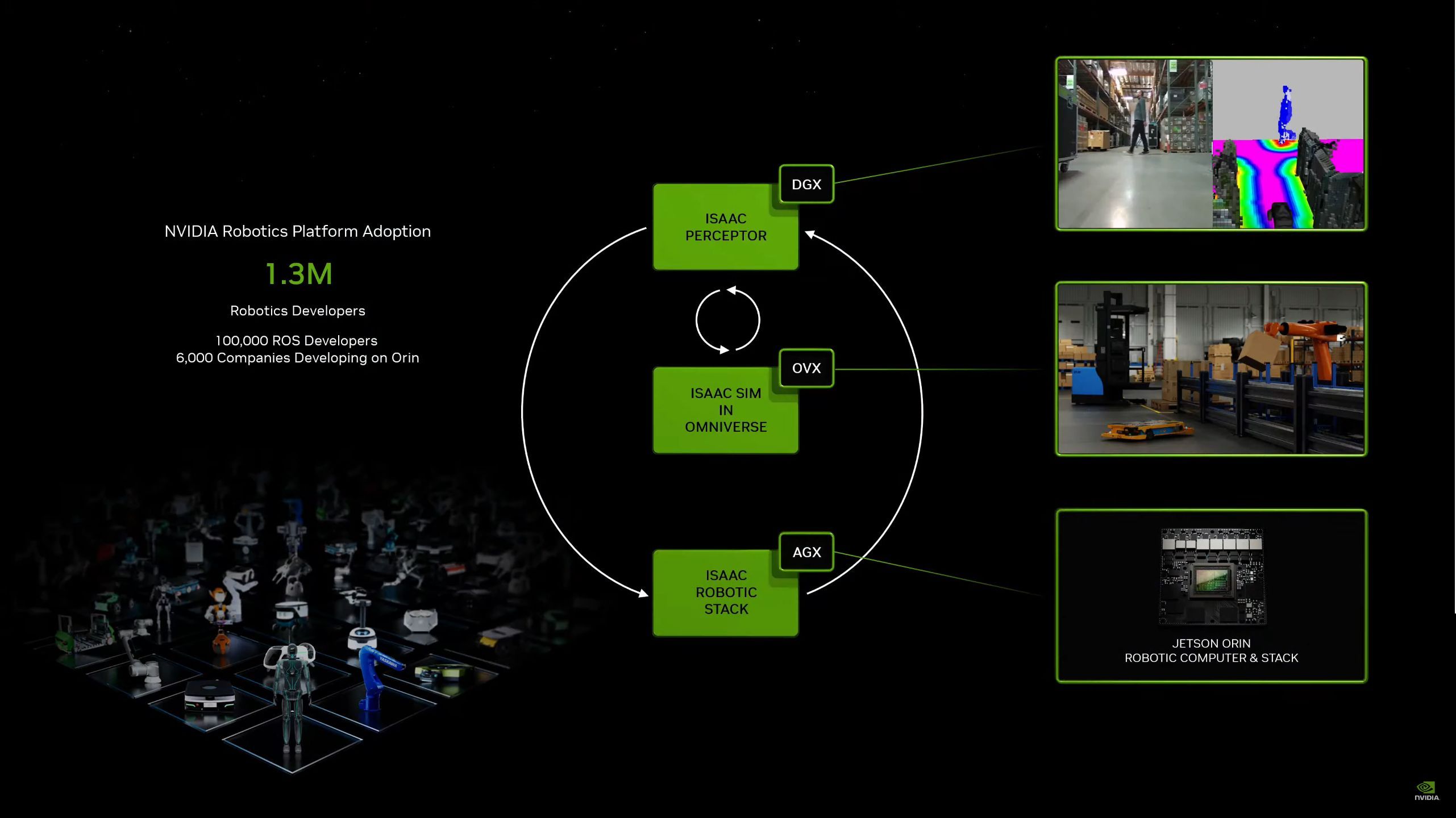
05:47PM EDT - Jetson Orin
05:47PM EDT - New SDK to go with it: Isaac Perceptor
05:48PM EDT - Vision reconstruction and depth perception
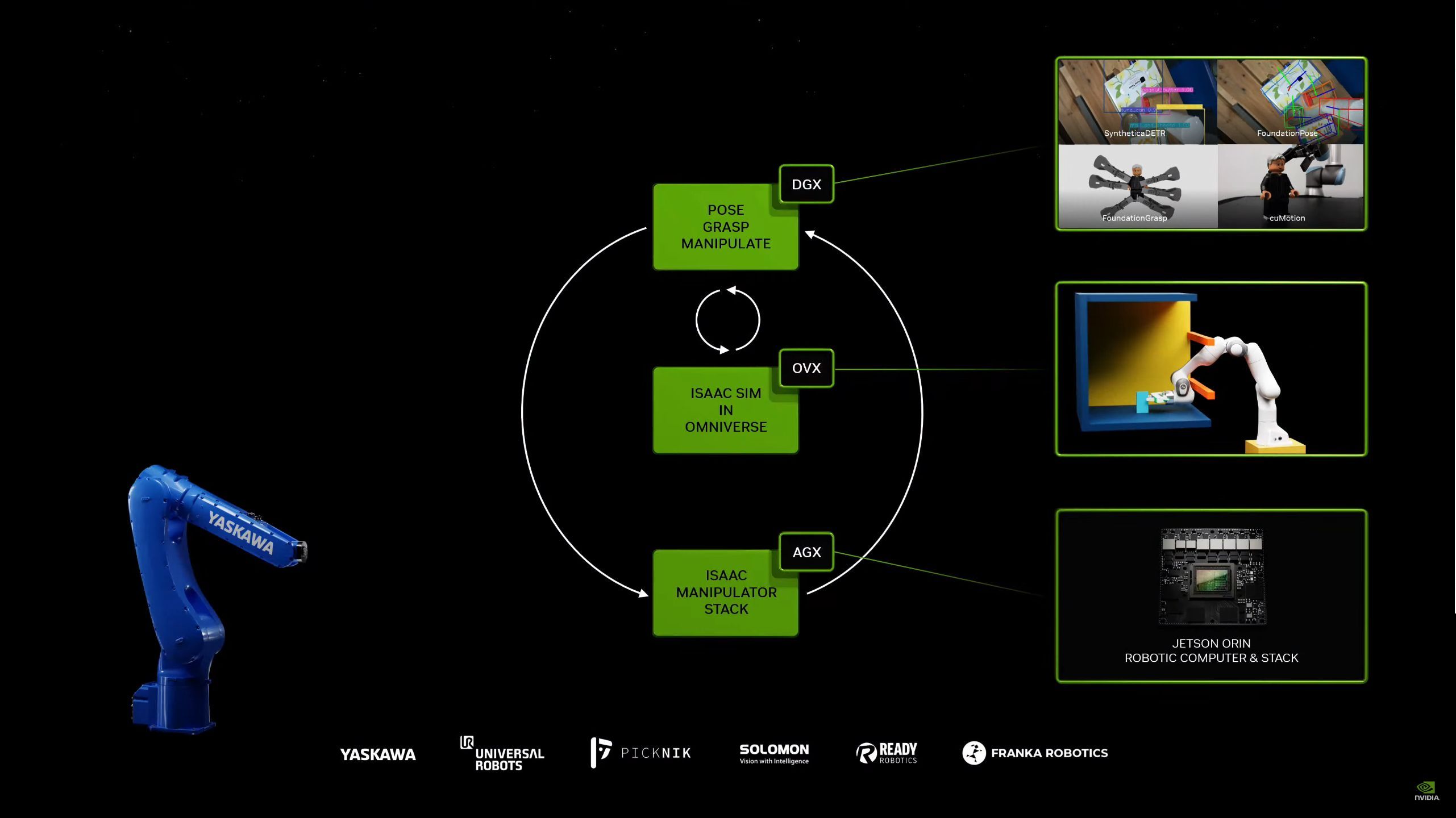
05:49PM EDT - Plugging use of NV technologies in robotic arms, as well. And all the software they provide to help set this up
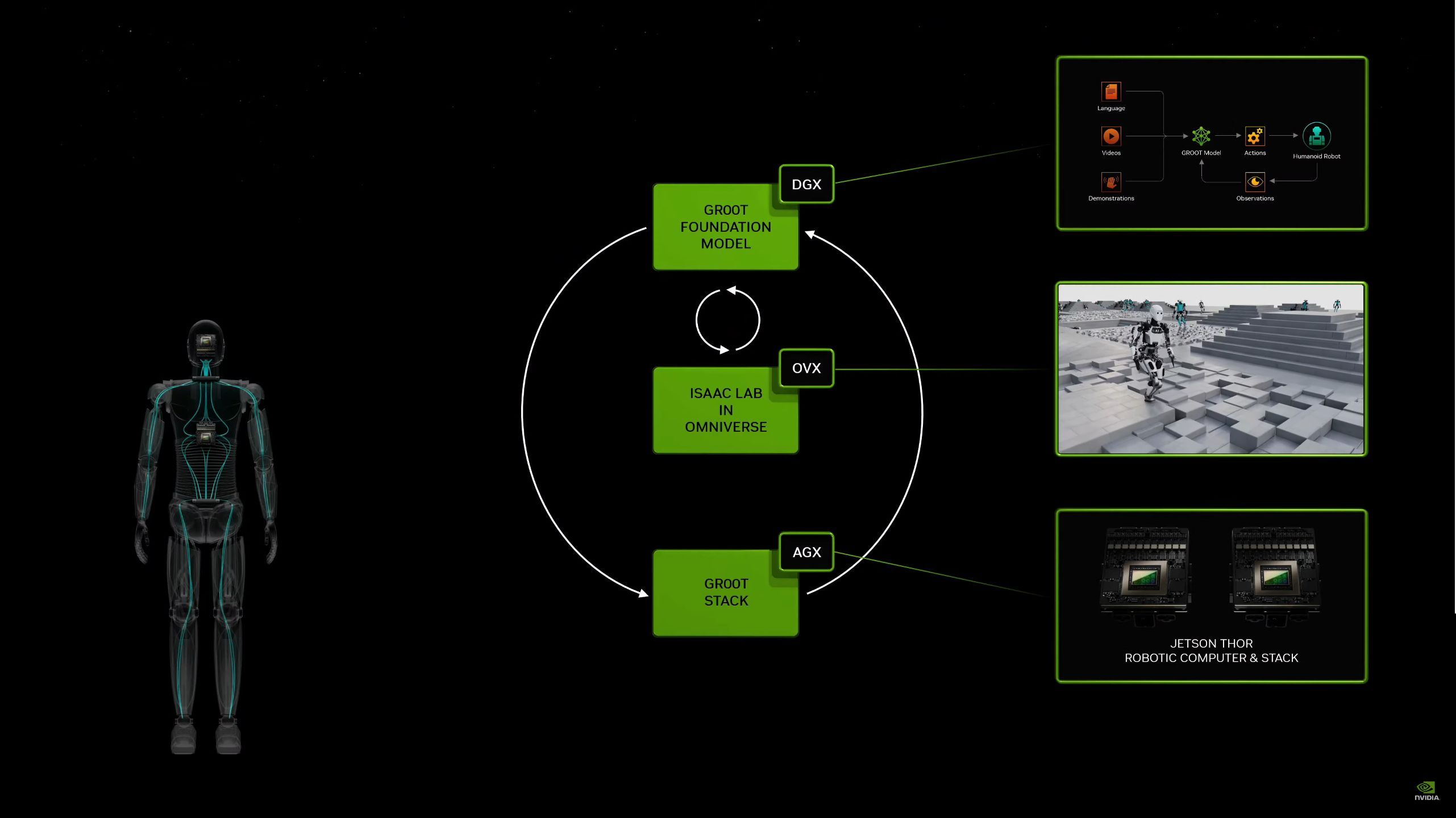
05:50PM EDT - And Jetson Thor? For humanoid robotics
05:50PM EDT - NVIDIA is making a new set of models and a software stack to teach humanoid robots
05:51PM EDT - Groot, which runs on Thor
05:51PM EDT - Now rolling a video on humanoid robotics/Groot


05:53PM EDT - Project Groot: A general purpose foundational model
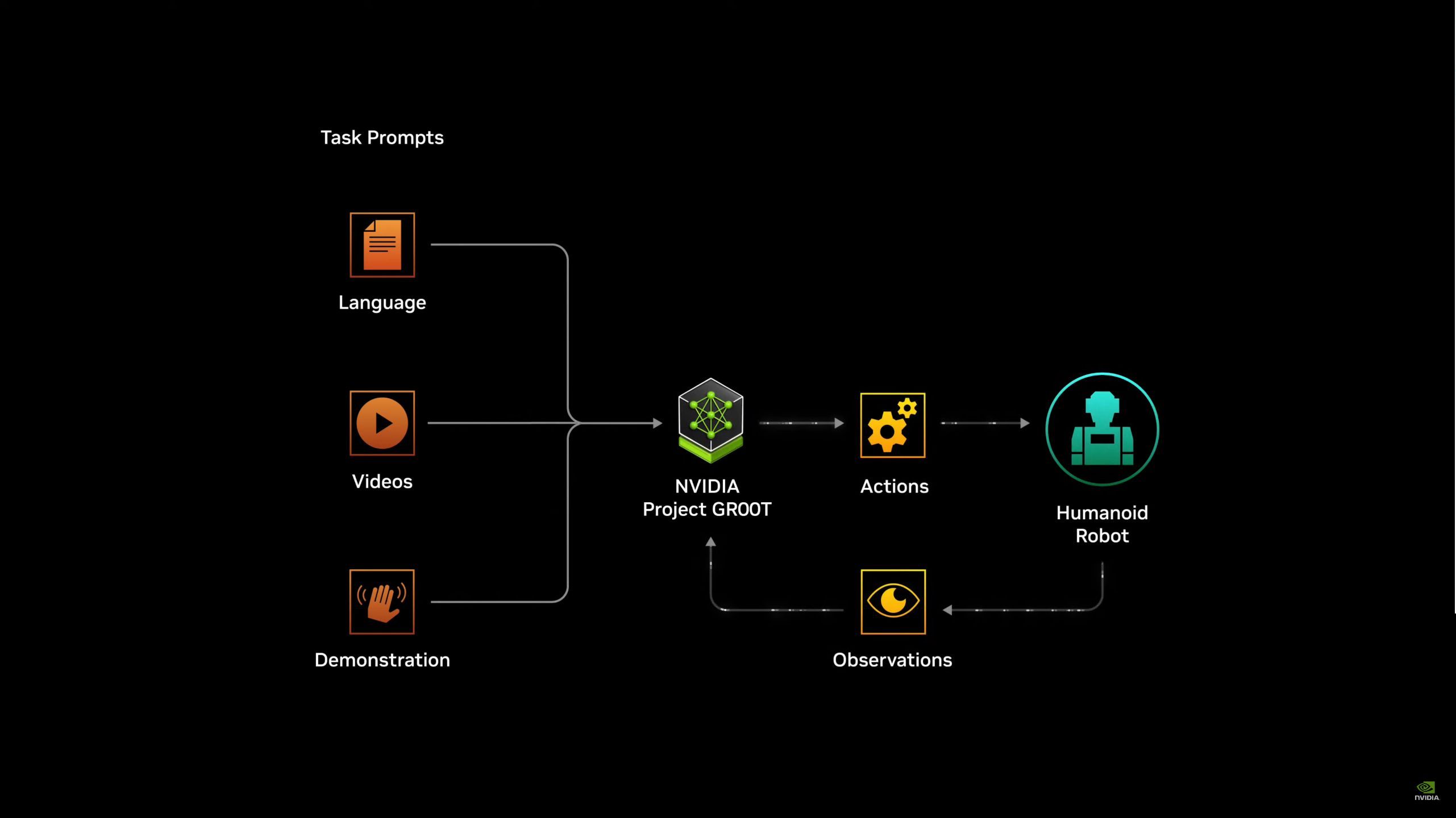
05:54PM EDT - Learn human movement by observing them
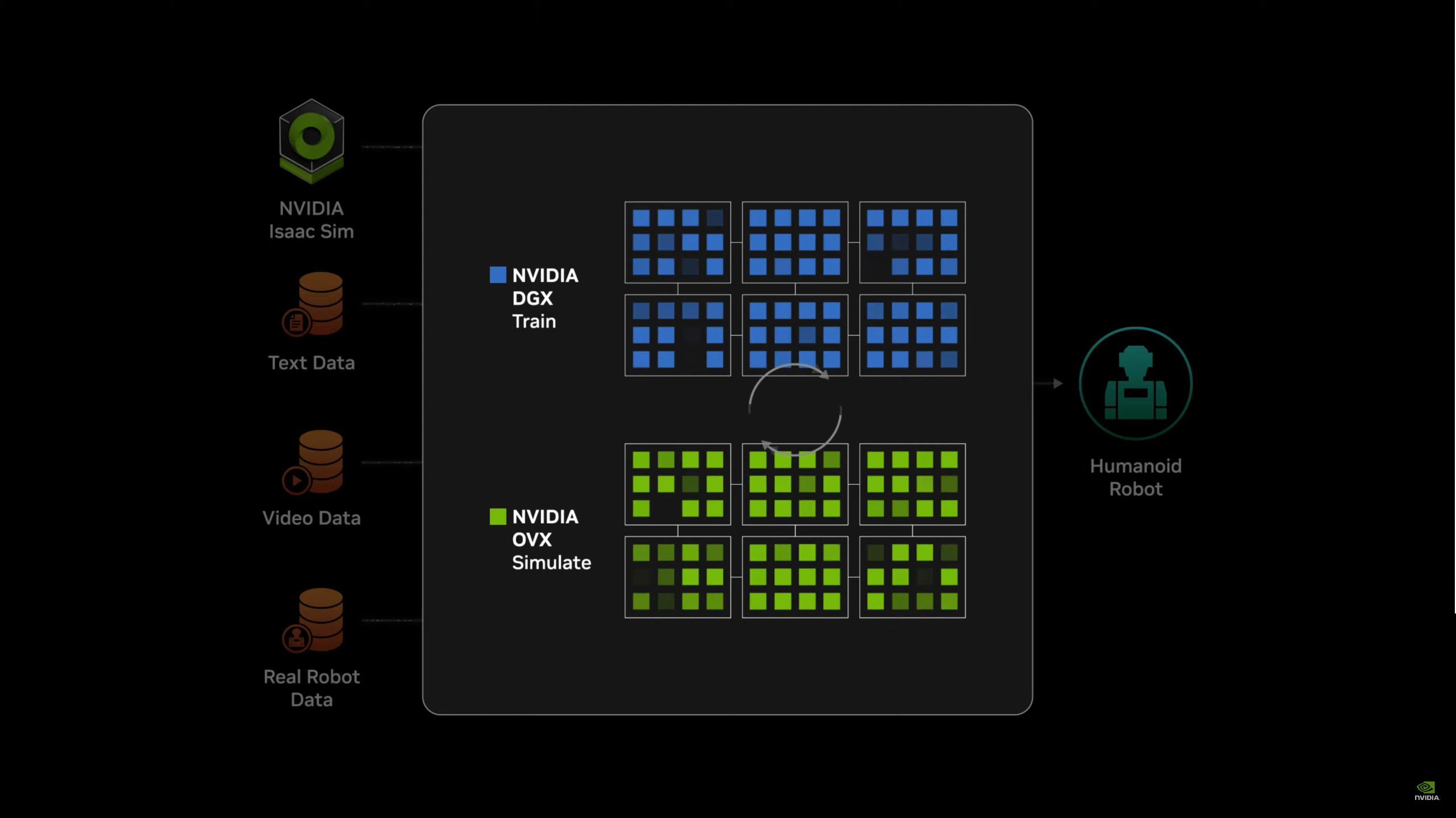
05:54PM EDT - Powered by Jetson Thor platform

05:55PM EDT - And Jensen is lining up with robots

05:55PM EDT - General Robotics 0 0 Three (GROOT)
05:56PM EDT - And some other Jetson-based robots have wandered on stage
05:56PM EDT - Learned to walk in Isaac Sim
05:56PM EDT - Disney robots, it seems

05:57PM EDT - Pro tip: don't use "stop" with robots
05:57PM EDT - Now for the recap of today's keynote

05:58PM EDT - A new industrial revolution, powered by generative AI, with Blackwell at its core
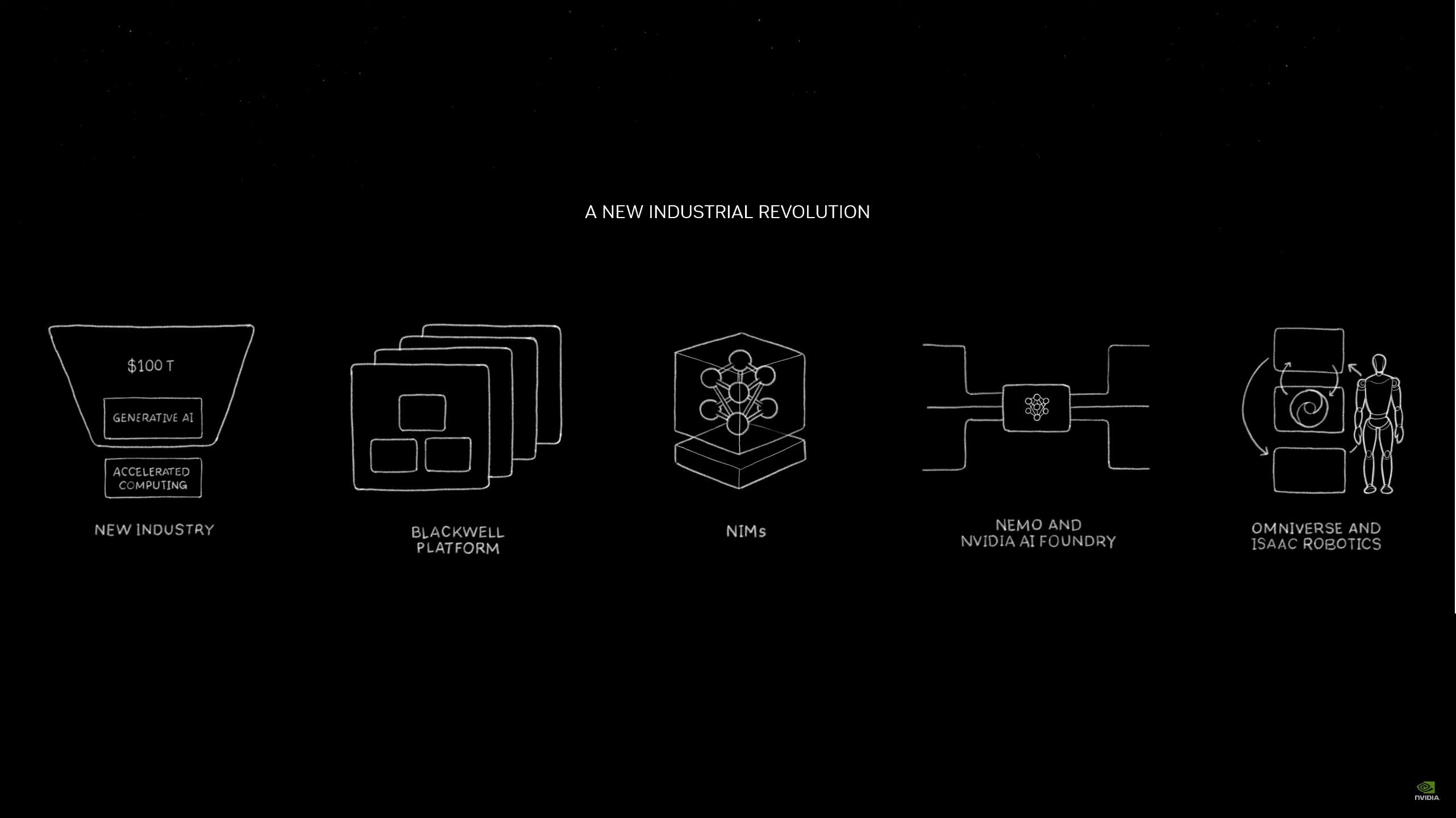
05:58PM EDT - New computer creates new kind of software, which means new means of distributing that software. NIMs

05:59PM EDT - And in the world of robotics, all of these systems need a platform, and that is Omniverse
06:00PM EDT - This is what we announced to you today

06:00PM EDT - HGX B100, NVLink Switch, GB200 Superchip Compute Node, Quantum X800 Switch, Spectrum X800 Switch

06:01PM EDT - "One more thing to show you"
06:01PM EDT - Rolling a final video

06:03PM EDT - "Powering the new era of computing: NVIDIA"

06:03PM EDT - And that's a wrap for us. Our initial Blackwell story is up now, with more details to come once I can get more bandwidth










10 Comments
View All Comments
GeoffreyA - Monday, March 18, 2024 - link
Hmm, I wonder what Mr. Nobody-needs-to-learn-programming-any-more has got to say...GeoffreyA - Monday, March 18, 2024 - link
"To help the world build these bigger systems, Nvidia has to build them first"Our Benefactor, Nvidia.
Dante Verizon - Monday, March 18, 2024 - link
A lot of AI-related propaganda that I don't care about, but it was surprising to learn that they're still using 4nm and not 3nm. Hmm. What would have happened? Apple?stadisticado - Tuesday, March 19, 2024 - link
Yield. Its a full reticle die. Even if N3 is healthy, it might not be healthy enough to make the unit economics work.LordSojar - Tuesday, March 19, 2024 - link
Propaganda is the keyword that you aren't paying close attention. It's okay... you'll get it eventually.Terry_Craig - Monday, March 18, 2024 - link
The performance shown FP8 and below is with sparsity, which is why such big and pompous numbers are announced in the slides. Ugly. The actual performance is half of it lolTomWomack - Monday, March 18, 2024 - link
I think from the photo it’s nine rack units of switches and 18 units of GB200 nodes, rather than nine and eighteen whole racks! Odd to have ten nodes above the switches and eight below.Ryan Smith - Monday, March 18, 2024 - link
Correct. That's 18 RUs of GB200 nodes, and another 9 RUs of NVSwitches.James5mith - Tuesday, March 19, 2024 - link
"04:51PM EDT - Traijning GPT-MoE-18.T would take 90 days on a 8000 GPU GH100 system consuming 15W"Now THAT is the kind of efficiency that nVidia should be striving for. lol
tomjames1966 - Tuesday, March 19, 2024 - link
With the data rates coming from these GPUS (10Tbps?!) aren't these things going to require a metric tonne of 800G transceivers? Or will 400G cut it?