AnandTech Exclusive: An Interview with Intel’s Raja Koduri about Xe
by Dr. Ian Cutress on November 20, 2019 1:00 PM EST
Ever since Raja Koduri left AMD and joined Intel, I have been continuously asking for a 1-on-1 interview, as I’m sure a number of my peers in the industry have also. For any event I went to that intersected with Raja, it became almost an amusing meme that I’d ask for time with him. His (and his team’s) response was pretty understandable, as he has had ‘nothing more to add, officially’ for a while, given how deep his remit has been inside the company and how long these projects take to emerge.
This week Raja gave the keynote at Intel’s HPC DevCon event, a precursor to Supercomputing, and I did my usual thing of asking for the interview, fully expecting the same ‘not quite yet’ response. To my surprise, Intel agreed, and we spent the best part of an hour discussing his role at Intel, his work, and some of the finer details of the recent Xe-HPC, Ponte Vecchio, and Aurora announcements.
Raja Koduri is a well-known figure in the semiconductor space, having previously held high positions at Apple, driving new architectures at AMD, and now at Intel in charge of everything to do with Architecture. His particular focus has been on Software and the new GPU initiative, and he is ultimately one prong of Intel’s charge into the wider compute arena, covering everything from integrated graphics to discrete graphics and then onto compute graphics. This means hardware, but also Raja is spending a lot of time with software, and digging deep with Intel’s new oneAPI initiative, to develop an all-encompassing SDK that developers can use to write code across any number of elements in Intel’s hardware stack. Raja is just coming shy of two years since joining Intel, over which time he has given a number of presentations and been part of a number of announcements, but truth be told the specifics of his role, beyond the few elements in this paragraph, are still unknown to the wider community.
This week at Intel’s HPC Developer Conference (HPC DevCon, or just DevCon), the company lifted the lid on Intel’s first high-performance graphics implementation, called Ponte Vecchio (PVC for short). In the scale of Intel’s new Xe architecture for graphics, the company announced that it will have two microarchitectures for the wide graphics market (Xe--LP for low power/integrated solutions, and Xe-HP for high power/discrete solutions), and a single microarchitecture for the high performance compute market (Xe-HPC, which goes from discrete through to more complex packaging). Intel also showed diagrams of the chiplet design behind Ponte Vecchio, with EMIB, Foveros, a new ‘Rambo’ cache, HBM, and a new Xe memory fabric (Xe-MF) that drives efficient scaling of all these elements. There are still plenty of points to pick from the slides of the presentation, which we are currently working on. Another element to the talk was Intel’s new oneAPI industry initiative, with the announcement that oneAPI is available in beta form today and is part of Intel’s DevCloud infrastructure too.
We should point out that there were a few topics that Intel weren’t going to talk about, such as exact details about the new Ponte Vecchio design (finer details will be disclosed when Intel determines it is the right time, I was told) and we weren’t able to talk about Intel’s process technology. Intel’s recent disclosures or supply chain demands are not within Raja’s wheelhouse, so we’re not covering them here. I’d rather speak to the appropriate people directly about those topics.
With that being said, we’d like to thank Raja and his team for this opportunity.
|
|
|
| Raja Koduri SVP, Chief Architect at Intel GM, Architecture, Graphics and Software |
Dr. Ian Cutress AnandTech, Senior Editor |


The ‘Koduri’ Factor
Ian Cutress: You’ve now been at Intel for coming up to two years, with a large remit of covering the company’s ‘Architecture’. How would you characterize your role at Intel compared to what you’ve done at other companies? What makes Intel unique and special for you to be at the company at this phase of history?
Raja Koduri: I think the biggest thing is to put my journey, to Apple, to AMD, and to Intel, into context. It’s a cyclical thing that goes between wanting to make a difference at a scale, and wanting to be disruptive. At a ‘scale’ company, like an Apple, you have the ability to reach hundreds of millions of users, so everything you do gets amplified. There’s a certain amount of satisfaction in that, in having an impact, and ultimately at a scale company you learn a lot. With enough time at such a company, you develop a fundamental set of disruptive ideas. It’s hard to be disruptive at a ‘scale’ company, and easier at a small company where they can be more agile and more open to taking risks. When I joined AMD 7 years ago, it was at an inflection point – they were hungry and ready to take risks and they provided me with a great opportunity to build new software and hardware architectures. They also provided me opportunities to learn about business and transforming company culture.
The next cycle for me was basically where I saw the technology going, and that fundamental technologies are needed. As both Jim and I have said on stage at various times, we want to drive more data closer to where it is needed – this is in itself a very interesting challenge and goes beyond just GPU architecture or CPU architecture. This problem touches every layer of technology in the industry, and Intel is one of the few companies that have the scale of technology of investments to pursue this dream. The breadth and depth of technology scale is HUGE at Intel and I saw Intel as an incredible learning opportunity – enough to keep me busy and excited for the rest of my life.
It’s great having all these smart people in the room, with no barriers, talking through how we’re going to drive 10x, 100x, or more on this stuff. There are very few companies in which you can go across the entire stack, from transistor to software.
IC: So far in your time at Intel, you and Jim Keller are often paired together as a team when it comes to disclosures and presenting to the media. In that context, Jim is often presented as the hardware person, and you’re presented as the software person. Are your roles really that straight cut?
RK: [chuckles] No, not really. You will have noticed that I’m increasingly focusing on the software, but ultimately my role in Architecture at Intel covers both. Architecture is often a misused word today – people usually use it in the context of microarchitecture, when in reality architecture defines a contract between the system and the developer - how something is built is not architecture, but how something interfaces with outside world and how something functions is architecture.
One of the most important aspects of architecture is the contract between hardware and software. I live very much in this hardware/software contract, the silicon platform contract, or in other words, the ecosystem – that is architecture. So my focus is on the ‘what & why’, and Jim focuses on ‘how & when’. Both of these points are connected with each other, so we work very closely to drive our collective teams forward.
IC: Intel is well known for its process technology and manufacturing, and Dr. Murthy (Renduchintala, Raja’s boss) announced a couple of years ago that Intel was disaggregating its product portfolio with its manufacturing process. When we interviewed Jim, he said (and has said repeatedly since) that he’s not worried about the process, and in the past 30 years whenever people have had process problems they are always solved. Intel’s recent manufacturing issues are a known factor, but I’ll ask the same question I posted to Jim – how much to you get involved at the process and manufacturing level?
RK: Very much. It’s also a really interesting topic. Like I’ve said before, at Intel, we have such a strong connection between how we build our chips and how we manufacture them. There’s a historic way of how we set up the methodologies and then the processes and tools around that. At most companies you have to go with what the manufacturer tells you they can do – at Intel, we get to know everything. We’re in a position where we can get involved in the manufacturing, and that’s very different from the outside ecosystem.
This method does also have its pros and cons. One of the big things that Jim and I are working on is how to amplify those positives in that model, as well as diminish the negatives. There are products and IPs, like particularly CPU for example, that get a lot of benefit from collaboration. By contrast, at a fundamental level, there are graphics and other things that due to the design don’t need that intense level of customization – customizing at that level can actually get in the way of us executing fast relative to the outside industry.
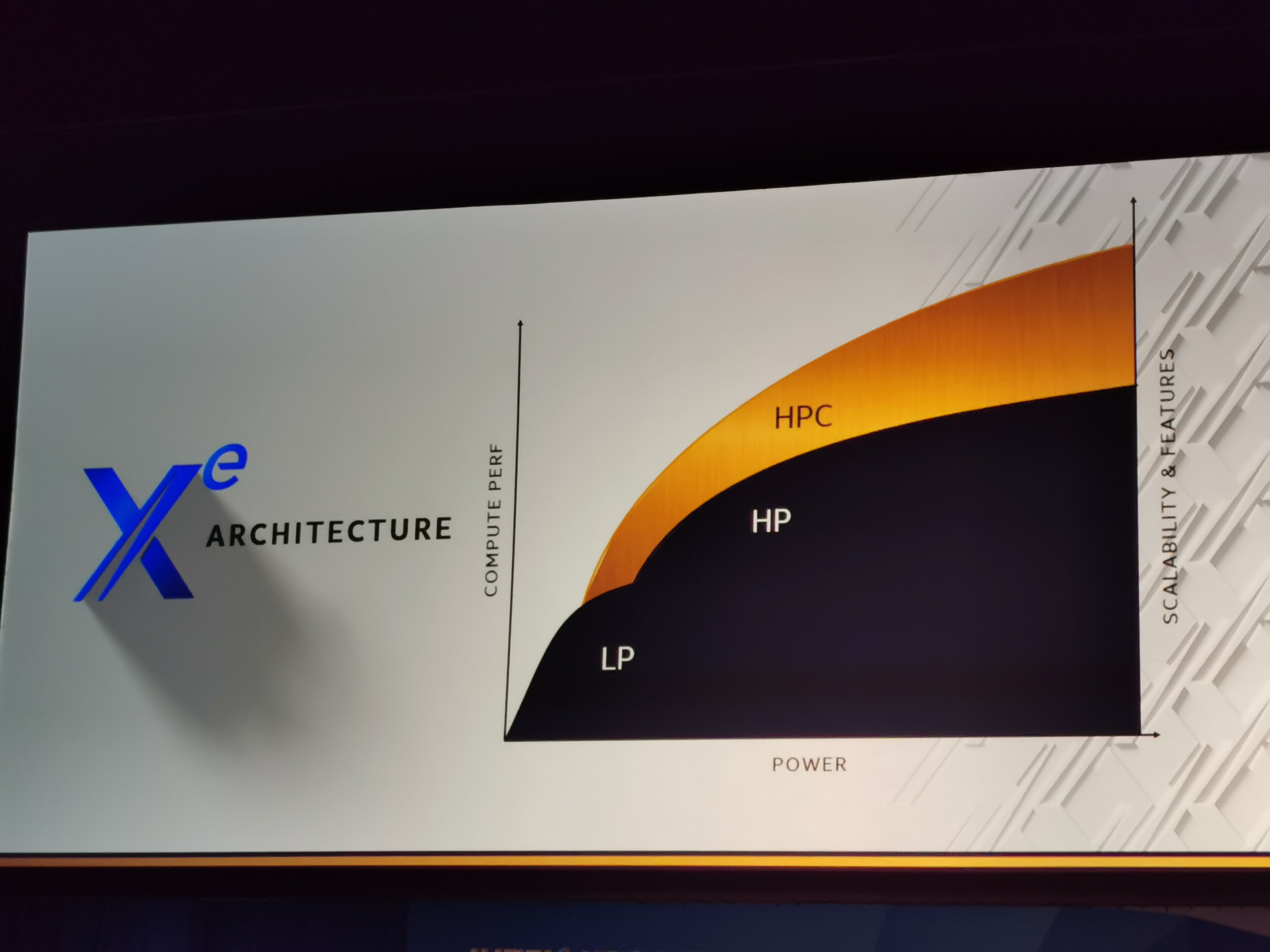
Architecture and Microarchitecture
IC: One of the big questions around Xe being an architecture and multiple ‘micro-architectures’ being spun from it is to how many microarchitectures are being developed inside Intel? Before today we knew that Intel would have two, and today you put names to those, Xe-LP and Xe-HP, but also introduced Xe-HPC for the compute market. Is there a fourth?
RK: It was good to mention the three on stage – it is three, and truth be told I don’t have a fourth one. Maybe I’ll have a fourth one if the need arises, but that’s it – three covers the entire roadmap.
IC: With the three variants of Xe you’ve mentioned today, Xe--L, Xe--HP, and Xe-HPC, are the products built on these microarchitectures fundamentally tied to specific Intel process nodes?
RK: No. The IP can be ported to any process technology.
IC: Of the three microarchitectures, I imagine you being knee deep in all three, defining the designs, managing the teams, and executing. Can you discuss a little bit actually how deep you personally go into this?
RK: At Intel I say that from 7am to 7pm there is not a single moment where I can turn my neurons off. We have to get the architecture and the microarchitecture details right to have amazing products. Nobody inside or outside gave us a chance two years ago that we will get new things like GPUs done. They said we will take 5 years and we will lose interest two years in! Well, we’re two years in now and we have our first discrete GPUs powered on. It’s not possible to drive these things without being hands-on.
IC: One of the things about Xe and the graphics team is that Intel rehired a number of engineers that worked on the Larrabee product, the attempt at an x86 graphics architecture. Even though we got Xeon Phi from that project, the fact that Intel has rehired these engineers means that there are obviously things that Intel can relearn from them and that project. How does that filter into Xe?
RK: Great question. You know, Larrabee, as well as Xeon Phi, taught us great learnings for lots of verticals. That experience helped us particularly with how Intel managed HPC at the time, and how we have built Xe-HPC and Ponte Vecchio today. There are a lot of problems that Xeon Phi solved particularly in relation to memory, coherency, virtual memory, reliability, and all that. Having access to that knowledge is helping us build a product like Ponte Vecchio very quickly. The Ponte Vecchio DNA incudes Gen, Xeon, Xeon Phi and even Itanium learnings.

The Goals of oneAPI
IC: Intel is starting to open up about Xe, and it clearly wants to cover a large range of the market, all with the oneAPI stack. Can Xe and oneAPI be everything to everybody at the same time?
RK: That’s a great question. First off, when we look at the scale and reach of graphics, whether it’s integrated graphics where we have hundreds of millions of users, or discrete graphics going into the cloud, one of the central elements is software. What is the software that runs all of this stuff? We have sets of APIs like DirectX, OpenGL, OpenCL, and other languages – and we also have middleware, like game engines that sit on top of the stack. What we want is to be everywhere where there is a software presence.
I will summarize our strategy simply as ‘Leverage, Optimize, Scale’. We are leveraging our existing CPU and integrated software stack and integrated graphics IP. We have invested heavily to optimize our existing IP. The next step was to scale - for the high-end GPUs, we needed to scale over 1000x. As you saw from the Xe-HPC disclosures, that’s our vision of scale.
I think we have a very good strategy here, and that is not something by accident – I’m taking my 20 years of industry experience, plus the two from being here at Intel, and applying it here. The way we approached the Xe design is to take measured steps – we’ve already proved with having silicon in hand.
IC: One of the key things with high performance computing is to know your hardware. In order to extract every iota of performance, you have to know how big your caches are, where the latencies are, memory bandwidth, exact ALU structures, and ultimately build software that is rarely portable in order for it to be so performant. One of the features of oneAPI is to move away from this specifity by enabling software that can potentially work anywhere. How do you reconcile this desire for very specific optimizations and yet have a software package/SDK that is designed to help everybody?
RK: Again, a great question. Our key goal with oneAPI was that no developer should be left behind. Within that, we have worked very hard on the interfaces for what we call ‘ninja programmers’ – the low-level software developers that build the high-performance libraries that everyone else uses. We noticed that these ninja programmers have a strong non-linear impact on the ecosystem, so with our system programming layer inside oneAPI, and some of the abstractions available through oneAPI, will give these ninja programmers control of hardware resources at finer granularity.
IC: Obviously the key operating systems and markets are going to be Windows, Linux, and to a certain extent, iOS. We’ve seen software packages for HPC attack these operating systems very differently, so what is the oneAPI strategy here?
RK: Great question. One of the things we agonised quite a bit over is how we make oneAPI support be very good on Windows. We recognize that the developer footprint with our PCs is a key strength, and we want to enable developers’ access to this stuff easily, whatever PC they pick up. So we put a lot of work in and you’ll see us supporting Windows and Linux in there. For operating systems beyond those, such as iOS, Android, and Chrome, it’s more whether you have on-device support or access to oneAPI service through cloud. This is where our DevCloud strategy, where developers can use oneAPI in the cloud, will come in.
The other thing to say is that with oneAPI, the version we shipped today is the beginning of a long journey. Solving this problem and building the stacks, building the services, will take time. Many innovations are in the pipeline, and this is why God invented something called version 2 and 3!
IC: Part of oneAPI, as you mentioned today on stage, is the ability to translate CUDA code to the oneAPI infrastructure. You’ve been at one company in the past that previously attempted to provide translation tools for its hardware, with varying degrees of success. What can Intel do here differently to make it succeed at scale?
RK: Great question. Portability of code between different parallel architectures has never been easy. There are often key fundamental differences between them, and a particular one is vector width. You can’t take a program that is optimized for a smaller vector width and make it efficient on a machine that has a larger vector width without refactoring the code and all that.
The Xe architecture is actually a narrower width machine - the variable vector width that we have and the ability to switch between SIMT mode and SIMD mode and combine them gives the software guys lots of tools to do more. Now having said that, the tools will take some time to mature. What we are seeing today is that we’re being more productive than prior attempts in the industry. We are also putting the software out ahead of the hardware for productive performance enablement.

Gaming on Xe
IC: Turning to gaming solutions, because there is a lot of interest in how Intel is going to attack the gaming space: what we’ve seen today is a compute GPU based on chiplets. Moving from a monolithic graphics chip to a chiplet design is a tough paradigm to solve, so does working on chiplets help solve the ‘multi-GPU’ issue on graphics? Is the future of graphics still consigned to single GPU, or should we expect multiple GPU scaling easier to manage?
RK: That’s a great question. As you know, solving the multi-GPU problem is tough – it has been part of my pursuits for almost 15 years. I’m excited, especially now, because multiple things are happening. As you know, the software aspect of multi-GPU was the biggest problem, and getting compatibility across applications was tough. So things like chiplets, and the amount of bandwidth now going on between GPUs, and other things makes it a more exciting task for the industry to take a second attempt. I think due to these continual advances, as well as new paradigms, we are getting closer to solving this problem. Chiplets and advancement of interconnect will be a great boost on the hardware side. The other big problem is software architecture. With many interesting cloud-based GPU efforts, I am optimistic that we will solve the software problems as well.
IC: Narrowing the scope down to discrete gaming GPUs, how is Intel going to approach those driver stacks with Xe?
RK: The system programming layer is a key difference between operating systems. The rest of the layers are largely OS independent. So we have a good development strategy here.
IC: With the GPU team, particularly the GPU marketing team, we’ve seen Intel pull in industry talent from a wide variety of sources, such as competitors, analysts, and even some of my former media peers. We’re seeing a strong commitment from Intel for this community, and building excitement for future Intel graphics solutions. To what degree, being in charge of graphics at Intel, are you pushing them ahead with that excitement, or are you telling them to reel it in?
RK: We have incubated a discrete GPU business unit at Intel, run by Ari Rauch. There was a lot of excitement when we announced our graphics ambition, and that attracted a lot of GPU talent from the industry, including for our marketing efforts. They have been doing a good job building up connections with gaming community and leveraging their feedback. My guidance to them always is to ’reel it in’ until we have products! But we will be geared to enable developers and the wider community with our marketing outreach.
IC: Have you discussed how the eventual discrete graphics launch is going to happen?
RK: Not really. We are so much focused on execution right now. But I will tell you a funny story about ’Ponte Vecchio’ name. At Intel we have a policy for engineering code names to places or things you can find on a map. We have had too many ’lakes’ and I wanted to do bridges. Wanted to pick a place that I don’t mind going to for a launch! Florence in Italy has some of best Gelato in the world. And I love Florence and the art and architecture there as well.

The Future of Gen Graphics
IC: Is Xe anything like Gen at a fundamental level?
RK: At the heart of Xe, you will find many Gen features. A big part of our decision making as we move forward is that the industry underestimates how long it takes to write a compiler for a new architecture. The Gen compiler has been with us, and has been continually improved, for years and years, so there is plenty of knowledge in there. It is impressive how much performance there is in Gen, especially in performance density. So we preserved lots of the good elements of Gen, but we had to get an order of magnitude increase in performance. The key for us is to leverage decades of our software investment – compilers, drivers, libraries etc. So, we maintained Gen features that help on software.
IC: As Xe pushes on and products come out, will Intel continue to develop Gen as a separate architecture line?
RK: All of our GPU teams are working on variants of the Xe architecture at the moment. We don’t see a reason for Gen anymore – Xe-LP, our low powered variant, covers the market that Gen covered.

The Future and The Vision of Xe
IC: You have been in the GPU space a long time. Is there anything definitive that you can say that Xe will bring to the table that hasn’t been seen before?
RK: In a word, vision. The ‘exascale for everyone’ vision. Solving this requires fundamental disruptions in all layers of technology stack. And I think we have taken a big step towards that with Ponte Vecchio. When I look at our path ahead, I think about how we make that happen. That for me is the foundation of Xe, relative to how the rest of the industry is thinking about things, and all the problems we’ve discussed today: distributed memory problems, distributed computing problems, and computing at scale problems are all essential things in our vision.
IC: Is there anything that the industry should know about Xe that it doesn’t spend enough time thinking about?
RK: It’s a question of scale. I think the impact of 200 million PCs with integrated graphics, moving to Xe, with more performance and better efficiency, is something I don’t see much of the industry appreciating. Intel’s reach and leverage means that a small change can make a big difference – here we are making a big change, and it’s going to have a knock-on effect. It’s a big deal.
Many thanks to Raja and his team for their time.








73 Comments
View All Comments
extide - Wednesday, November 20, 2019 - link
Excellent interview Ian, nice work. Now see if you can get Jim Keller :)Ian Cutress - Wednesday, November 20, 2019 - link
You meanhttps://www.anandtech.com/show/13048/an-anandtech-...
? 😁
extide - Wednesday, November 20, 2019 - link
Oh snap, looks like I forgot about that one. Thanks for the link :)eek2121 - Thursday, November 21, 2019 - link
Raja does throw a hint in there for discrete GPUs. However, if they aren't even willing to discuss a timeframe yet, even though they've announced the HPC offering and general availability, it is indeed looking like 5 years before their first discrete (non-HPC) launch. That is rather sad. If the performance is there, even AMD enthusiasts would be willing to buy an Intel GPU.peevee - Friday, November 22, 2019 - link
But why no questions about the scale of microarchitectural differences between the 3? Are they all grounds up (or divergent from Gen)? Or is it just a matter of how many 64-bit ALUs they have per 32-bit ALU? Or anything in between?Ian Cutress - Friday, November 22, 2019 - link
I asked about Gen and Xe similarities. The rest you suggest are list of questions that he wouldn't be answering at this time.alufan - Wednesday, November 20, 2019 - link
ohh look another intel promo whats that 3 in a month now?Seriously if you guys cant see how intel is playing you then you need to really wake up lets see how long this is on the front page
Ian Cutress - Wednesday, November 20, 2019 - link
We cover Intel announcements and disclosures. We cover AMD announcements and disclosures. We cover arm announcements and disclosures. Sometimes a company has a lot at once. There's no favoritism here. At the show I also had an interview with Papermaster, which will be going up soon.Jorgp2 - Wednesday, November 20, 2019 - link
I blame /r/pcmasterrace and /r/amdSmartcom5 - Wednesday, November 20, 2019 - link
Don't worry, you're just doing your job Ian!