The Memblaze PBlaze5 C916 Enterprise SSD Review: High Performance and High Capacities
by Billy Tallis on March 13, 2019 9:05 AM ESTPeak Random Read Performance
For client/consumer SSDs we primarily focus on low queue depth performance for its relevance to interactive workloads. Server workloads are often intense enough to keep a pile of drives busy, so the maximum attainable throughput of enterprise SSDs is actually important. But it usually isn't a good idea to focus solely on throughput while ignoring latency, because somewhere down the line there's always an end user waiting for the server to respond.
In order to characterize the maximum throughput an SSD can reach, we need to test at a range of queue depths. Different drives will reach their full speed at different queue depths, and increasing the queue depth beyond that saturation point may be slightly detrimental to throughput, and will drastically and unnecessarily increase latency. Because of that, we are not going to compare drives at a single fixed queue depth. Instead, each drive was tested at a range of queue depths up to the excessively high QD 512. For each drive, the queue depth with the highest performance was identified. Rather than report that value, we're reporting the throughput, latency, and power efficiency for the lowest queue depth that provides at least 95% of the highest obtainable performance. This often yields much more reasonable latency numbers, and is representative of how a reasonable operating system's IO scheduler should behave. (Our tests have to be run with any such scheduler disabled, or we would not get the queue depths we ask for.)
One extra complication is the choice of how to generate a specified queue depth with software. A single thread can issue multiple I/O requests using asynchronous APIs, but this runs into at several problems: if each system call issues one read or write command, then context switch overhead becomes the bottleneck long before a high-end NVMe SSD's abilities are fully taxed. Alternatively, if many operations are batched together for each system call, then the real queue depth will vary significantly and it is harder to get an accurate picture of drive latency. Finally, the current Linux asynchronous IO APIs only work in a narrow range of scenarios. There is work underway to provide a new general-purpose async IO interface that will enable drastically lower overhead, but until that work lands in stable kernel versions, we're sticking with testing through the synchronous IO system calls that almost all Linux software uses. This means that we test at higher queue depths by using multiple threads, each issuing one read or write request at a time.
Using multiple threads to perform IO gets around the limits of single-core software overhead, and brings an extra advantage for NVMe SSDs: the use of multiple queues per drive. The NVMe drives in this review all support at least 32 separate IO queues, so we can have 32 threads on separate cores independently issuing IO without any need for synchronization or locking between threads.
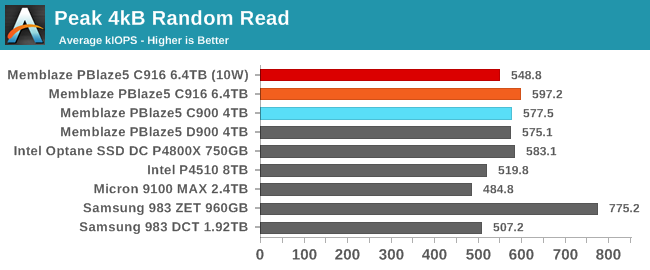
The Memblaze PBlaze5 C916 performs well enough for random reads that it is largely CPU-limited with this test configuration. Reaching the rated 1M IOPS would require applications to use asynchronous IO APIs so that each thread can issue multiple outstanding random read requests at a time, drastically reducing the software overhead of system calls and context switches. That kind of rearchitecting is something that few application developers bother with given the current limitations of asynchronous IO on Linux, so the CPU-limited numbers here are a realistic upper bound for most use cases.
Despite the software overhead, the newer PBlaze5 is able to offer a marginal performance improvement over its predecessor and other TLC-based drives, but it doesn't come close to matching the Samsung Z-SSD. The 10W power limit has a small impact on performance on this test, but even with the limit in place the PBlaze5 C916 is still outperforming the Intel P4510 and Samsug 983 DCT.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
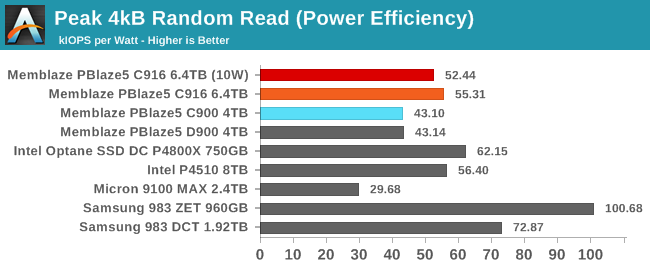
The upgrade to 64L TLC allows the newer PBlaze5 to save several Watts during the random read test, bringing its efficiency score almost up to the level of the Intel P4510. The Samsung drives with the relatively low-power Phoenix 8-channel controller still have the best performance per Watt on this test, with both the TLC-based 983 DCT and Z-NAND based 983 ZET significantly outscoring all the other flash-based drives and even beating the Intel Optane SSD.
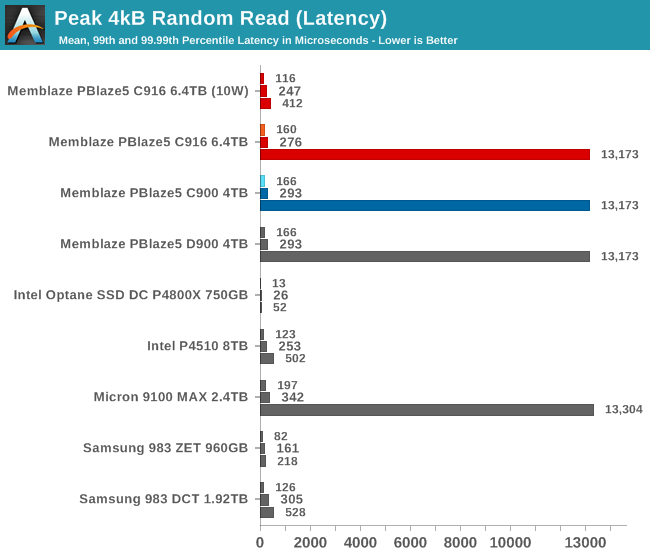
In its default power state, the PBlaze5 C916 still suffers from the abysmal 99.99th percentile latency seen with older drives based on the Microsemi controller. However, when the 10W power limit is applied, the drive's performance saturates just before the CPU speed runs out, and the score reported here reflects a slightly lower thread count. That causes the tail latency problem to disappear entirely and leaves the PBlaze5 C916 with better throughput and latency scores than the Intel and Samsung TLC drives.
Peak Sequential Read Performance
Since this test consists of many threads each performing IO sequentially but without coordination between threads, there's more work for the SSD controller and less opportunity for pre-fetching than there would be with a single thread reading sequentially across the whole drive. The workload as tested bears closer resemblance to a file server streaming to several simultaneous users, rather than resembling a full-disk backup image creation.
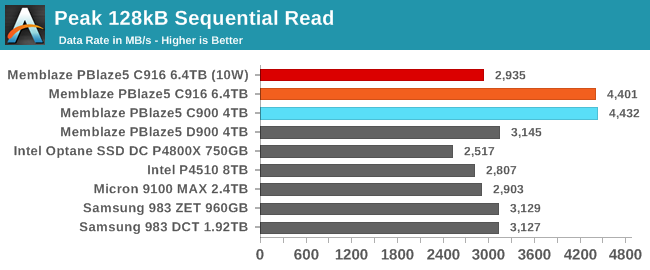
The peak sequential read performance of the Memblaze PBlaze5 C916 is essentially unchanged from that of its predecessor. It doesn't hit the rated 5.9GB/s because this test uses multiple threads each performing sequential reads at QD1, rather than a single thread reading with a high queue depth. Even so, the C916 makes some use of the extra bandwidth afforded by its PCIe x8 interface. When limited to just 10W, the C916 ends up slightly slower than several of the drives with PCIe x4 interfaces.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The drives with the Microsemi 16-channel controller are unsurprisingly more power hungry than the Intel and Samsung drives with smaller controllers, but the newest PBlaze5 uses less power than the older drives without sacrificing performance. The Samsung drives offer the best efficiency on this test, but the PBlaze5 C916 is competitive with the Intel P4510 and its performance per Watt is only about 18% lower than the Samsung 983 DCT.
Steady-State Random Write Performance
The hardest task for most enterprise SSDs is to cope with an unending stream of writes. Once all the spare area granted by the high overprovisioning ratios has been used up, the drive has to perform garbage collection while simultaneously continuing to service new write requests, and all while maintaining consistent performance. The next two tests show how the drives hold up after hours of non-stop writes to an already full drive.
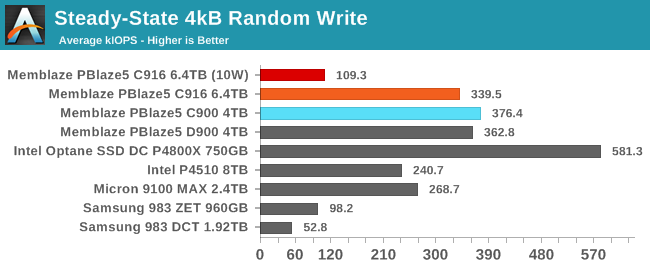
The steady-state random write performance of the PBlaze5 C916 is slightly lower than the earlier C900; the inherently higher performance of Micron's 64L TLC over 32L TLC is not quite enough to offset the impact of the newer drive having less spare area. Putting the drive into its 10W limit power state severely curtails random write throughput, though it still manages to outperform the two Samsung drives that generally stay well below 10W even in their highest power state.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
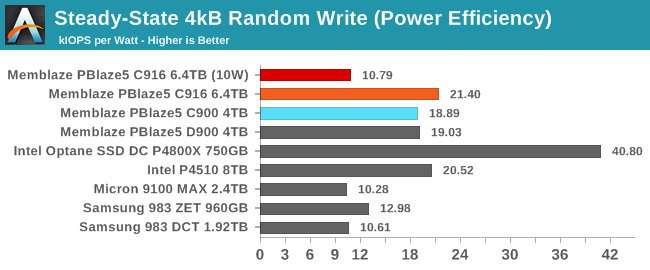
The newer PBlaze5 C916 uses several Watts less power during the random write test than its predecessor, so it manages a higher efficiency score despite slightly lower performance—and actually turns in the highest efficiency score among all the flash-based SSDs in this bunch. The 10W limit drops power consumption by 36% but cuts performance by 68%, so under those conditions the C916 provides only half the performance per Watt.
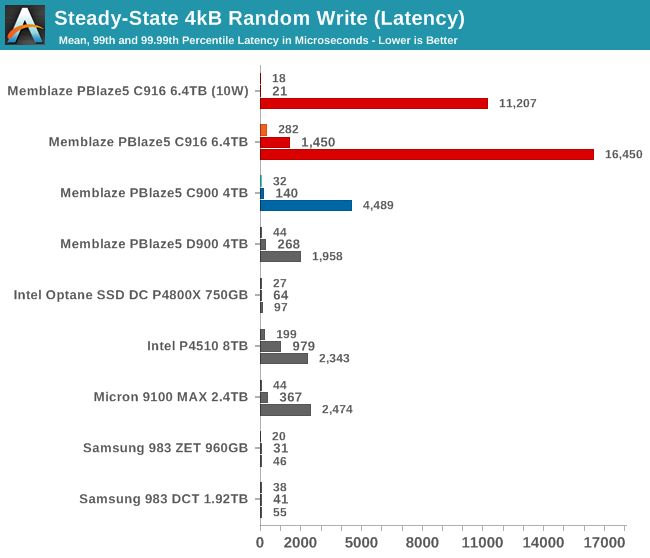
99.99th percentile latency is a problem for the PBlaze5 C916, and when performing random writes without a power limit, the average and 99th percentile latency scores are rather high as well. Saturating the full-power C916 with random writes requires more threads than our testbed has CPU cores, so some increase in latency is expected. The poor 99.99th percentile latency when operating with the 10W limit is entirely the drive's fault, and is a sign that Memblaze will have to work on improving the QoS of their lower power states if their customers actually rely on this throttling capability.
Steady-State Sequential Write Performance
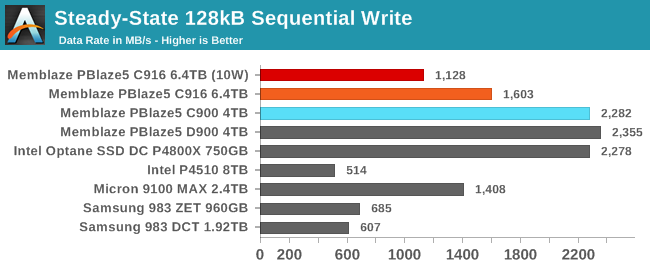
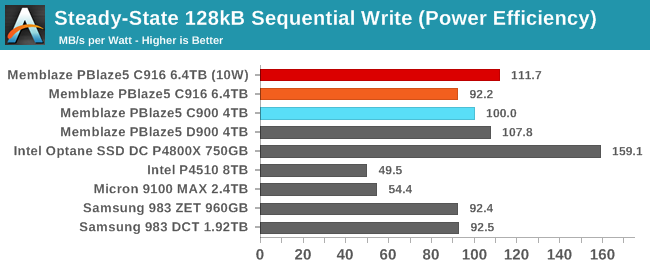
The lower overprovisioning on the newer PBlaze5 takes a serious toll on steady-state sequential write performance, even though the newer 64L TLC is faster than the 32L TLC used by the first-generation PBlaze5. However, it still performs far faster than the Intel and Samsung drives designed for about 1 DWPD with even lower OP than the PBlaze5 C916 with 3 DWPD. The Samsung 983 ZET has plenty of write endurance thanks to its SLC Z-NAND, but without lots of spare area the slow block erase process bottlenecks its write speed just as badly as it does on the TLC drives.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The PBlaze5 C916 uses much less power on the sequential write test than the earlier PBlaze5, but due to the lower performance there isn't a significant improvement in efficiency. The 10W power limit actually helps efficiency a bit, because it yields a slightly larger power reduction than performance reduction.








13 Comments
View All Comments
Samus - Wednesday, March 13, 2019 - link
That. Capacitor.Billy Tallis - Wednesday, March 13, 2019 - link
Yes, sometimes "power loss protection capacitor" doesn't need to be plural. 1800µF 35V Nichicon, BTW, since my photos didn't catch the label.willis936 - Wednesday, March 13, 2019 - link
That’s 3.78W for one minute if they’re running at the maximum voltage rating (which they shouldn’t and probably don’t), if anyone’s curious.DominionSeraph - Wednesday, March 13, 2019 - link
It's cute, isn't it?https://www.amazon.com/BOSS-Audio-CPBK2-2-Capacito...
takeshi7 - Wednesday, March 13, 2019 - link
I wish companies made consumer PCIe x8 SSDs. It would be good since many motherboards can split the PCIe lanes x8/x8 and SLI is falling out of favor anyways.surt - Wednesday, March 13, 2019 - link
I bet 90% of motherboard buyers would prefer 2 x16 slots vs any other configuration so they can run 1 GPU and 1 very fast SSD. I really don't understand why the market hasn't moved in this direction.MFinn3333 - Wednesday, March 13, 2019 - link
Because SSD's have a hard time saturating 4x PCIe slots, 16x would just take up space for no real purpose.Midwayman - Wednesday, March 13, 2019 - link
Maybe, but it sucks that your GPU gets moved to 8x. 16/4 would be an easier split to live with.bananaforscale - Thursday, March 14, 2019 - link
Not really, GPUs are typically bottlenecked by local memory (VRAM), not PCIe.Opencg - Wednesday, March 13, 2019 - link
performance would not be very noticeable. and even in the few cases it would be, it would require more expensive cpus and mobos thus mitigating the attractiveness to very few consumers. and fewer consumers means even higher prices. we will get higher throughput but its much more likely with pci 4.0/5.0 than 2 16x