The Memblaze PBlaze5 C916 Enterprise SSD Review: High Performance and High Capacities
by Billy Tallis on March 13, 2019 9:05 AM ESTQD1 Random Read Performance
Drive throughput with a queue depth of one is usually not advertised, but almost every latency or consistency metric reported on a spec sheet is measured at QD1 and usually for 4kB transfers. When the drive only has one command to work on at a time, there's nothing to get in the way of it offering its best-case access latency. Performance at such light loads is absolutely not what most of these drives are made for, but they have to make it through the easy tests before we move on to the more realistic challenges.

The PBlaze5 C916 is slightly faster for random reads at QD1 than the predecessor with 32L TLC, but Intel's P4510 has even lower latency from the same 64L TLC NAND.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
The C916 uses a bit less power than its predecessor, making it more efficient—but all three drives with the 16-channel Microsemi controller are still very power hungry compared to the smaller controllers in the Intel and Samsung drives. The advantages of such a large controller are wasted on simple QD1 workloads.
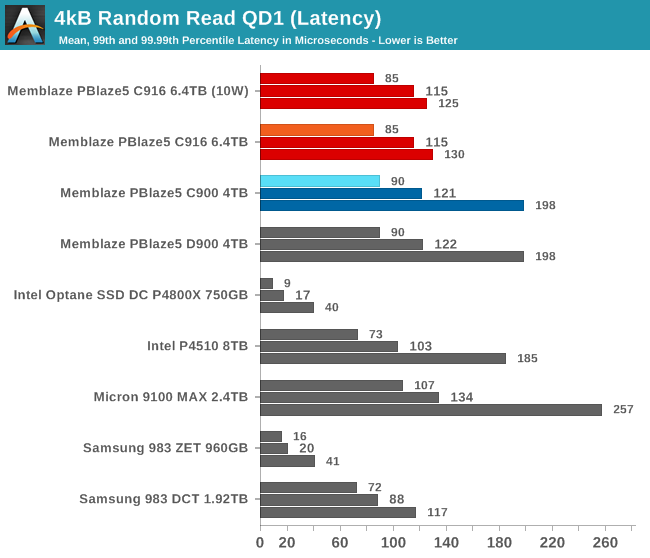
The PBlaze5 C916 brings a slight improvement to average read latency, but the more substantial change is in the tail latencies. The 99.99th percentile read latency is now much better than the earlier PBlaze5 drives and the Intel P4510.
 |
|||||||||
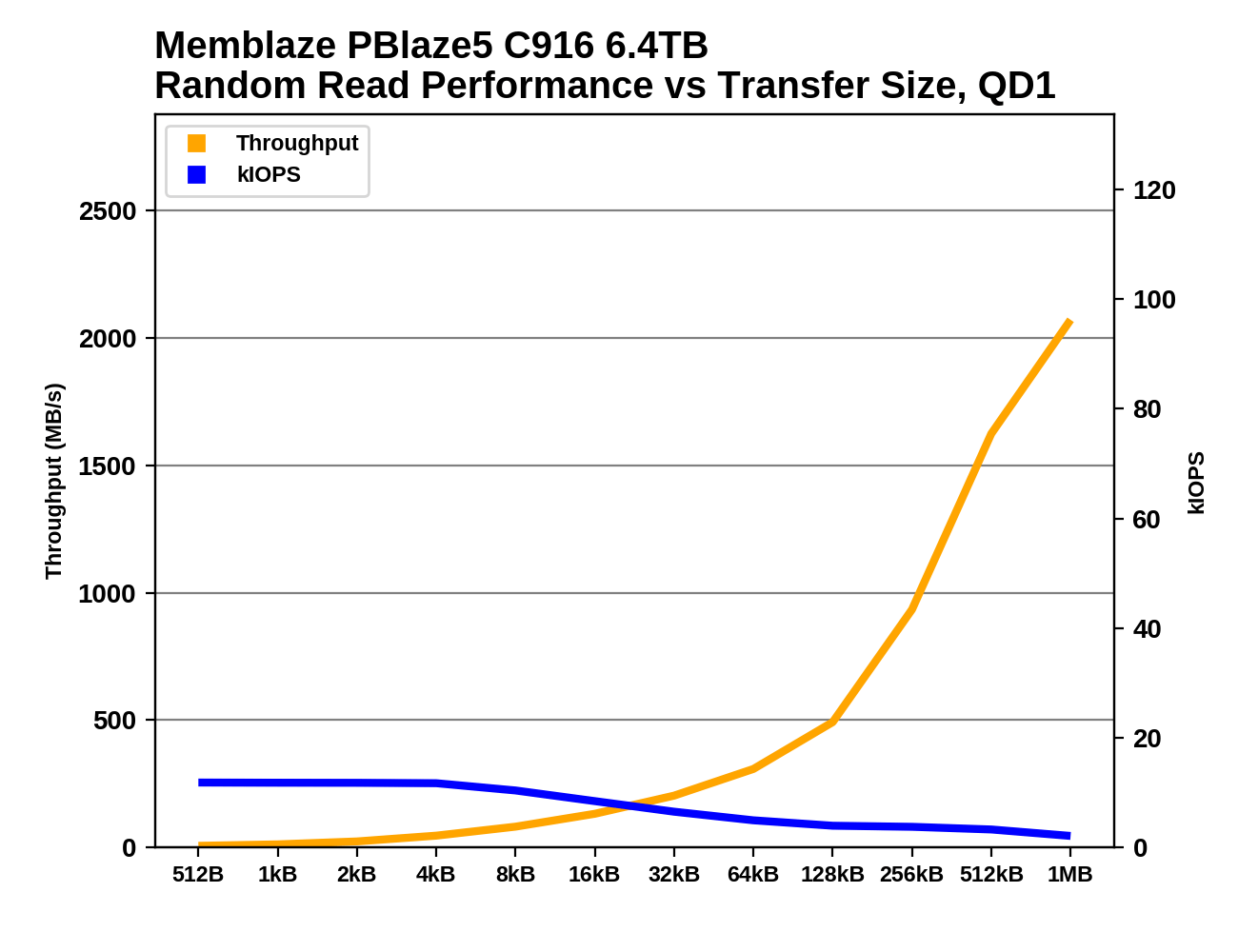
The new PBlaze5 is slightly faster for small-block random reads, but the large-block random read throughput has actually decreased relative to the previous generation drive. The PBlaze5 C916 offers peak IOPS for 4kB or smaller reads, without the sub-4k IOPS penalty we sometimes see on drives like the Samsung 983 ZET.
QD1 Random Write Performance
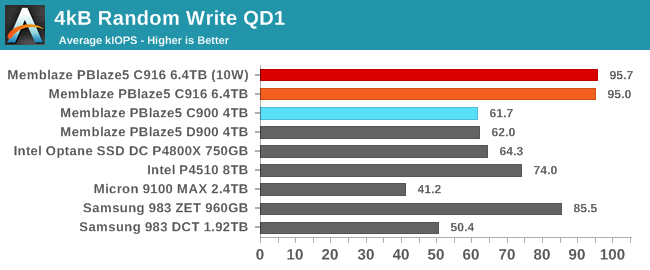
The queue depth 1 random write performance of the PBlaze5 C916 is excellent and a big improvement over the previous generation PBlaze5. At queue depth 1, the C916 is providing about the same random write throughput that SATA SSDs top out at with high queue depths. Even Samsung's Z-NAND based 983 ZET is about 10% slower at QD1.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
The power efficiency of the C916 during QD1 random writes does not stand out the way the raw performance does, but it is competitive with the drives that feature lower-power controllers, and is far better than the older drives we've tested with this Microsemi controller.
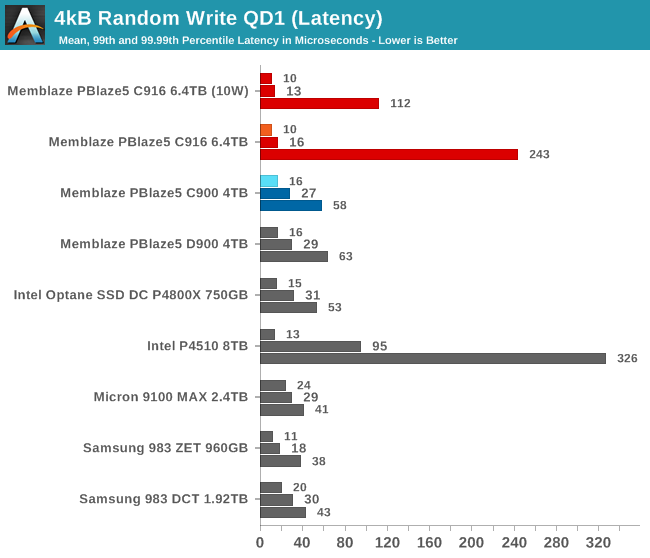
The new PBlaze5 C916 is in the lead for average and 99th percentile random write latency, but the 99.99th percentile latencies have regressed significantly—almost to the level of the Intel P4150. The earlier PBlaze5's 99.99th percentile latency was much more in line with other drives we've tested.
 |
|||||||||
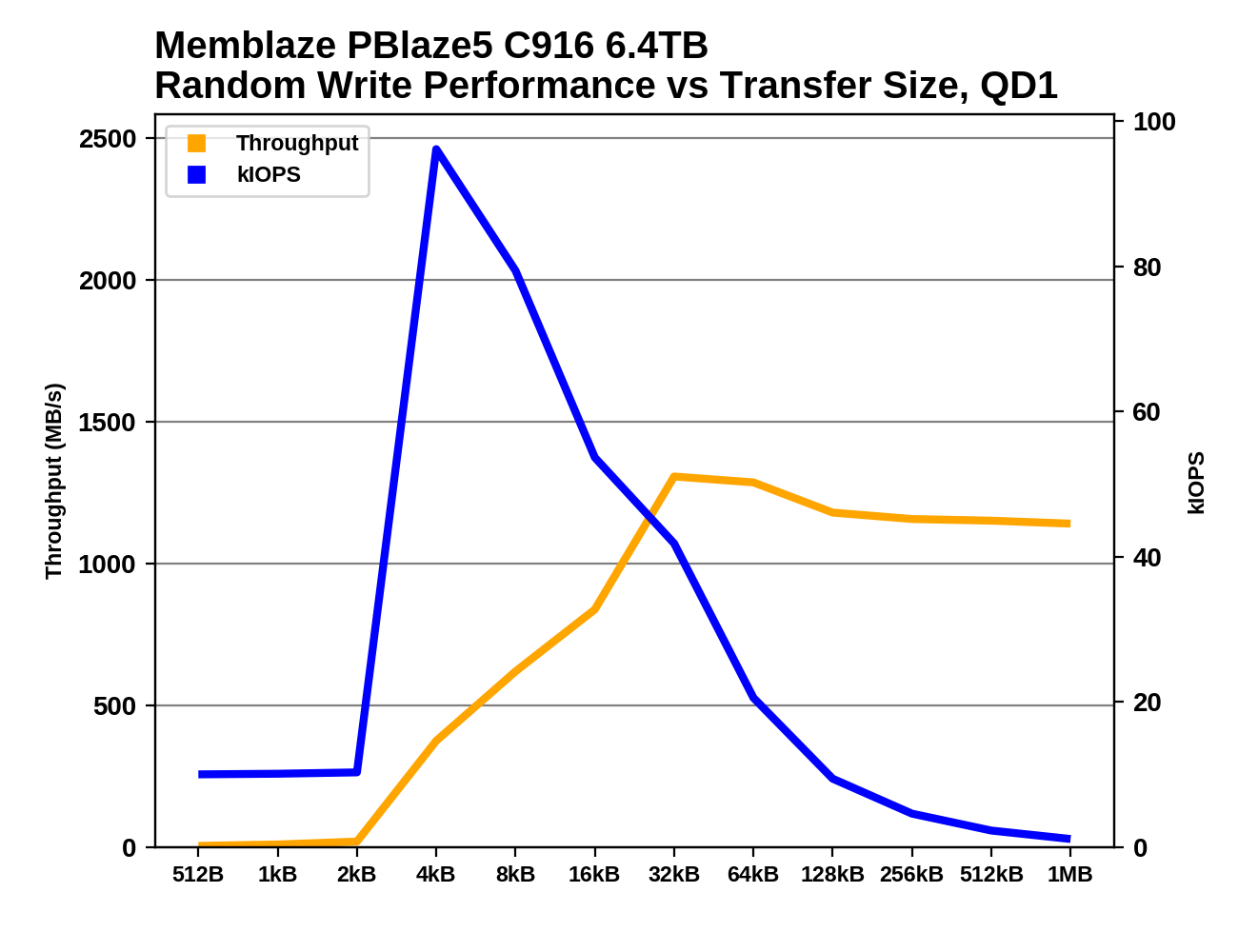
The PBlaze5 C916 continues the trend of very poor random write performance for sub-4kB block sizes on all drives using the Microsemi Flashtec controller. Since there's no performance advantage for small block random reads either, these drives should at the very least be shipping configured for 4k sectors out of the box instead of defaulting to 512-byte sectors, and dropping support for 512B sectors entirely would be reasonable.
As the test progresses to random write block sizes beyond 8kB, the 10W power limit starts to have an effect, ultimately limiting the drive to just under 500MB/s, less than half the throughput the C916 manages without the power limit.
QD1 Sequential Read Performance

The queue depth 1 sequential read performance of the new PBlaze5 is barely improved over the original. The PBlaze5 drives and the old Micron 9100 that uses the same Microsemi controller stand out for having exceptionally poor QD1 sequential read performance; they appear to not be doing any of the prefetching that allows competing drives to be at least three times faster at QD1.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The power efficiency of the new PBlaze5 is a slight improvement over its predecessor, but given the poor performance its efficiency score is still far below the competition. In absolute terms, the total power consumption of the PBlaze5 C916 during this test is similar to the competing drives.
 |
|||||||||
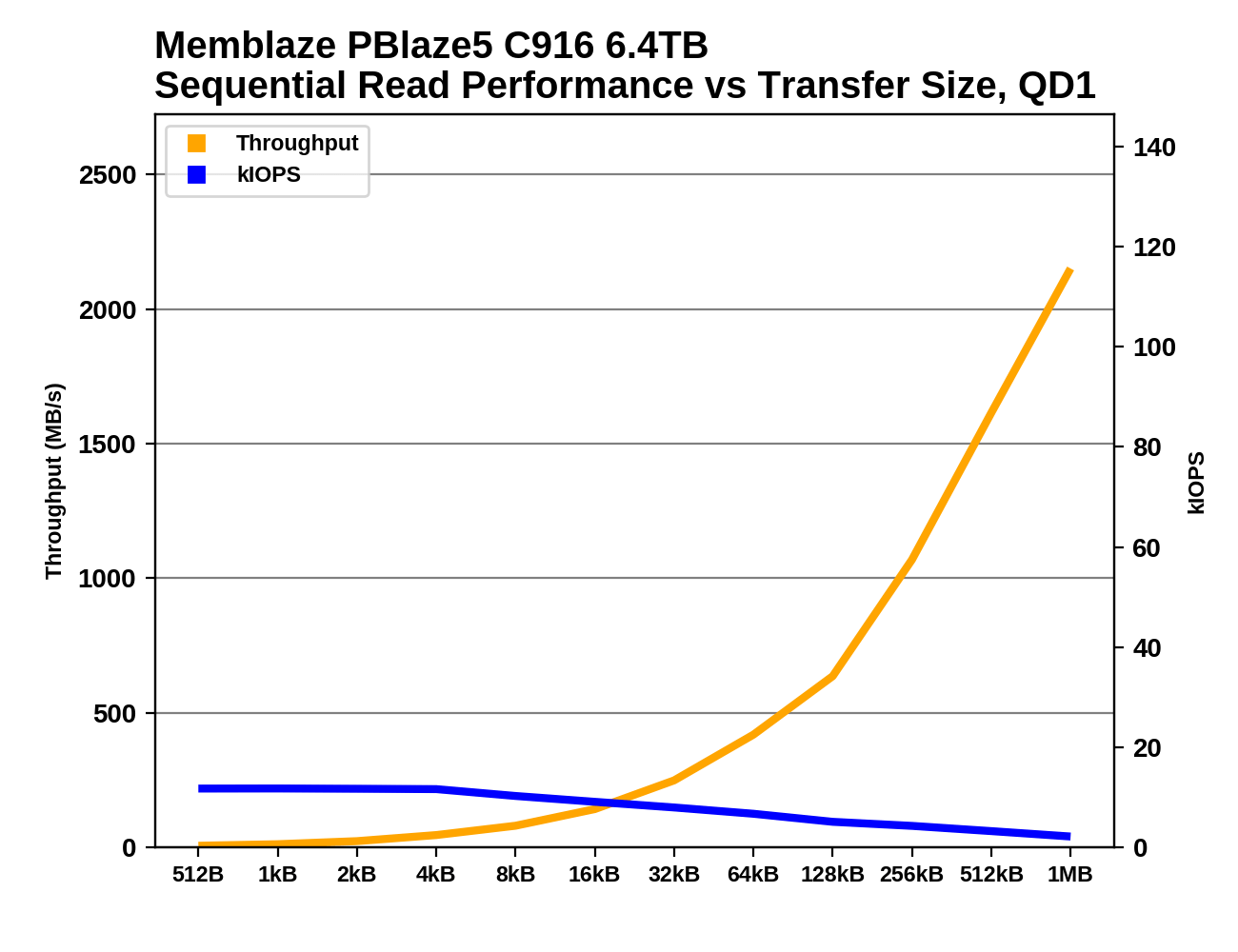
The QD1 sequential read throughput from the PBlaze5 C916 is quite low until the block sizes are very large: it doesn't break 1GB/s until the block size has reached 256kB, when the Intel P4510 and Samsung 983 DCT can provide that throughput with 16kB transfers. It appears likely that the PBlaze5 and the other Microsemi-based drives would continue improving in performance if this test continued to block sizes beyond 1MB, while the competing drives from Intel and Samsung have reached their limits with block sizes around 128kB.
QD1 Sequential Write Performance
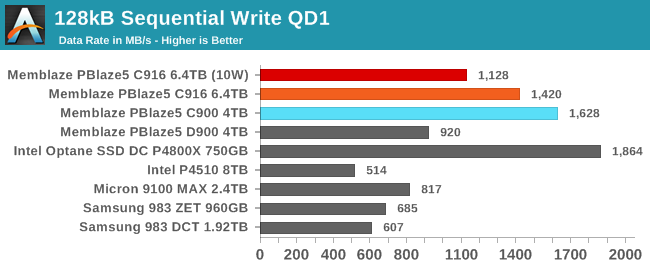
At queue depth 1, many of the drives designed for more read-heavy workloads are already being driven to their steady-state write throughput limit, but the PBlaze5 drives that target mixed workloads with a 3 DWPD endurance rating aren't quite there. The newer PBlaze5 C916 is a bit slower than its predecessor that has much higher overprovisioning, but still easily outperforms the lower-endurance Intel and Samsung drives even when the 10W power limit is applied to the C916.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
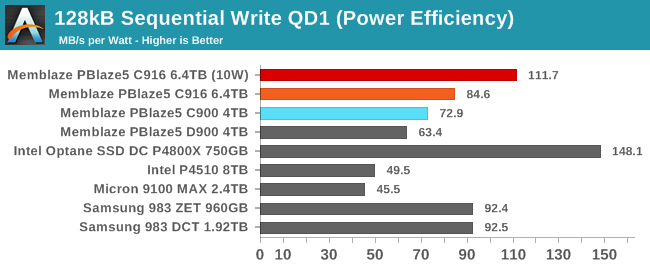
The older PBlaze5 C900's power consumption for sequential writes was very high even at QD1, but the C916 cuts this by 25% for a nice boost to efficiency. Applying the 10W limit to the C916 brings down the power consumption much more without having as big an impact on performance, so the efficiency score climbs significantly and surpasses the rest of the flash-based SSDs in this review.
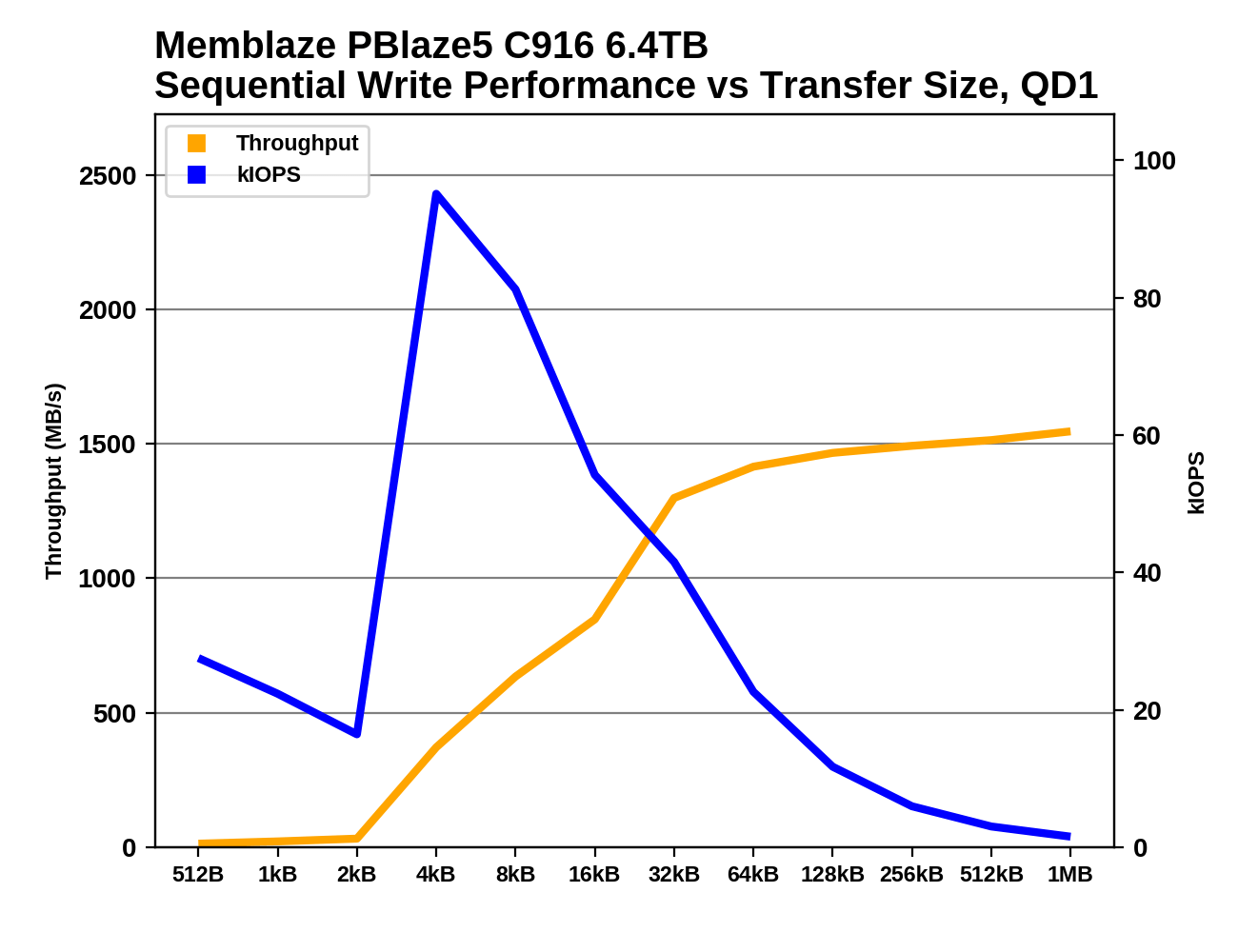 |
|||||||||
As with random writes, the PBlaze5 C916 handles sequential writes with tiny block sizes so poorly that sub-4kB transfers probably shouldn't even be accepted by the drive. For 4kB through 16kB block sizes, the newer PBlaze5 is a bit faster than its predecessor. For the larger block sizes that are more commonly associated with sequential IO, the C916 starts to fall behind the C900, and the 10W power limit begins to have an impact.








13 Comments
View All Comments
Samus - Wednesday, March 13, 2019 - link
That. Capacitor.Billy Tallis - Wednesday, March 13, 2019 - link
Yes, sometimes "power loss protection capacitor" doesn't need to be plural. 1800µF 35V Nichicon, BTW, since my photos didn't catch the label.willis936 - Wednesday, March 13, 2019 - link
That’s 3.78W for one minute if they’re running at the maximum voltage rating (which they shouldn’t and probably don’t), if anyone’s curious.DominionSeraph - Wednesday, March 13, 2019 - link
It's cute, isn't it?https://www.amazon.com/BOSS-Audio-CPBK2-2-Capacito...
takeshi7 - Wednesday, March 13, 2019 - link
I wish companies made consumer PCIe x8 SSDs. It would be good since many motherboards can split the PCIe lanes x8/x8 and SLI is falling out of favor anyways.surt - Wednesday, March 13, 2019 - link
I bet 90% of motherboard buyers would prefer 2 x16 slots vs any other configuration so they can run 1 GPU and 1 very fast SSD. I really don't understand why the market hasn't moved in this direction.MFinn3333 - Wednesday, March 13, 2019 - link
Because SSD's have a hard time saturating 4x PCIe slots, 16x would just take up space for no real purpose.Midwayman - Wednesday, March 13, 2019 - link
Maybe, but it sucks that your GPU gets moved to 8x. 16/4 would be an easier split to live with.bananaforscale - Thursday, March 14, 2019 - link
Not really, GPUs are typically bottlenecked by local memory (VRAM), not PCIe.Opencg - Wednesday, March 13, 2019 - link
performance would not be very noticeable. and even in the few cases it would be, it would require more expensive cpus and mobos thus mitigating the attractiveness to very few consumers. and fewer consumers means even higher prices. we will get higher throughput but its much more likely with pci 4.0/5.0 than 2 16x