ARM A53/A57/T760 investigated - Samsung Galaxy Note 4 Exynos Review
by Andrei Frumusanu & Ryan Smith on February 10, 2015 7:30 AM ESTCortex A57 - Synthetic Performance
We once again turn to SPECint2000 for an estimated performance score of the architecture - again, keeping in mind that this a deprecated and retired benchmark on the PC space.
| SPECint2000 - Estimated Scores | ||||||
| Apple A8 | Tegra K1-64 (Denver) |
Exynos 5430 (A15) |
Exynos 5433 (A57) |
5433 > 5430 %Advantage |
||
| 164.gzip | 842 | 1269 | 703 | 813 | 15% | |
| 175.vpr | 1228 | 1312 | 782 | 1120 | 44% | |
| 176.gcc | 1810 | 1884 | 1222 | 1549 | 28% | |
| 177.mesa | 2187 | 1308 | 1666 | 28% | ||
| 179.art | 5146 | 2113 | 2574 | 24% | ||
| 181.mcf | 1420 | 1746 | 983 | 1192 | 23% | |
| 186.crafty | 2021 | 1470 | 854 | 1149 | 34% | |
| 197.parser | 1129 | 1192 | 728 | 841 | 16% | |
| 252.eon | 1933 | 2342 | 1585 | 2096 | 32% | |
| 253.perlbmk | 1666 | 1818 | 994 | 1258 | 27% | |
| 254.gap | 1821 | 1844 | 1279 | 1466 | 15% | |
| 255.vortex | 1716 | 2567 | 1283 | 1652 | 32% | |
| 256.bzip2 | 1234 | 1468 | 898 | 1027 | 15% | |
| 300.twolf | 1633 | 1785 | 1102 | 1260 | 16% | |
When we look at the results of the SPEC scores, the gains are indeed smaller than what the A53 got over the A7. We get a relatively even 25% average boost throughout the various sub-tests of SPECint2000. Considering that the Exynos 5430 ran at 1.8GHz versus 1.9GHz for the 5433, this slight advantage goes down to 18% average when normalizing for clock speeds. The 177.mesa and 179.art tests are normally not part of the SPECint2000 suite but part of SPECfp2000 (being floating points tests), and usually don't get taken into account in the integer score of SPEC.
| GeekBench 3 - Integer Performance | ||||||
| A15 (ARMv7) | A57 (AArch32) | % Advantage | ||||
| AES ST | 68.4 MB/s | 1330 MB/s | 1844% | |||
| AES MT | 267.9 MB/s | 4260 MB/s | 1490% | |||
| Twofish ST | 64.4 MB/s | 81.9 MB/s | 27% | |||
| Twofish MT | 249.6 MB/s | 440.5 MB/s | 76% | |||
| SHA1 ST | 187.6 MB/s | 464.2 MB/s | 147% | |||
| SHA1 MT | 712.2 MB/s | 2020 MB/s | 183% | |||
| SHA2 ST | 80.5 MB/s | 121.9 MB/s | 51% | |||
| SHA2 MT | 316.0 MB/ | 528.3 MB/s | 67% | |||
| BZip2Comp ST | 3.81 MB/s | 4.88 MB/s | 28% | |||
| BZip2Comp MT | 13.5 MB/s | 19.3 MB/s | 43% | |||
| Bzip2Decomp ST | 5.93 MB/ | 7.41 MB/s | 25% | |||
| Bzip2Decomp MT | 22 MB/s | 29.7 MB/s | 35% | |||
| JPG Comp ST | 14.7 MP/s | 19.3 MPs | 31% | |||
| JPG Comp MT | 60.8 MP/s | 88.8 MP/s | 46% | |||
| JPG Decomp ST | 35.5 MP/s | 43.5 MP/s | 22% | |||
| JPG Decomp MT | 120.3 MP/s | 149.6 MP/s | 24% | |||
| PNG Comp ST | 990.7 MP/s | 1110 MP/s | 12% | |||
| PNG Comp MT | 3.65 MP/s | 4.57 MP/s | 25% | |||
| PNG Decomp ST | 15.3 MP/s | 19.1 MP/s | 25% | |||
| PNG Decomp MT | 53.6 MPs | 78.8 MP/s | 47% | |||
| Sobel ST | 49.7 MP/s | 58.6 MP/s | 17% | |||
| Sobel MT | 162.5 MP/s | 221.3 MP/s | 36% | |||
| Lua ST | 0.975 MB/s | 1.24 MB/s | 27% | |||
| Lua MT | 2.59 MB/s | 2.48 MB/s | -4.25% | |||
| Dijkstra ST | 4.05 Mpairs/s | 5.23 Mpairs/s | 29% | |||
| Dijkstra MT | 11.5 Mpairs/s | 17.1 Mpairs/s | 48% | |||
GeekBench's integer benchmarks paint a similar picture - if we disregard the huge boost to the cryptography scores we see an average advantage of 31% for the Exynos 5433's A57 cores, or 29% when we normalize for clock speeds.
There's not much to say here - the IPC improvements on the A57 seem to bring an average of 20-30% improvement on a per-clock basis. The pure integer benchmarks shouldn't change too much with AArch64 or A57, as most advantages of the chip are in FP workloads with the wider FP units.
| GeekBench 3 - Floating Point Performance | ||||||
| A15 (ARMv7) | A57 (AArch32) | % Advantage | ||||
| BlackScholes ST | 3.78 Mnodes/s | 4.37 Mnodes/s | 15% | |||
| BlackScholes MT | 14.8 Mnodes/s | 20.4 Mnodes/s | 37% | |||
| Mandelbrot ST | 1.02 GFLOPS | 1.14 GFLOPS | 11% | |||
| Mandelbrot MT | 4.01 GFLOPS | 5.09 GFLOPS | 27% | |||
| Sharpen Filter ST | 810.7 MFLOPS | 1030 MFLOPS | 27% | |||
| Sharpen Filter MT | 2.99 GFLOPS | 4.31 GFLOPS | 44% | |||
| Blur Filter ST | 0.93 GFLOPS | 1.27 GFLOPS | 36% | |||
| Blur Filter MT | 3.61 GFLOPS | 5.03 GFLOPS | 39% | |||
| SGEMM ST | 1.88 GFLOPS | 1.81 GFLOPS | -3.72% | |||
| SGEMM MT | 6.41 GFLOPS | 6.1 GFLOPS | -4.84% | |||
| DGEMM ST | 0.626 GFLOPS | 0.573 GFLOPS | -8.41% | |||
| DGEMM MT | 2.2 GFLOPS | 2.29 GFLOPS | 4% | |||
| SFFT ST | 0.948 GFLOPS | 1.1 GFLOPS | 16% | |||
| SFFT MT | 3.65 GFLOPS | 4.56 GFLOPS | 25% | |||
| DFFT ST | 678 MFLOPS | 1.02 MFLOPS | 50% | |||
| DFFT MT | 2.18 GFLOPS | 3.46 GFLOPS | 58% | |||
| N-Body ST | 322.3 Kpairs/s | 370.4 Kpairs/s | 15% | |||
| N-Body MT | 1.24 Mpairs/s | 1.44 Mpairs/s | 16% | |||
| Ray Trace ST | 1.51 MP/s | 1.7 MP/s | 12% | |||
| Ray Trace MT | 5.79 MP/s | 6.65 MP/s | 15% | |||
GeekBench's FP improvements are on the conservative side, where we see a rough 21% overall improvement.
It's here that things might improve in the future as AArch64 compiled tasks should allow for more effective register usage.
Power Consumption
Similar to the little core power consumption measurements, we repeat the exercise of trying to isolate power to a single cluster. The problem of threads spilling over to the other cluster is still prevalent: instead of blocking the GTS parameters to force threads to remain on the little cores, I force the mechanism to avoid migrating down processes and make them stay on the big cores. The issue here is that although most processes stay on the big cluster, there's still inevitable activity on the little cores. This is due to core0 of the system being treated as a special case and many kernel-related tasks being forcefully scheduled on that specific core. I expect this overhead to be in the 10-100mW range.
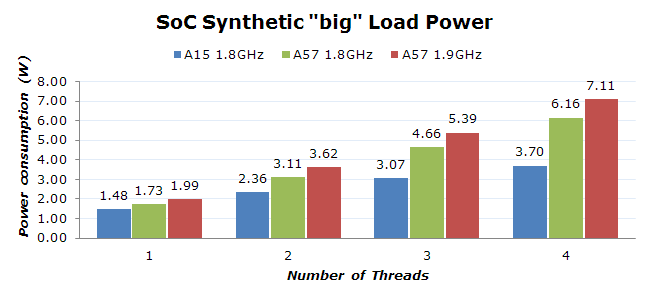
As opposed to the little cluster which ran at the same frequency in both our comparison SoCs, the A57 cluster on the 5433 runs 100MHz faster than the 5430's A15 cores. As such, I did a power measurement on both the stock 1.9GHz that the phone ships with, and at a limited 1.8GHz to be able to have a comparison figure at the same frequency as the A15 cores in the 5430.
The difference in power is quite staggering. What jumps out immediately as out of the norm is the relatively low power consumption the 5430 is able to achieve. In the past we've seen A15 cores consume well north of 1.5W per core, something I've verified in the Exynos 5410 and Kirin 920. The combination of r3 A15 silicon IP and 20nm in the 5430 seems to have dramatically lowered the power consumption of the A15 to levels comparable to Qualcomm's Krait cores. It seems Samsung has gained a lot of experience with the A15 over the years and fed this back into the 5430, resulting in basically twice the power efficiency over past SoCs such as the 5420. But while the A15 numbers are interesting, we're here to check out the A57.
Alas, it doesn't look as good for the new cores. On a pure per-core basis it seems the A57 is about twice as power hungry. This is a significant figure that is quite worrisome. Investigating the voltages of the big cores on both SoCs reveals that the 5433 increases the voltage on the A57 cores by a rough 75mV across most used frequencies. We're averaging 1175mV at 1800MHz across the various speed bins, and reaching up to 1262mV on the worst speed bins at 1.9GHz. This results in some very high figures for the stock speeds of the 5433, being able to momentarily reach over 7W load on the big cluster. The thermal management doesn't allow this state to be sustained for more than 10 seconds when loading four threads, with the frequencies quickly dropping to the first thermal throttling levels.
I repeated my analysis over all frequency states and core count combinations, providing me with a detailed power curve for the A57 CPUs in the Exynos 5433:
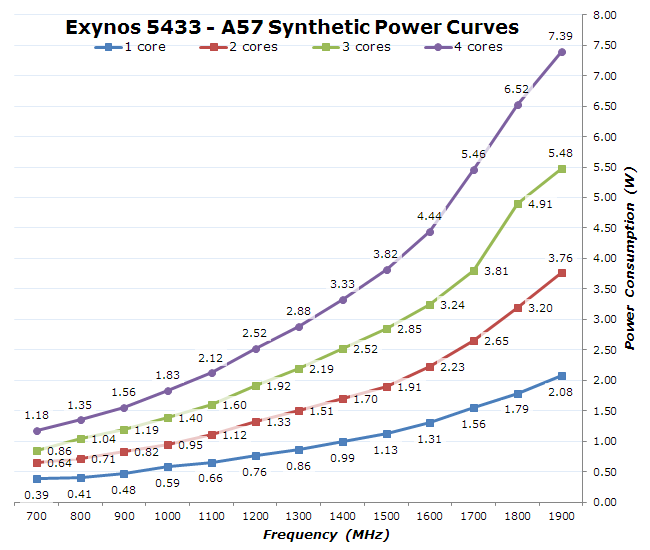
I was able to catch the effect of temperature over power consumption in these tests: over the period of a minute power would continuously increase as the silicon heated up. After only 10 seconds of load the consumption would increase by 5%. Frequencies above 1600MHz especially suffer from this effect, as static power leakage seems to be increasing a whole lot on these states, so I wasn't able to account for the measured power to dynamic leakage alone. This might also be an effect of overhead elsewhere on the system; I imagine that the PMIC is working very hard at these kind of loads.
In any case, this points to the importance of having responsive and smart power management mechanisms that take into consideration not only frequency and voltage in their power modeling but also temperature. Luckily the Exynos 5433's power management is one of the best out there, having a full power arbitration system in place that does not allow the higher power figures for longer than short little bursts. Most work done should find itself in the lower frequencies, enabling much higher efficiency levels. The battery savings mode of the phone also caps the frequency of the A57 cores at 1400MHz, allowing for a very reasonable maximum 3.3W cap on the big cores while still providing excellent performance.
Again, we're able to get some rough estimates on the per-core power consumption figures for both SoCs running at equal frequency:
| Estimated Big Per-Core Power Consumption @ 1.8GHz | |||
| A15 (Exynos 5430) | A57 (Exynos 5433) | Increase | |
| Big per-core load | ~750mW | ~1480mW | 97% |
The A57 cores being an ARMv8 evolution of the A15 with only minor architectural additions beyond that shouldn't be that much bigger than the A15. Indeed we can see this in the block sizes of the SoCs:
| A15 vs A57 Block Sizes | ||||
| A15 (Exynos 5430) | A57 (Exynos 5433) | Scaling Factor | ||
| Core | 1.67mm² | 2.05mm² | 1.22 | |
| Cluster | 14.50mm² | 15.10mm² | 1.04 | |
We're seeing a much more conservative 1.22x scaling, less than the 1.75x found in the A53 cores. The total cluster size increases only by 4%, pointing out that Samsung made some improvements elsewhere on the cluster.
I repeat the XML test of BaseMark OS II to be able to give an impression of real-world performance/power.
| BaseMark OS II - XML Parsing Energy Efficiency | ||||
| Performance | Energy | Performance/Energy factor |
||
| A15 (Exynos 5430) | 99.69MB/s | 19.75mWh | ~5.04 | |
| A57 (Exynos 5433) | 155.29MB/s | 27.72mWh | ~5.60 | |
As opposed to the A53 which lost perf/W over the A7, the A57 actually gains efficiency over the A15. This shouldn't make sense given that the active power of the A57 seems to be roughly double that of the A15 on these specific SoCs. We go back to why I choose this particular test: the nature of the the XML test allows for cores to exercise their idle power states in a realistic manner.
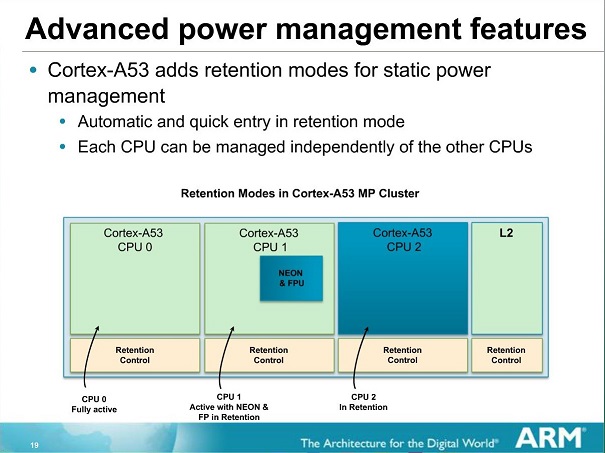
ARM claims the A53 and A57 bring better and more fine-grained pipeline power- and clock-gating as part of the architectures, and my suspicion is that this is what we are seeing here in practice. I don't have other fitting devices at my disposal to be able to make an apples-to-apples comparison, but it seems that in daily real-world usages the A57 is able to outperform the A15 quite a bit in terms of power efficiency.
While we investigated both the A53 and A57 separately as individual clusters in the SoC, I was also very interested to see how the XML test would fare in the default big.LITTLE mode. We repeat the power measurement but leave the GTS parameters as configured by Samsung.
| BaseMark OS II - XML Parsing Energy Efficiency | ||||
| Performance | Energy | Performance/Energy factor |
||
| A7 (Exynos 5430) | 77.93MB/s | 10.56mWh | ~7.38 | |
| A15 (Exynos 5430) | 99.69MB/s | 19.75mWh | ~5.04 | |
| A7+A15 (Exynos 5430) | 76.53MB/s | 12.85mWh | ~5.95 | |
| A53 (Exynos 5433) | 109.36MB/s | 17.11mWh | ~6.39 | |
| A57 (Exynos 5433) | 155.29MB/s | 27.72mWh | ~5.60 | |
| A53+A57 (Exynos 5433) | 96.85MB/s | 18.77mWh | ~5.15 | |
What we're seeing here in our particular XML power efficiency test is that the whole mechanism falls flat on its face. For both the Exynos 5430 and Exynos 5433, the practical performance drops below what even the little cores would have been able to achieve on their own. While on the Exynos 5430 we lose efficiency over the little cores, it's still an improvement over letting the A15 cores handle the load alone. However when looking at the numbers of the 5433, things look bad. Running this benchmark on the default A53+A57 GTS mechanism not only is worse than simply running it on the little A53 cores, but it's also worse than letting the benchmark stay on the A57 cores. I could see the load jumping around between big and little cluster in a frequent manner.
As to why this performance degradation happens is not certain. I've been told that this may have been related to the way the benchmark was programmed and possible data-dependencies coming into play that cause an unusal overhead on the CCI. This is an interesting thought as this would be one particular case where ARM's newly announced CCI-500 interconnect would help out with the introduction of a snoop filter on the interconnect. I certainly did not aim for such a result in my search for a test-case micro-benchmark, but it raises the question of how many other real-world situations run into such bottlenecks.
It's also important to note that these numbers cannot be used as an argument against the efficiency of HMP itself. Running the big cores only is not a realistic use-case as there are vast power efficiency disadvantages in idle scenarios. A proper comparison would be if I had run the SoCs in a cluster-migration scheme and used that as a comparison point against the HMP operation. Sadly this is not a technically viable scenario for me to reproduce due to software limitations in the firmware. As such, these numbers are more of a representation of the A57 cores' efficiency rather than that of big.LITTLE and HMP as a whole.
I've had some concerns raised to me for the fact that I don't have a fixed-load benchmark test in regards to power efficiency, so I went ahead and ran a power efficiency test on some of our web-browser tests. As a reminder, these tests may represent a real-world workload in terms of computations that are being done, but they don't represent a proper scaling load as we would find in real-world usage. For that, I have included some benchmarks in the battery section of the review which we'll investigate later in the article.
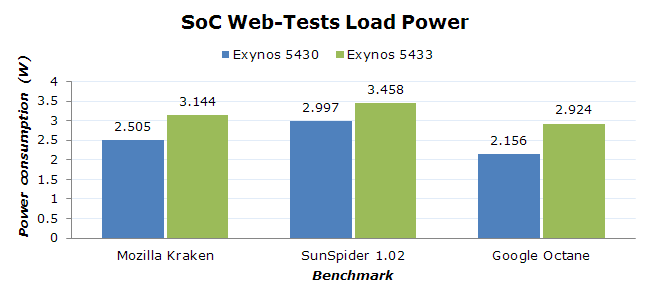
| Stock Browser - Web Tests Power Efficiency | ||||
| Score | Mean Power | Score/Power factor |
||
| Kraken (E5430) | 4973ms | 2.505W | ~80.27 | |
| SunSpider (E5430) | 449ms | 2.997W | ~743.13 | |
| Octane (E5430) | 5762 | 2.156W | ~2.67 | |
| Kraken (E5433) | 4160ms | 3.144W | ~76.45 | |
| SunSpider (E5433) | 395ms | 3.458W | ~732.11 | |
| Octane (E5433) | 7466 | 2.924W | ~2.55 | |
Before discussing the results I'd like to mention that I saw a huge discrepancy between Chrome and the stock browser. In Chrome, which I checked was indeed running the exactly same build version for both the Note 4 and the Alpha, I could see the Alpha consistently outperforming the Note 4 in all the tests. Due to this I deemed Chrome to be extremely unreliable as an apples-to-apples comparison of efficiency and reverted to the stock browser. Here I could see proper performance scaling that we would actually expect from the new core architectures and the clock advantage.
As for the browser efficiency scores themselves, what I see is that the Exynos 5430 again beats the 5433 in power efficiency, although this margin is just 4%. I have to reiterate again that we're dealing with Samsung's sixth generation of A15 SoC, and that's if we don't count consumer TV SoCs which also had A15 cores deployed over 2 years ago. The Exynos 5433 is only Samsung's second (after their unreleased GH7 server SoC) A57 implementation that we're seeing and it is also running at higher voltages on an immature process. I fully expect this gap to reverse in the future as we see vendors gain more experience with the IP and optimize their layouts and implementation.
I've talked in more detail on how currently HMP is implemented by vendors in the Huawei Honor 6 review which can be read here. For those who are still unfamiliar with the subject a quick explanation is that the current mechanism in the kernel that is used for controlling HMP operation is "GTS", or Global Task Scheduling. This mechanism is developed by Linaro, a consortium of ARM vendors which collaborate on the open-source software development side of SoCs. GTS is a Linux kernel modification that enables the scheduler to differentiate between the little and big cores of a system, and migrates tasks depending on their load.
The current mechanism as of late 2014 and found in all commercially available devices determines the decision of migrating a task on a target cluster with help of a geometric load value of a given task, a value that is defined by the kernel scheduler. The window in which the load is averaged depends on the vendor, but we've seen mostly 16ms in the case of Huawei and 32ms in Samsung's implementations. If a scheduler entity (a process) surpasses a certain upper threshold, the system migrates that entity to a fast cluster. Similarly, if it falls below a lower threshold, it is migrated to the slow cluster.
The problem with this approach is that the scheduler is totally unaware of the power consumption of the hardware when doing a migration. As a reminder, this process is done transparently in hardware via help of a cache-coherent bus interconnect such as ARM's CCI-400.
Not only does this cause migration overhead on the CCI due to cache flushes, but it messes with the idle mechanisms of the CPU. When a lower number of high load threads get migrated away from the big cluster and back to it, the cluster is allowed to enter its cluster power collapse state that also shuts down the L2 cache. This turning off and on of the cluster in repeated and high-frequency fashion consumes more power than had the load simply stayed on the big cluster and dealt with the active power penalty of the A57.
Samsung's implementation of GTS worsens this behavior as they employ a boosting mechanism that is tied with the interactive CPU frequency governor and user-space triggers such as switching applications or touchscreen events via the touch-booster mechanism. The boost here temporarily lowers the migrations thresholds to very low levels (15% down, 40% up) to be able to improve device fluidity.
In my opinion this is overkill as trivial tasks such as scrolling through an application like Reddit Sync (with already loaded content) causes the processes to reside on the big cluster. It's possible to disable this behavior via the power savings mode of the device. In my example of the Reddit app there is no discernable loss of fluidity when just scrolling through posts, and the big cores remain idle, making for much lower power consumption. The disadvantage of the power savings mode is that it caps the CPU to 1.4GHz and the GPU to 350MHz. I wish Samsung would provide a two-stage power savings mode where we could control both the boost mechanic and the clock frequency limits separately.
It's been over two years since the first big.LITTLE SoCs were introduced, and even if we ignore the first generations such as the Exynos 5410 and 5420 that were limited to cluster-migration schemes, ARM has had plenty of time to produce a more effective software stack that takes advantage of big.LITTLE. The fact that the Note 4 is using a 14-month old implementation of GTS that is lacking some key improvements in the scheduler in terms of power management demonstrates a grave problem of the big.LITTLE approach, as the software represents the Achilles' Heel of the technology and severely limits its potential.
ARM and Linaro are working on a solution for upstream Linux that has been discussed for well over a year. To this day the power-aware scheduler still hasn't seen a definitive implementation, and when we brought up the issue with ARM they admitted that progress has been slow due to the fundamental changes the solution requires and the many stakeholders it involves. The process has been complicated by the fact that ARM wants to get it right the first time and work in a generic solution that can be carried over to future ARM SoCs, a process that takes longer than implementing a one-off non-upstream solution for a specific product.
Meanwhile ARM is also calling attention to their Intelligent Power Allocation project for upstream Linux. Like the new power-aware scheduling solution, it too has yet to make it upstream. IPA has already seen limited adoption in shipping products in at least Samsung's devices, and ARM believes it can mitigate some of the issues related to the scheduler. While IPA is an excellent thermal management implementation, it cannot serve as a replacement for a proper mechanism that tries to optimize power efficiency in HMP operation, as it has no control over where a task is placed on the CPUs. Also, IPA is only enabled when the SoC passes a certain threshold temperature and any arbitration below that is still left to the kernel scheduler.
In any case, I'd wager we won't be seeing ARM's power aware scheduling solution in devices for well over another 18 months at minimum. Meanwhile, Qualcomm is entering the big.LITTLE ring with its own Snapdragon 810 with a fully working, custom-developed, and power-aware scheduler implementation that alleviates many of the issues I've identified here in this piece.
In the future, I hope Samsung SLSI invests more time and R&D in its software implementations, as being first to market with the hardware and relying on Linaro's basic software stack simply isn't enough if they wish to continue using big.LITTLE as the corner-stone of their SoCs.








135 Comments
View All Comments
ddriver - Tuesday, February 10, 2015 - link
I'd like to see A57 performance without being so crippled by a ram bottleneck.blanarahul - Wednesday, February 11, 2015 - link
Loved this article. Only thing missing was gaming fps and power consumption comparison b/w LITTLE cluster only, big cluster only and big.LITTLE modes.ddriver - Thursday, February 12, 2015 - link
Also in true 64bit mode, cuz a lot of the perf improvements in v8 are not available in legacy 32bit mode.It is a shame really, samsung decided the uArch improvements would be enough to barely pass this chip as "incremental", they didn't bother to feed a higher throughput chip with a wider memory bus. As much as it pains me, apple did better in that aspect by not crippling their A7 chip, even if only because they needed it for a "wow factor" after so many generations of mediocre hardware, especially given the many exclusive initial shipment deals they secured to stay relevant.
thegeneral2010 - Wednesday, February 18, 2015 - link
i like wat u say and i really like to see note 4 running on 64bit this would give samsung processors a great push forward and trust of consumers.bigstrudel - Tuesday, February 10, 2015 - link
If it wasn't completely obvious already:Apple A Series stands alone years ahead of the rest of the pack.
Flunk - Tuesday, February 10, 2015 - link
But if they don't sell it to anyone else, it doesn't really matter does it?Apple doesn't compete with Samsung or Qualcomm when it comes to selling SoCs because they don't sell SoCs to other companies. A slight lead in CPU performance is not going to get people to buy an iPhone over and Android, if that's what they're set on buying.
xype - Tuesday, February 10, 2015 - link
It does matter insofar as to be a benchmark of what is possible (as long as they are ahead). And let’s not pretend Apple’s CPUs sucking wouldn’t invite the same kind of comments—just like every situation where 2 competing technologies are compared.Platform/fanboy trolling aside, that’s something Android users benefit from as well. Apple being "stubborn" about 2 core CPUs, for example, is a nice counterweight to the 8 cores and 8 mini-cores and 8 quasi-cores trend that some CPU vendors seem to have a hard-on for, and it gives a nice real-world example of how such an approach to mobile CPU design works out, no?
If Apple stays ahead in the mobile CPU game, the people using non-Apple phones will always have a target to point to and demand equality with. Otherwise they’d just have to live with whatever Qualcomm et al feed them.
bigstrudel - Tuesday, February 10, 2015 - link
My comment isn't fanboy jingo-ism. Its fact.There's not a single Android ARM core on the market that can even match the power of the Apple A7's Cyclone cores much less A8's 2nd gen design.
Were still waiting for anything custom to come out of the Android camp aside from the frankensteinish design of Nvidia's Denver core.
I really shouldn't need to explain why to people on Anandtech.
ergo98 - Tuesday, February 10, 2015 - link
The Tegra K1 64 bit is faster, core per core, versus the A8 (you do realize that the K1-64 has only 2 cores, right? I'm going to have to guess no, or you just are completely unable to read a chart). The A8x offers marginal per core performance advantages over the A8, and the primary benefit is the third core. The K1 64 is a A57 derivative, *exactly like the A8*.Your comments can only be construed as trolling. Can't match the A7? Give me a break.
tipoo - Tuesday, February 10, 2015 - link
Ergo, you're completely off. The Denver K1 is a VLIW code morphing architecture - it has nothing to do with the Cortex A57, nor does the Apple Cyclone, they're both custom architectures.The K1 offers better performance in benchmarks, but as a result of code morphing, it can be hit or miss in real world, causing jank.