A Look at Altera's OpenCL SDK for FPGAs
by Rahul Garg on October 9, 2013 8:00 AM ESTOpenCL Programming Model and Suitability for FPGAs
OpenCL is an open-standard programming interface developed by the Khronos group designed particularly for parallel and heterogeneous computing. OpenCL can be used to program various types of hardware including CPUs, GPGPUs, FPGAs and many-core coprocessors like Xeon Phi or Adapteva's Epiphany. Each hardware vendor that wants its hardware to be exposed to OpenCL needs to provide an OpenCL driver for its hardware. For example, OpenCL drivers are available for various CPUs and GPUs for Windows, Linux and Mac and Altera is now providing OpenCL drivers and associated development tools for their FPGAs. Prior to OpenCL, there were no standard programming languages that exposed coprocessors on an equal footing. Thanks to the rise of GPGPU, the idea of accelerators and coprocessors has entered the mainstream and having a standard interface to accelerators is a big win for FPGA vendors. In many ways, the concepts that apply to programming a discrete GPGPU placed on a PCIe board also apply to FPGAs.
We go over some OpenCL terminology.
Host and devices: The CPU is called the host, and each hardware that has an OpenCL driver is called a device. Each device can have one or more compute units and each compute unit can have multiple processing element. This is shown visually below (figure from Hands on OpenCL course).
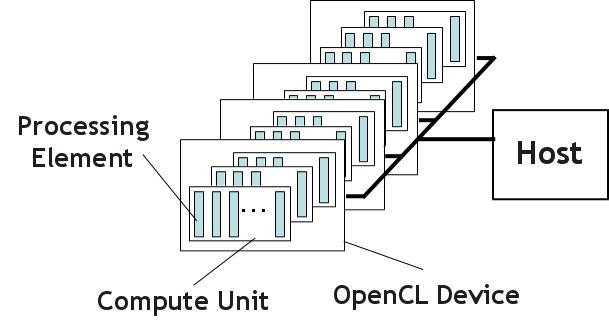
For example, Nvidia Titan GPU contains 15 SMX units and each SMX unit corresponds to a compute unit in OpenCL and each SMX has 192 processing elements. On FPGAs, the number and complexity of each compute unit is not fixed and instead is customized to your application.
Unlike say C, C++, Java or Python, OpenCL cannot be used standalone. Instead, the main program runs on the CPU (the host) as usual and typically only the computationally intensive parts of the program are written in OpenCL and called from the main program. However, work is not automatically distributed across various devices. Instead, the application program can query the OpenCL runtime for the list of all OpenCL compatible devices in a system and can choose the appropriate device for each computation.
Device memory: Each device has its own memory space where it can allocate arrays of data (called buffers) that can be read/written from OpenCL programs. In a discrete GPU or an FPGA, the buffer objects will typically reside in the RAM placed on the PCIe based board that contains the GPU or FPGA chip. For example, in a GPU such as Radeon 7970, the buffer objects will typically be placed in the GDDR5 RAM. OpenCL provides functions to copy data between host (CPU) memory and device memory. Some vendors also allow transferring data between multiple devices in a system directly without CPU intervention.
Kernels: OpenCL programs consist of kernels, which are similar to functions in C. Kernels can read/write from buffer objects that are passed as arguments to the kernel. Kernels are written in a C-like programming language. The OpenCL driver for a given hardware compiles it to the appropriate format. For CPUs and GPUs, the vendor's OpenCL driver will compile it to the native instruction set of the processor. We will get into how kernels are compiled by Altera's SDK in the next section.
Work-items, work-groups and parallelism: Unlike say C, where usually a function call leads to execution of a single instance of a function, the host launches the kernels across a 1D, 2D or 3D grid of "work-items". Each work-item can be thought of a conceptual thread and each work-item executes the same kernel function. However, each work-item knows its index in the thread and will typically compute different parts of a solution.
For example, let us say you wanted to add two vectors of length N. This is how you will do it in plain C:

You can write a kernel where each work-item adds one element of the vector corresponding to its index. Here is the sample OpenCL kernel.

In this case, each work-item is performing the work done by one loop iteration in the C code. Thus, if you wanted to add vectors of size 1000, you will launch this kernel with 1000 parallel work-items. OpenCL is an inherently parallel API and particularly suited for highly parallel problems.
Work-items are organized into work-groups, which are small grids of say 8x8 work-items, and items within a work-group can synchronize with each other but items from different work-groups cannot. This work-item and work-group organization maps particularly well to GPUs. FPGAs also prefer highly parallel workloads but the way they get compiled to FPGAs is very different and we will get to that soon.
Local memory: Accessing memory is an expensive operation. CPUs include hardware-managed caches with the hope that the data that is reused in the program can be brought into the cache once and then read/written multiple times from the cache. However, some architectures such as all recent desktop GPUs from AMD, Nvidia and Intel include small amount of fast memory on-chip that acts as a software managed cache. OpenCL provides a construct called "local memory" to expose such software managed caches. Each work-group can allocate local memory (typically upto 32 or 64kB per work-group) and all work-items in the work-group can read/write from the local memory. Local memory is implemented via the software managed cache on GPUs while CPUs allocate it in regular RAM and hope that it will be end up in the cache during program execution. FPGAs also include on-chip memory that can be used to implement OpenCL's local memory construct in hardware. Some members of the Stratix V series include upto 52Mbit (~6.5MB) of on-chip memory that can be used as local memory. In comparison, Radeon HD 7970 includes about 2MB of local memory on-chip and a GTX Titan includes about 450kB of local memory.
You can learn more about OpenCL at the official page at Khronos or look over some tutorials such as the recently released Hands on OpenCL. Overall, the OpenCL programming model looks to be a surprisingly good fit for FPGAs. Concepts such as host/device separation, device memory vs CPU memory, inherently parallel programming model and finally the local memory abstraction all look to be very well suited to FPGAs.








56 Comments
View All Comments
BryanC - Wednesday, October 9, 2013 - link
Thanks for the article. Are you planning a follow up where you write some programs and measure performance? I'm curious to see how it compares when you actually try to use it.rahulgarg - Wednesday, October 9, 2013 - link
It is on my to-do list. Will have to ask Altera if they are up for it. Not sure if they are used to being covered and benched by websites such as Anandtech :P. I think it is likely new territory for both us and them.Also, experimental design will have to be careful. Doing an experiment would involve tuning the kernels for each device first. So even if assume that I do get some hardware, it will certainly be a time-consuming process.
Kevin G - Wednesday, October 9, 2013 - link
I'd be curious to see the raw initial result. Knowing what you can get by recycling your OpenCL code is of interest to parties that don't have the resources to do a good port.rahulgarg - Wednesday, October 9, 2013 - link
Thanks for the feedback. If I do testing, I will keep that in mind.toyotabedzrock - Wednesday, October 9, 2013 - link
If you do a followup could you explain vectorization in more detail? Your other explanations where very understandable.vladx - Friday, October 11, 2013 - link
Vectorization simply means in his example adding all the vector's elements all at once instead of doing it iterative with a loop, thus the algorithm's time is constant (1) instead of linear (n).Brutalizer - Tuesday, October 15, 2013 - link
Vectorization is done like this. Compare this non vectorized code:for (i = 0; i < 10000; i++)
A = B + C
To this vectorized code:
A = B + C
Here, A, B and C are vectors. So you can add each element at once. You dont have to add one element at a time, instead you add them all at once. You add vectors in one operation, instead of lot of scalars. The many GPU processors will add one element each, at once - thus you have vectorized code.
GNUminex - Wednesday, October 16, 2013 - link
Your post somewhat goes against my knowledge of FPGAs. FPGA performance is result of the number of slices of your fpga, the max frequency, the HDL compiler's optimization capabilities and your code. What exactly could you test other than the performance of openCL versus traditional hardware design languages on the same fpga? If you are comparing an FPGA to a GPU you might as well also compare them to a CPU because the optimal applications of each piece of hardware are completely different.esoel - Wednesday, October 9, 2013 - link
Interesting stuff but the article would be _so_much_ better with some hands on and benchmarks… Altera don't be cheap, send this guy a review unit! ;-)rahulgarg - Wednesday, October 9, 2013 - link
Yes, I do think doing actual benchmarking should ideally be next on the list but do see my reply above.