Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
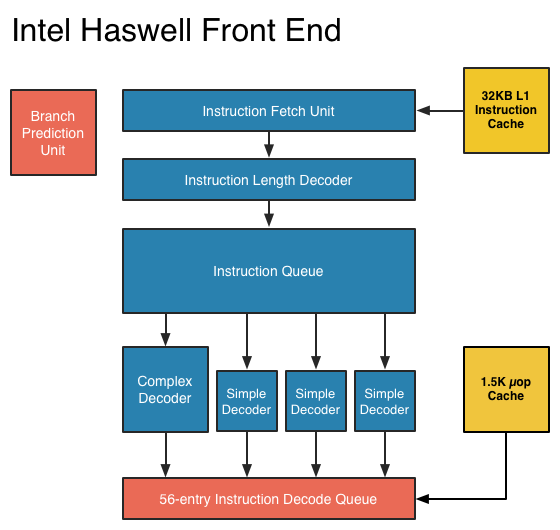
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
CaptainDoug - Friday, October 5, 2012 - link
Quite the read. Very informational. Anandtech has some of the best tech writers. True online journalism. Sometimes i miss that while reading tech blogs... You guys are a cut above.. at least one.colonelclaw - Friday, October 5, 2012 - link
Couldn't agree more, this article really brightened up what was otherwise a pretty miserable afternoon here in London.When am I going to be able to walk into a shop and buy something with Haswell inside it? Next March maybe?
Kepe - Friday, October 5, 2012 - link
As stated in the article, Haswell is coming in the summer of 2013.linuxlowdown - Saturday, October 6, 2012 - link
Tag team Intel fanboy puke.Azethoth - Sunday, October 7, 2012 - link
How do I downvote stupid crap like this "Tag team Intel fanboy puke." comment so that collectively we can see high quality comments without having to wade through the interturds as well? It really takes away from the best article I have read in a long time. Not because it is about Intel, but because it is about the state of the art.medi01 - Tuesday, October 9, 2012 - link
Well, I'd also ask how do I downvote stupid butt kissing like OP, while we are at rating....Kisper - Saturday, October 20, 2012 - link
Many people enjoy well written and informative articles. Are you telling me that if you wrote, you would not enjoy positive feedback from your readers?CaptainDoug - Tuesday, October 23, 2012 - link
Exactly.actionjksn - Sunday, October 7, 2012 - link
Why are you even on this article dumb fuck? I'm sure there is something that is of interest to you on the internet somewhere.medi01 - Tuesday, October 9, 2012 - link
Not sure about him, but I've looked into this article to figure power targets for haswell (especially interesting to compare to ARM crowd), NOT to read orgasmic comments about eternal wizdom of Intel's engineering...