The AMD FirePro W9000 & W8000 Review: Part 1
by Ryan Smith on August 14, 2012 4:00 AM ESTGraphics Core Next: Compute for Professionals
As we just discussed, a big part of AMD’s strategy for the FirePro W series relies on Graphics Core Next, their new GPU architecture. Whereas AMD’s previous VLIW architectures were strong at graphics (and hence most traditional professional graphics workloads), they were ill suited for compute tasks and professional graphics workloads that integrated compute. So as part of AMD’s much larger fundamental shift towards GPU computing, AMD has thrown out VLIW for an architecture that is strong in both compute and graphics: GCN.
Since we’ve already covered GCN in-depth when it was announced last year, we’re not going to go through a complete rehash of the architecture. If you wish to know more, please see our full analysis from 2011. In place of a full breakdown we’re going to have a quick refresher, focusing on GCN’s major features and what they mean for FirePro products and professional graphics users.
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together.
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at.
As a result of these deficiencies in AMD’s fundamental compute and memory architectures, AMD faced a serious roadblock in improving their products for the professional graphics and compute markets. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is what AMD set out to do.
Having established what’s bad about AMD’s VLIW architecture as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
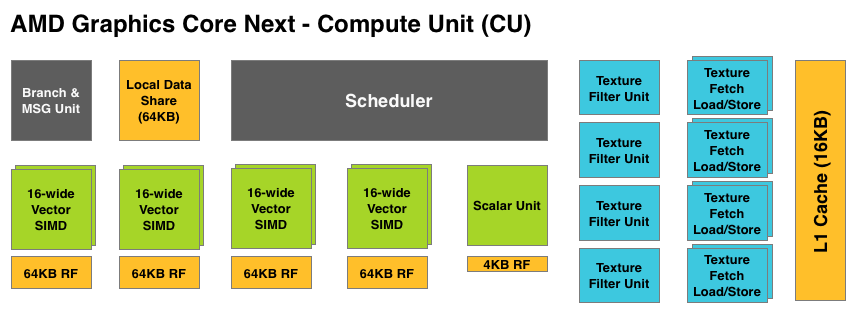
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).
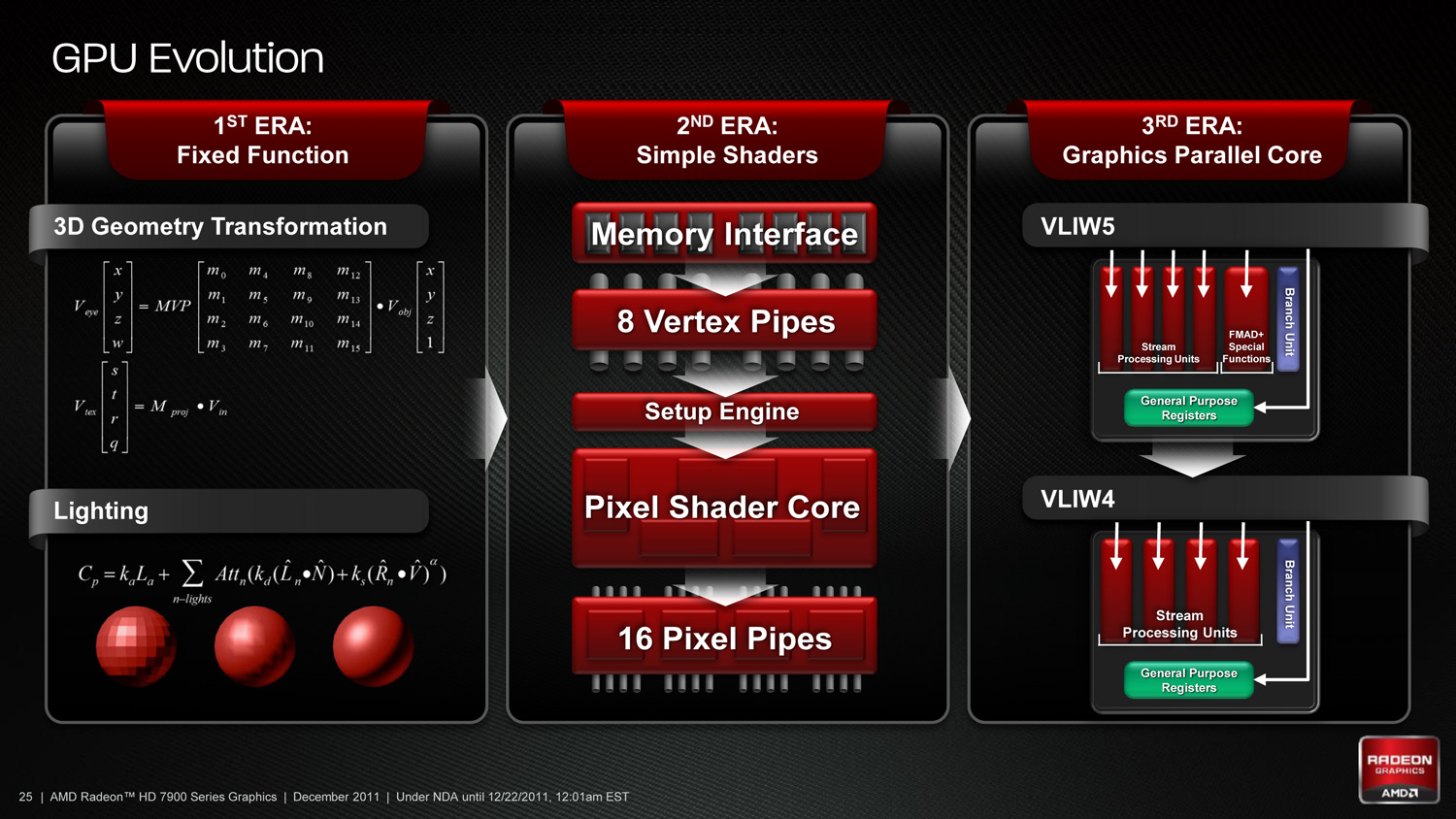
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
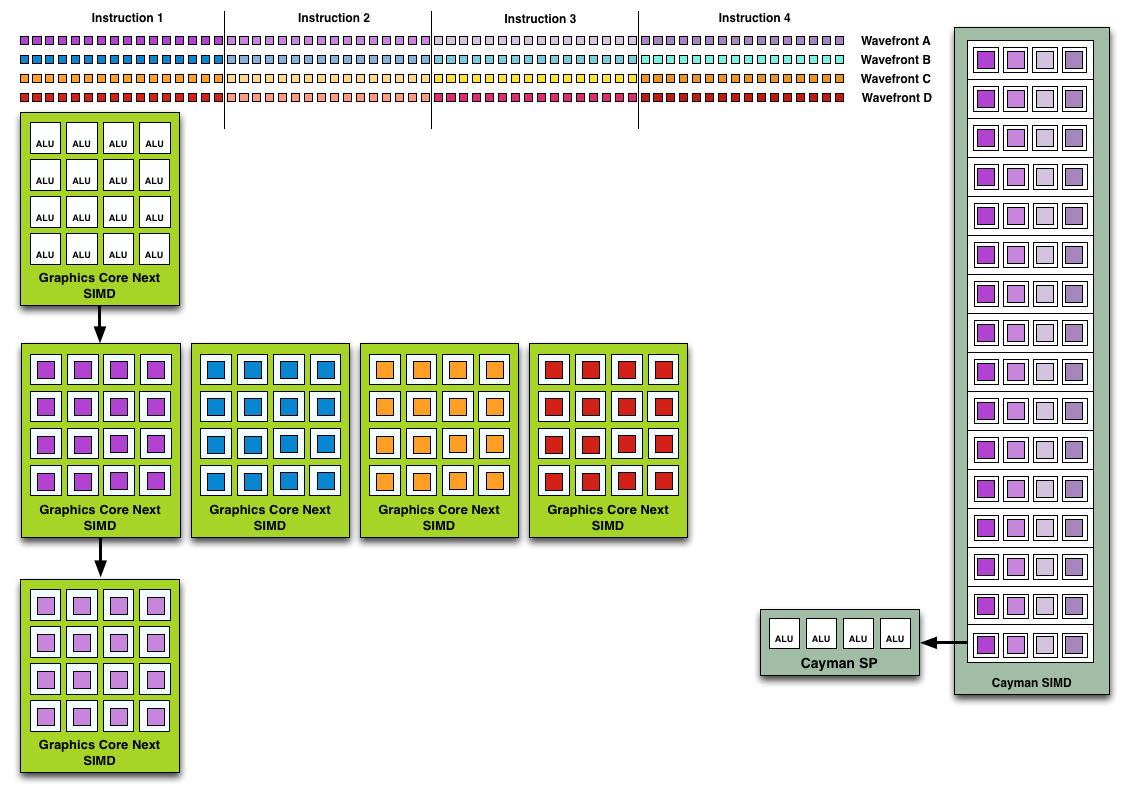
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup.
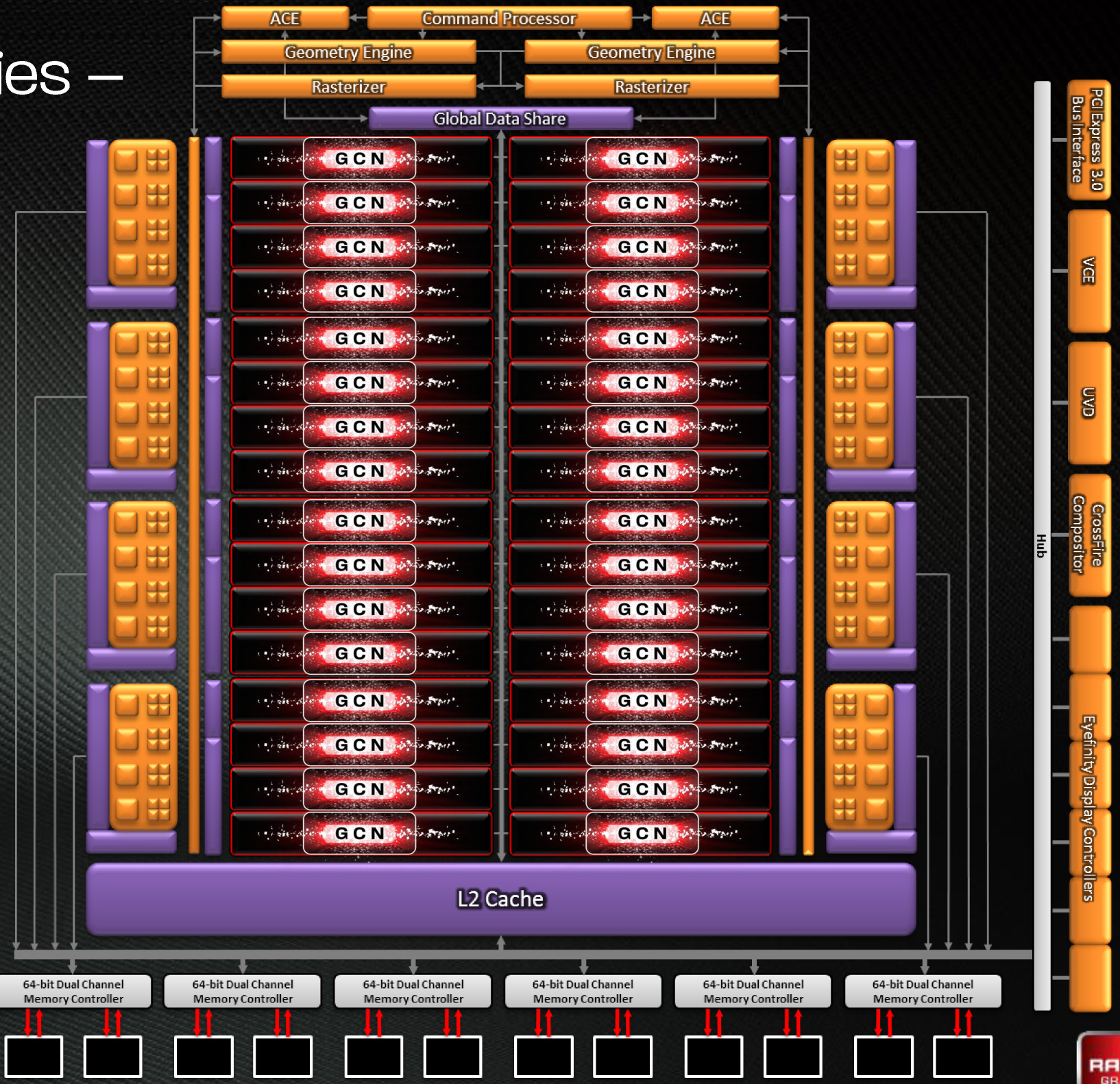
The ACEs are going to be particularly interesting to see in practice – we haven’t seen much evidence that AMD’s use of dual ACEs has had much of an impact in the consumer space, but things are a bit different in the professional space. Having two ACEs gives AMD the ability to work around some context switching performance issues, which is of importance for tasks that need steady graphics and compute performance at the same time. NVIDIA has invested in Maximus technology – Quadro + Tesla in a single system – for precisely this reason, and with the Kepler generation has made it near-mandatory as the Quadro K5000 is a compute-weak product. AMD takes a certain degree of pleasure in having a high-end GPU that can do both of these tasks well, and with the ACEs they may be able to deliver a Maximus-like experience with only a single card at a much lower cost.
Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
At the end of the day because AMD has done their homework GCN significantly improves AMD compute performance relative to VLIW4 while graphics performance should be just as good. Graphics shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing graphics performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








35 Comments
View All Comments
damianrobertjones - Tuesday, August 14, 2012 - link
Over the years I've always popped over to this page to read the latest news and especially articles yet over the last year, or maybe a bit more, the articles haven't exactly been flowing. is the site slowing down?:(
bobsmith1492 - Tuesday, August 14, 2012 - link
This engineer doesn't like the so-called "professional" cards. I think they are a rip-off. My high-end workstation computer came with a top-of-the-line Quadro and it could barely handle a second monitor. I finally got a mid-level gaming card and was much happier with its performance.A5 - Tuesday, August 14, 2012 - link
Then the card you got was broken. Even integrated graphics can handle 2D on 2 displays no problem.bobsmith1492 - Wednesday, August 15, 2012 - link
That's what I would have thought, but no. Even scrolling down an Excel document was slow, pausing every second to redraw the whole screen. Same thing when dragging a window around over a background that was "stretch to fit." Garbage! Tried modifying graphics settings, hardware acceleration on/off, Googling like mad, posts in the AT forums but no-go.wiyosaya - Tuesday, August 14, 2012 - link
100 percent agree with your assessment that the pro cards are a rip off. The chips are the same chips as in gaming cards. The only difference is a few switches in firmware that cut off options when run in gaming cards.That firmware is also developed by the same developers; I say this after having worked in a similar field where the company I worked for marketed RIP software designed to print to copiers. All the features were in the software, but customers had to pay sometimes substantially extra to enable some of those features. In my opinion, anyone who thinks that there is a separate team developing "pro" drivers is mistaken.
With a PC that has enough processing power, IMHO, most professionals will not need the "extra capabilities" that the pro cards offer over gaming cards. Perhaps the only reason a pro would need a pro card, if you believe the marketing coming out of the pro card realm, is because you are working with a model that has thousands of parts.
However, there is a recent trend to kill double precision compute power in gaming cards. IMHO, this is going to hurt graphics card makers more than it will help. It was for this reason that I avoided buying a GTX 680 and opted for a 580 instead for a recent build of mine.
nathanddrews - Tuesday, August 14, 2012 - link
Apparently it doesn't hurt them at all since they're making a lot of money with pro cards. All you have to do is show this to a CAD designer and you'l make sale:http://vimeo.com/user647522
aguilpa1 - Wednesday, August 15, 2012 - link
All these videos illustrate is that certain hardware accelerated features are turned off at the bios and software level. It is an illustration of intentional vender modifications of a piece of hardware to differentiate the two in order to improve the profit of the other.This was clearly illustrated in early versions of Quadros whereby a simple bios update would re-enable the turned off features of the consumer model. These methods may have been disabled by now by the vendor as they get wise to the ways of gamers.
rarson - Tuesday, August 14, 2012 - link
Wrong. With a professional card, you pay for both the validation and the software, neither of which are professional quality in the consumer variants."That firmware is also developed by the same developers"
Firmware and drivers are two different things, by the way.
wiyosaya - Thursday, August 16, 2012 - link
"Wrong. With a professional card, you pay for both the validation and the software, neither of which are professional quality in the consumer variants."The marketing departments have done their jobs very well or you are "pro vendor shill," IMHO as that is what the vendor wants everyone to think. As I previously stated, having been in more than one position where the companies that I worked for sell "professional" software, it is not the case.
I expect that most pro software packages will run on most gamer cards with very little difference except, perhaps, when pushing the pro software package to its absolute limit. If anyone wants to pay $4K for a $400 card, they are certainly welcome to do that. IMHO, it is a complete waste of money.
PrinceGaz - Sunday, August 19, 2012 - link
If you really are a professional graphics (or compute) user and would rather take the chance by opting for a non-validated $400 card instead of a fully-validated and backed by the hardware and software-vendor $4,000 card, then you have got your priorities wrong. That or you're being seriously underpaid for the sort of work you are doing.Your software vendor isn't going to be very impressed when you report a problem and they find the system you are running it on has a GeForce or Radeon card instead of one of the validated professional cards and driver versions supported by it!