Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM ESTNew NPU: Intel NPU 4, Up to 48 Peak TOPS
Perhaps Intel's main focal point, from a marketing point of view, is the latest generational change to its Neural Processing Unit or NPU.Intel has made some significant breakthroughs with its latest NPU, aptly called NPU 4. Although AMD disclosed a faster NPU during their Computex keynote, Intel claims up to 48 TOPS of peak AI performance.NPU 4, compared with the previous model, NPU 3, is a giant leap in enhancing power and efficiency in neural processing. The improvements in NPU 4 have been made possible by achieving higher frequencies, better power architectures, and a higher number of engines, thus giving it better performance and efficiency.

In NPU 4, these improvements are enhanced in vector performance architecture, with higher numbers of compute tiles and better optimality in matrix computations.This incurs a great deal of neural processing bandwidth; in other words, it is critical for applications that demand ultra-high-speed data processing and real-time inference. The architecture supports INT8 and FP16 precisions, with a maximum of 2048 MAC (multiply-accumulate) operations per cycle for INT8 and 1024 MAC operations for FP16, clearly showing a significant increase in computational efficiency.

A more in-depth look at the architecture reveals increased layering in the NPU 4. Each of the neural compute engines in this 4th version has an incredibly excellent inference pipeline embedded — comprising MAC arrays and many dedicated DSPs for different types of computing. The pipeline is built for numerous parallel operations, thus enhancing performance and efficiency. The new SHAVE DSP is optimized to four times the vector compute power it had in the previous generation, enabling more complex neural networks to be processed.

A significant improvement of NPU 4 is an increase in clock speed and introducing a new node that doubles the performance at the same power level as NPU 3. This results in peak performance quadrupling, making NPU 4 a powerhouse for demanding AI applications. The new MAC array features advanced data conversion capabilities on a chip, which allow for a datatype conversion on the fly, fused operations, and layout of the output data to make the data flow optimal with minimal latency.
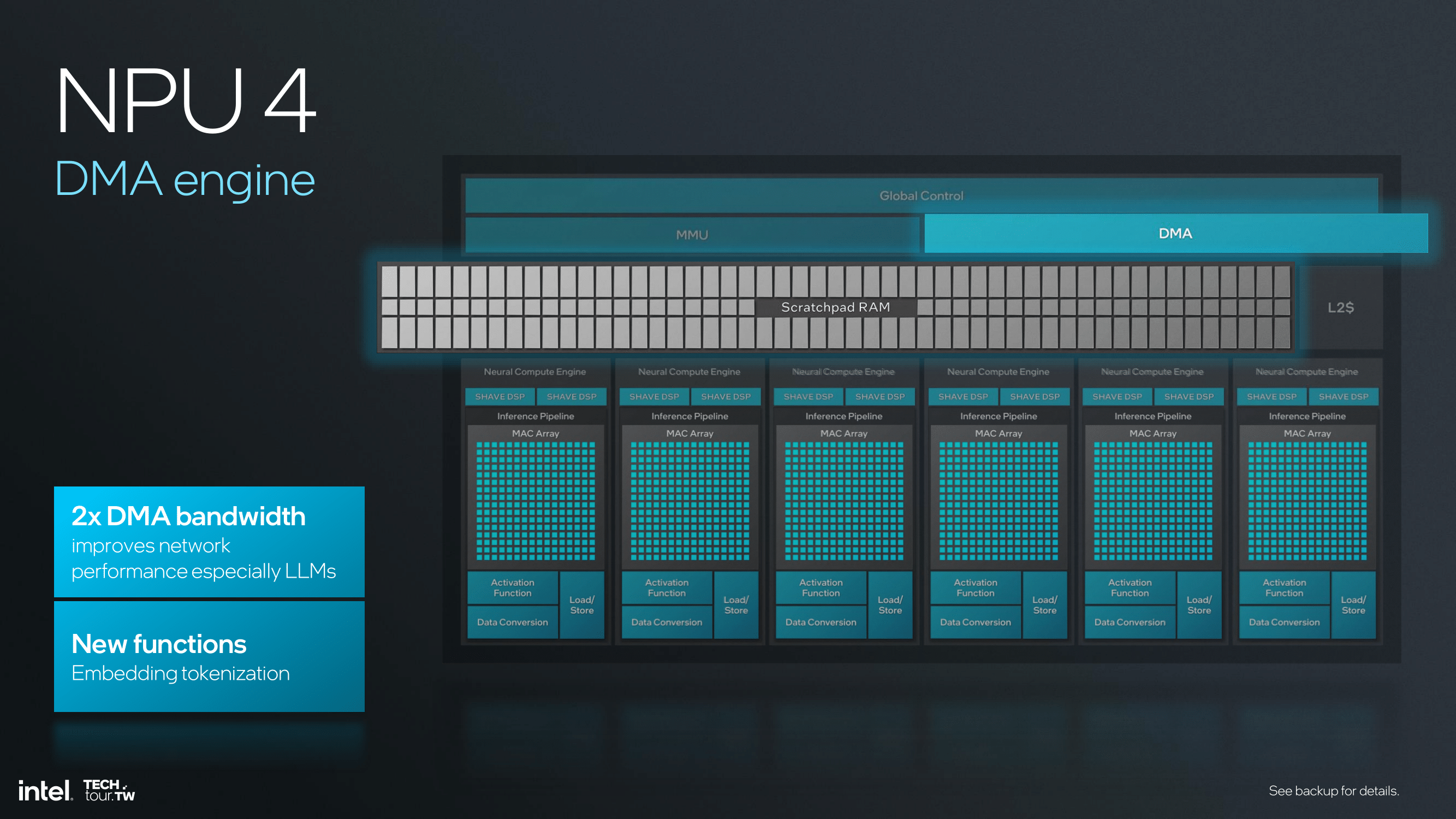
The bandwidth improvements in NPU 4 are essential to handle bigger models and data sets, especially in transformer language model-based applications. The architecture supports higher data flow, thus reducing the bottleneck and ensuring it runs smoothly even when in operation. The DMA (Direct Memory Access) engine of NPU 4 doubles the DMA bandwidth—an essential addition in improving network performance and an effective handler of heavy neural network models. More functions, including embedding tokenization, are further supported, expanding the potential of what NPU 4 can do.
The significant improvement of NPU 4 is in the matrix multiplication and convolutional operations, whereby the MAC array can process up to 2048 MAC operations in a single cycle for INT8 and 1024 for FP16. This, in turn, makes an NPU capable of processing much more complex neural network calculations at a higher speed and lower power. That makes a difference in the dimension of the vector register file; NPU 4 is 512-bit wide. This implies that in one clock cycle, more vector operations can be done; this, in turn, carries on the efficiency of the calculations.
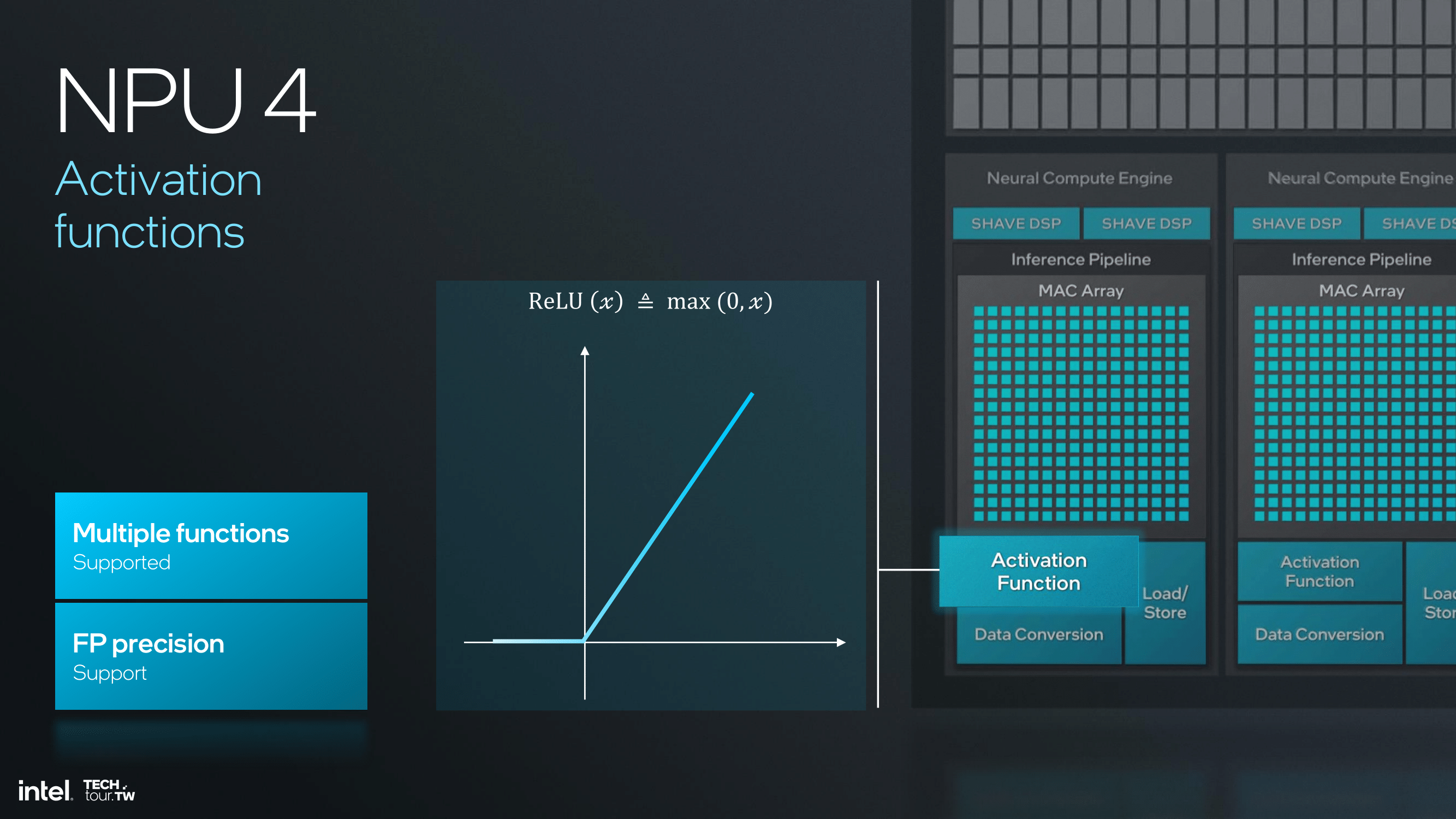
NPU 4 supports activation functions and a wider variety is available now that supports and treats any neural network, with the choice of precision to support the floating-point calculations, which should make the computations more precise and reliable. Improved activation functions and an optimized pipeline for inference will empower it to do more complicated and nuanced neuro-network models with much better speed and accuracy.
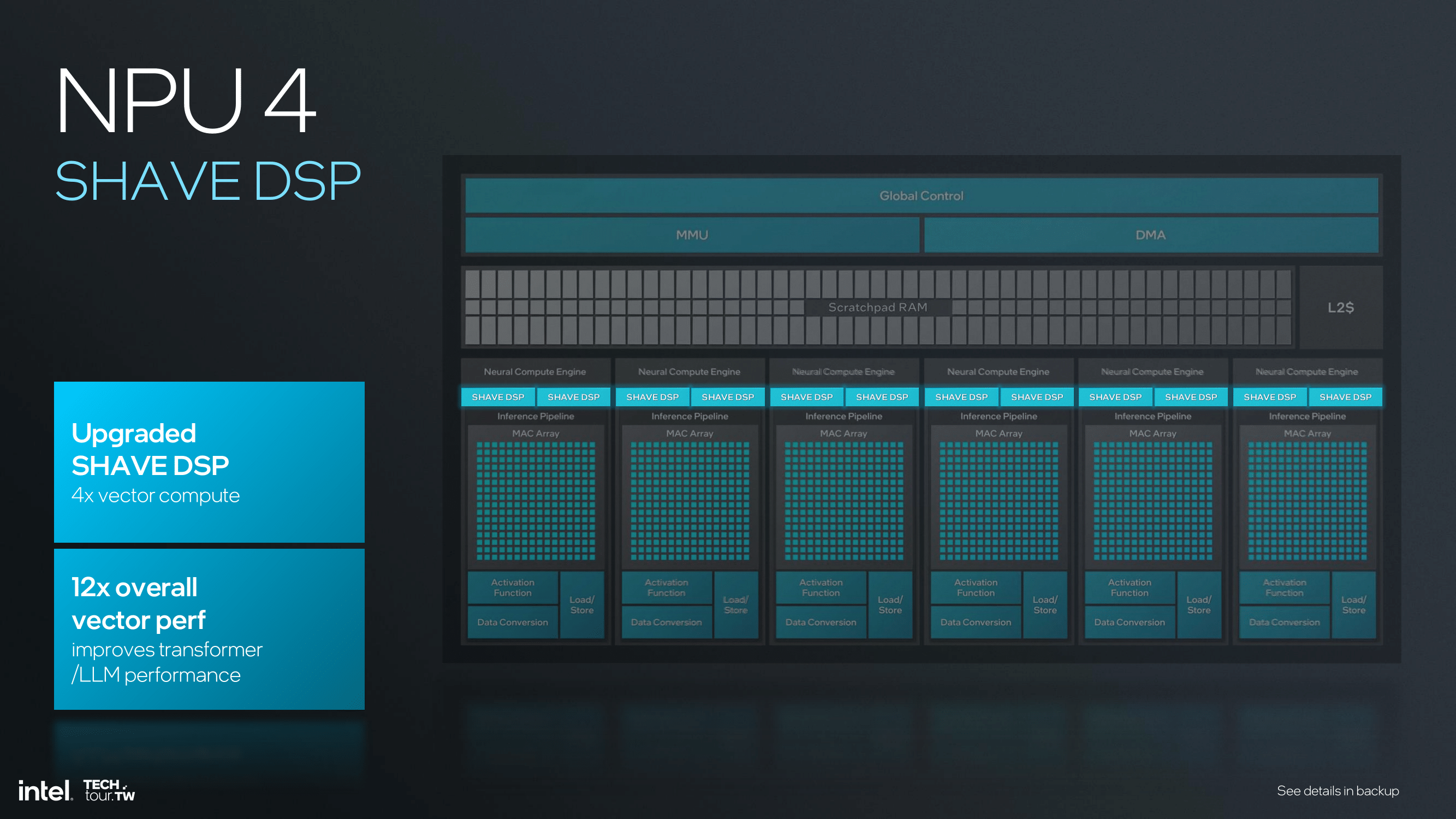
Upgrading to SHAVE DSP within NPU 4, with four times the vector compute power compared to NPU 3, will bring a 12x overall increase in vector performance. This would be most useful for transformer and large language model (LLM) performance, making it more prompt and energy efficient. Increasing vector operations per clock cycle enables the larger vector register file size, which significantly boosts the computation capabilities of NPU 4.
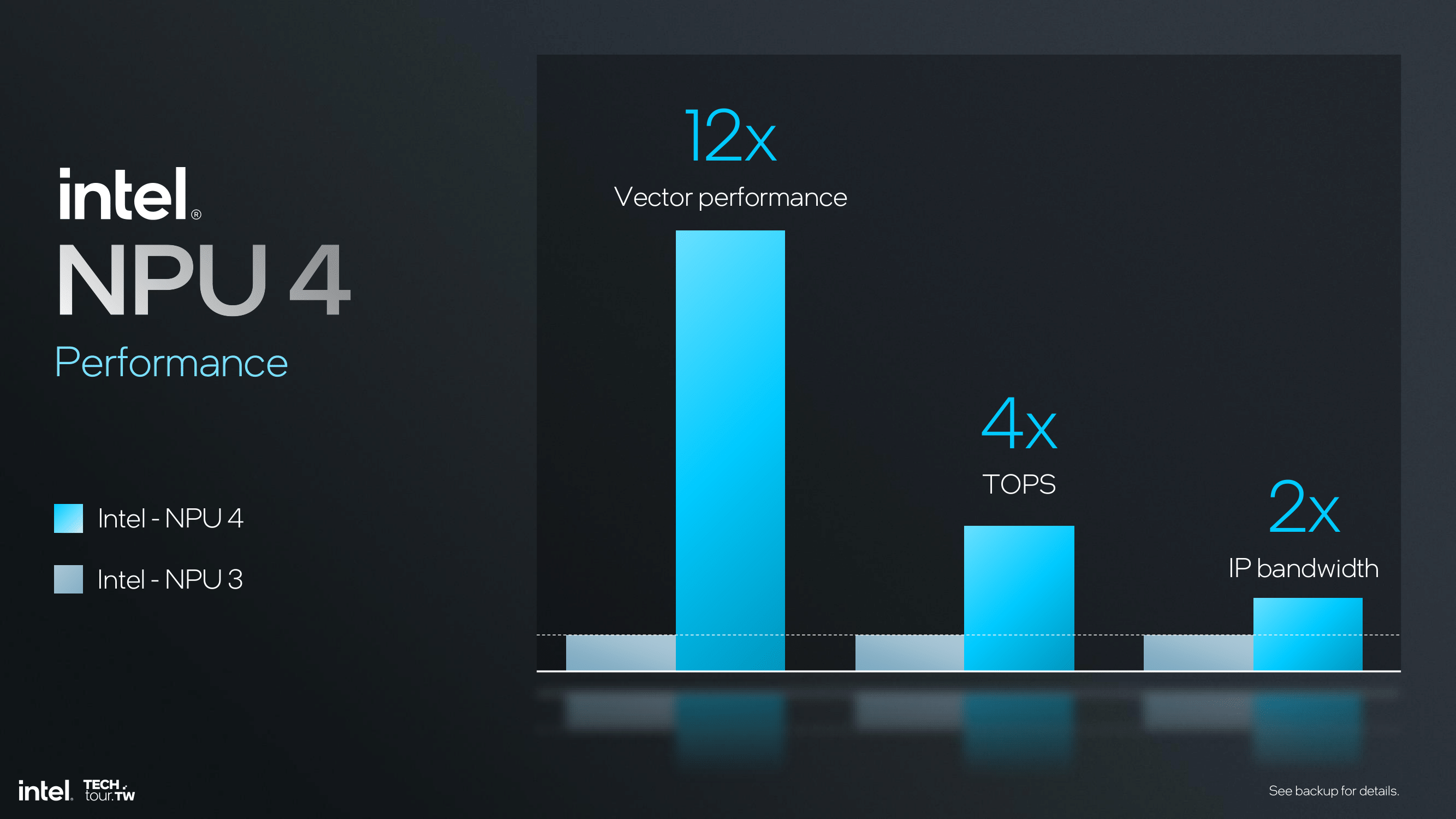
In general, NPU 4 presents a big performance jump over NPU 3, with 12 times vector performance, four times TOPS, and two times IP bandwidth. These improvements make NPU 4 a high-performing and efficient fit for up-to-date AI and machine learning applications where performance and latency are critical. These architectural improvements, along with steps in data conversion and bandwidth improvements, make NPU 4 the top-of-the-line solution for managing very demanding AI workloads.








91 Comments
View All Comments
thestryker - Monday, June 3, 2024 - link
I'm curious what the overall E-core performance is going to look like since the cluster won't have L3 cache access. Chips and Cheese did some analysis of the LP E-cores on MTL and found this specifically to be a big negative. I'm guessing this design is going to be limited to just LNL and is predominantly for the power savings.ET - Tuesday, June 4, 2024 - link
Interestingly, Intel is comparing Skymont to Raptor Cover. I agree that we have to wonder how the L3 (or lack thereof) affect this, but from the Chips and Cheese figures alongside Intel's performance improvement figures, it looks like Skymont without L3 cache will be faster than Crestmont with L3 cache.kwohlt - Tuesday, June 4, 2024 - link
There's 8MB of "SOC cache", separate from both the P and E cores, that should in practice function as the E cores' L3thestryker - Tuesday, June 4, 2024 - link
That's my assumption as well as I think the GPU would be the other part predominantly using it and they shouldn't really both be hitting it at the same time.sharath.naik - Monday, June 10, 2024 - link
Side cache is not the same as L3, or I think they would have called it that. shared L3 is where the memory sync can happen across cores. if not, it needs to go all the way back to ram. So, side caches really cannot be considered as L3, more like expanded L2 for E-core and expanded l3 for P-Core? is my guess. Yes, it means things that run on both E-Core and P-Core, at the same time, will take a hit on performance. I think they were targeting the majority use case. where most won't need more than 4 threads or threads won't be working on the same data.powerarmour - Thursday, June 6, 2024 - link
I can see this being an embarrassing launch if it gets slapped around by Qualcomm's SDx Elitemode_13h - Friday, June 7, 2024 - link
Well, they're on a better node that Qualcomm, so there's that.sharath.naik - Monday, June 10, 2024 - link
It absolutely will. Because this is going to be slower than meteor lake in CPU. Elite is supposed to be 30% faster. Intel should have released 8 P-core version to compete in performance. But I think they wanted to reserve that to be produced on their own fabs.lmcd - Monday, June 17, 2024 - link
Snap Elite is supposed to be 30% faster at essentially-undisclosed power. Lunar Lake will ironically undercut the Snapdragon Elite on power and cost while delivering good performance.Drumsticks - Tuesday, June 4, 2024 - link
I hate to ask this, but was this article fully written by Gavin and proof'ed by another editor? Was there a deadline push to get it out as soon as Intel released the information on Lunar Lake? It just reads so, so disjointed. It feels like there are so many issues in this paragraph alone on the P-core overview; it feels jarring to read."This Lion Cove architecture **also aligns with performance increases**, boasting a predicted double-digit bump in IPC over the older Redwood Cove generation. This uplift is noticed, especially **in the betterment of its hyper-threading, whereby improved IPC** by 30%, dynamic power efficiency improved by 20%, **and previous technologies, in balancing**, without increasing the core area, **in a commitment of Intel to better performance**, within existing physical constraints."
I've seen so much better work from Gavin, and Anandtech in general, that I almost hope that this page was heavily written by software. I know it's a press release, and there's not a whole lot of information, but the level of first party detail here feels similar to the Architecture Day 2021 presentations Intel did on Alder Lake, which got fantastic coverage from Andrei and Dr. Cuttress, and here it feels like we are getting a poorly worded restating of the slides with hardly any analysis or greater than surface level understanding.
I've been reading Anandtech since I was 15, and the level of detail in the Sandy Bridge era articles honestly had a huge influence on my choice to pursue a career in CPU Design. I've mountains of respect for what Anandtech has published in the past, but this article feels rushed.