Intel Core i9-13900K and i5-13600K Review: Raptor Lake Brings More Bite
by Gavin Bonshor on October 20, 2022 9:00 AM ESTCore-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
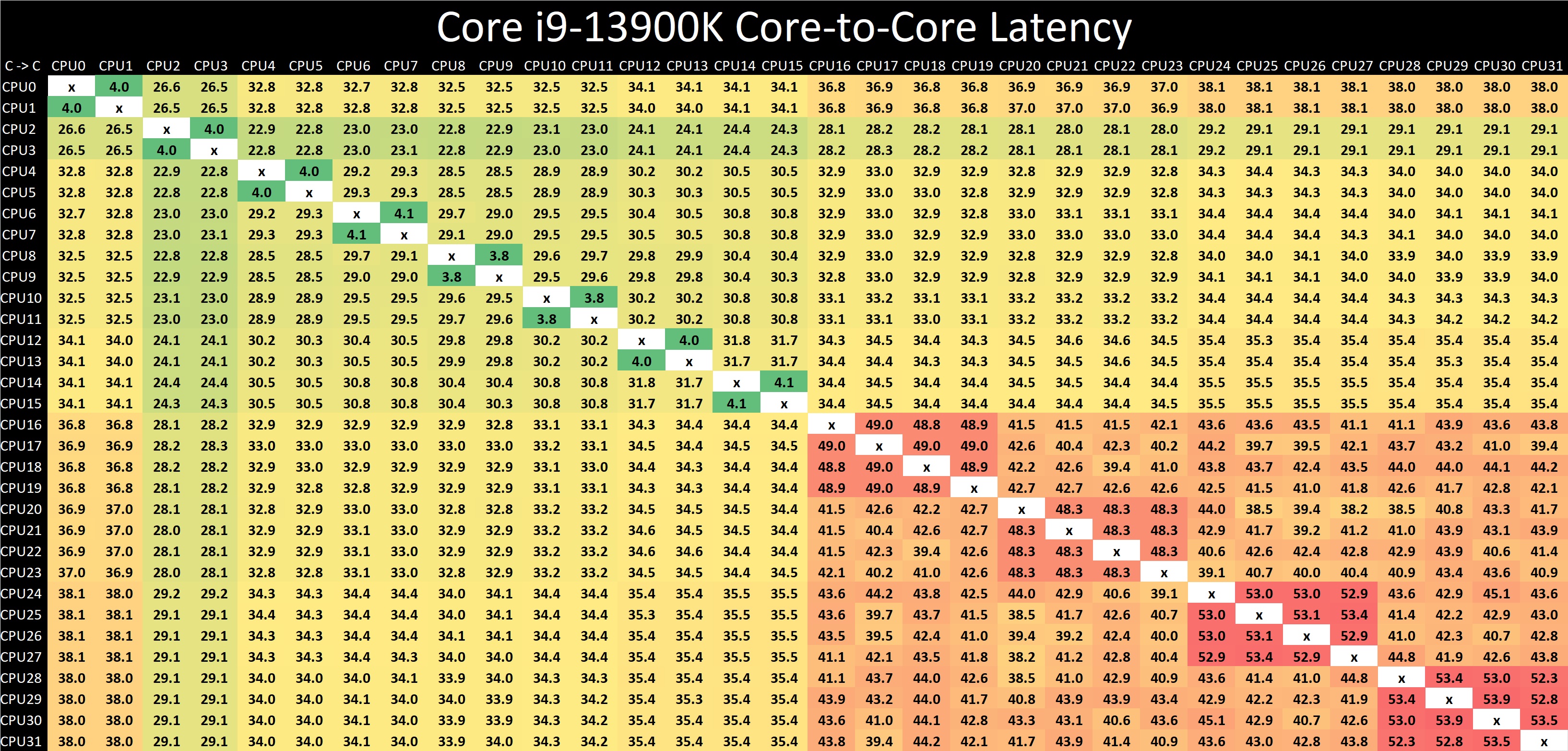
(Click on image to enlarge)
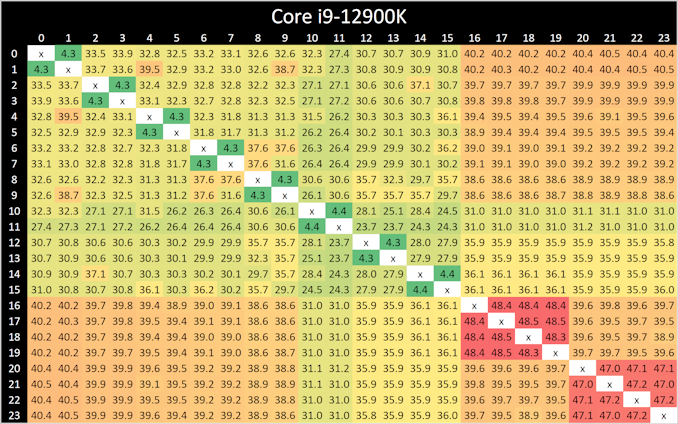
Looking at core-to-core latencies going from Alder Lake (12th Gen) to Raptor Lake (13th Gen), things look quite similar on the surface. The P-cores are listed within Windows 11 from cores 0 to 15, and in comparison to Alder Lake, latencies are much the same as what we saw when we reviewed the Core i9-12900K last year. The same comments apply here as with the Core i9-12900K, as we again see more of a bi-directional cache coherence.
Latencies between each Raptor Cove core have actually improved when compared to the Golden Cove cores on Alder Lake from 4.3/4.4 ns, down to 3.8/4.1 ns per each L1 access point.
The biggest difference is the doubling of the E-cores (Gracemont) on the Core i9-13900K, which as a consequence, adds more paths and crossovers. These paths do come with a harsher latency penalty than we saw with the Core i9-12900K, with latencies around the E-cores ranging from 48 to 54 ns within four core jumps between them; this is actually slower than it was on Alder Lake.
One possible reason for the negative latency is the 200 MHz reduction in base frequency on the Gracemont cores on Raptor Lake when compared with Alder Lake. When each E-core (Gracemont) core is communicating with each other, they travel through the L2 cache clusters via the L3 cache ring and back again, which does seem quite an inefficient way to go.








169 Comments
View All Comments
Nero3000 - Thursday, October 20, 2022 - link
Correction: the 12600k is 6P+4E - table on first pageHixbot - Thursday, October 20, 2022 - link
I am hoping for an high frequency 8 core i5 with zero ecores and high cache. It's would be a gamer sweet spot, and could counter the inevitable 3d cache Zen 4.nandnandnand - Friday, October 21, 2022 - link
big.LITTLE isn't going away. It's in a billion smartphones, and it will be in most of Intel's consumer CPUs going forward.Just grab your 7800X3D, before AMD does its own big/small implementation with Zen 5.
HarryVoyager - Friday, October 21, 2022 - link
Honestly, I'm underwhelmed by Intel's current big.LITTLE setup. As near as I can tell, under load the E cores are considerably less efficient than the P cores are, and currently just seem to be there so Intel can claim multi-threading victories with less die space.And with the CPU's heat limits, it just seems to be pushing the chip into thermal throttling even faster.
Hopefully future big.LITTLE implementations are better.
nandnandnand - Friday, October 21, 2022 - link
Meteor Lake will bring Redwood Cove to replace Golden/Raptor Cove, and Crestmont to replace Gracemont. Gracemont in Raptor Lake is the same as in Alder Lake except for more cache, IIRC. All of this will be on "Intel 4" instead of "Intel 7", and the core count might be 8+16 again.Put it all together and it should have a lot of breathing room compared to the 13900K(S).
8+32 will be the ultimate test of small cores, but they're already migrating on down to the cheaper chips like the 13400/13500.
Hixbot - Saturday, October 22, 2022 - link
Yes it does seem backwards that the more efficient architecture is in the P core. Reducing power consumption for light tasks seems better to keep it on the P core and downclock. I don't see the point of the "e" cores as effiency, but rather academic multithreaded benchmark war. Which isn't serving the consumer at all.deil - Monday, October 24, 2022 - link
E is still useful, as you get 8/8 cores in space where you could cram 2/4. I agree E for efficiency should be B as background to make it clearer what's the point. They are good for consumers as they offer all the high speed cores for main process, so OS and other things dont slow down.I am not sure if you followed, but intel cpu's literally doubled in power since they appeared, and at ~25% utilization, cpu's halved power usage. What you should complain about is bad software support, as this is not something that happens in the background.
TEAMSWITCHER - Monday, October 24, 2022 - link
I don't think you are fully grasping the results of the benchmarks. Compute/Rendering scores prove that e-cores can tackle heavy work loads. Often trading blows with AMD's all P-Core 7950X, and costing less at the same time. AMD needs to lower all prices immediately.haoyangw - Monday, October 24, 2022 - link
That's an oversimplification actually, P-cores and E-cores are both efficient, just for different tasks. The main efficiency gain of P-cores is it's much much faster than E-cores for larger tasks. Between 3 and 4GHz, P-cores are so fast they finish tasks much earlier than e-cores so total energy drawn is lower. But E-cores are efficient too, just for simple tasks(at low clockspeeds). Below 3GHz and above 1GHz, e-cores are much more efficient, beating P-cores in performance while drawing less power.Source: https://chipsandcheese.com/2022/01/28/alder-lakes-...
Great_Scott - Friday, November 25, 2022 - link
Big.LITTLE is hard to do, and ARM took ages and a lot of optimization before phone CPUs got much benefit from it.The problem of the LITTLE cores not adding anything in the way of power efficiency is well-known.
I'm saddened that Intel is dropping their own winning formula of "race-to-sleep" that they've successfully used for decades for aping something objectivly worse because they're a little behind in die shrinking.