A Broadwell Retrospective Review in 2020: Is eDRAM Still Worth It?
by Dr. Ian Cutress on November 2, 2020 11:00 AM ESTCPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk)
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 speed-1, and SPEC2017 speed-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
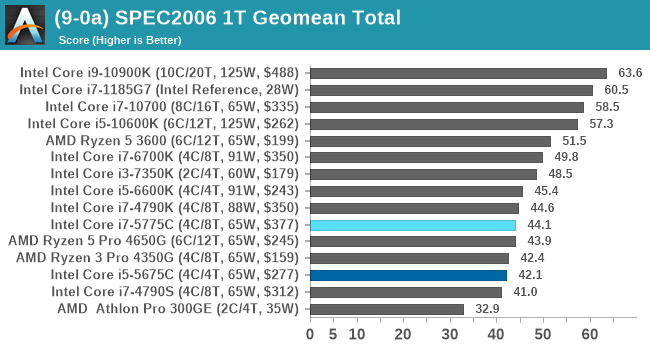
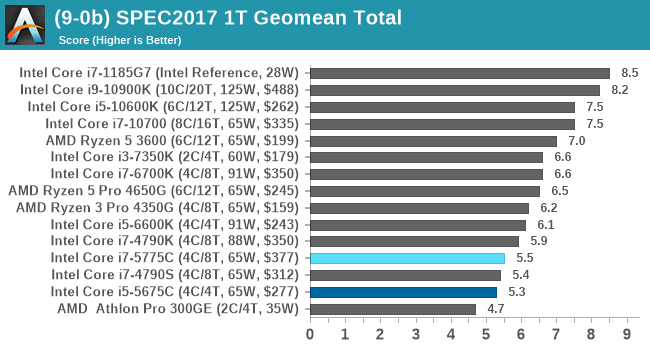
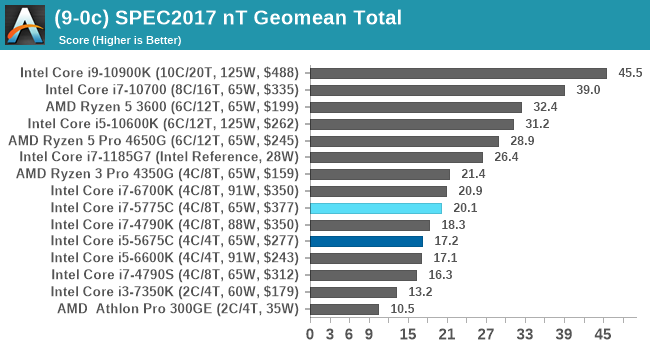
There are some specific tests that the eDRAM gets a sizeable boost in performance for, such as 471.omnetpp in SPEC2006 (+23% over 6700K). The main gains are in SPEC2017 nT, in 510.parest_r (+49%), 519.lbm_r (+63%), and 554.roms_r (+46%). However, the lower power and lower frequency still hamper the processors in a lot of scenarios.








120 Comments
View All Comments
realbabilu - Monday, November 2, 2020 - link
That Larger cache maybe need specified optimized BLAS.Kurosaki - Monday, November 2, 2020 - link
Did you mean BIAS?ballsystemlord - Tuesday, November 3, 2020 - link
BLAS == Basic Linear Algebra System.Kamen Rider Blade - Monday, November 2, 2020 - link
I think there is merit to having Off-Die L4 cache.Imagine the low latency and high bandwidth you can get with shoving some stacks of HBM2 or DDR-5, whichever is more affordable and can better use the bandwidth over whatever link you're providing.
nandnandnand - Monday, November 2, 2020 - link
I'm assuming that Zen 4 will add at least 2-4 GB of L4 cache stacked on the I/O die.ichaya - Monday, November 2, 2020 - link
Waiting for this to happen... have been since TR1.nandnandnand - Monday, November 2, 2020 - link
Throw in an RDNA 3 chiplet (in Ryzen 6950X/6900X/whatever) for iGPU and machine learning, and things will get really interesting.ichaya - Monday, November 2, 2020 - link
Yep.dotjaz - Saturday, November 7, 2020 - link
That's definitely not happening. You are delusional if you think RDNA3 will appear as iGPU first.At best we can hope the next I/O die to intergrate full VCN/DCN with a few RDNA2 CUs.
dotjaz - Saturday, November 7, 2020 - link
Also doubly delusional if think think RDNA3 is any good for ML. CDNA2 is designed for that.Adding powerful iGPU to Ryzen 9 servers literally no purpose. Nobody will be satisfied with that tiny performance. Guaranteed recipe for instant failure.
The only iGPU that would make sense is a mini iGPU in I/O die for desktop/video decoding OR iGPU coupled with low end CPU for an complete entry level gaming SOC aka APU. Chiplet design almost makes no sense for APU as long as GloFo is in play.