Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM ESTNew NPU: Intel NPU 4, Up to 48 Peak TOPS
Perhaps Intel's main focal point, from a marketing point of view, is the latest generational change to its Neural Processing Unit or NPU.Intel has made some significant breakthroughs with its latest NPU, aptly called NPU 4. Although AMD disclosed a faster NPU during their Computex keynote, Intel claims up to 48 TOPS of peak AI performance.NPU 4, compared with the previous model, NPU 3, is a giant leap in enhancing power and efficiency in neural processing. The improvements in NPU 4 have been made possible by achieving higher frequencies, better power architectures, and a higher number of engines, thus giving it better performance and efficiency.

In NPU 4, these improvements are enhanced in vector performance architecture, with higher numbers of compute tiles and better optimality in matrix computations.This incurs a great deal of neural processing bandwidth; in other words, it is critical for applications that demand ultra-high-speed data processing and real-time inference. The architecture supports INT8 and FP16 precisions, with a maximum of 2048 MAC (multiply-accumulate) operations per cycle for INT8 and 1024 MAC operations for FP16, clearly showing a significant increase in computational efficiency.

A more in-depth look at the architecture reveals increased layering in the NPU 4. Each of the neural compute engines in this 4th version has an incredibly excellent inference pipeline embedded — comprising MAC arrays and many dedicated DSPs for different types of computing. The pipeline is built for numerous parallel operations, thus enhancing performance and efficiency. The new SHAVE DSP is optimized to four times the vector compute power it had in the previous generation, enabling more complex neural networks to be processed.

A significant improvement of NPU 4 is an increase in clock speed and introducing a new node that doubles the performance at the same power level as NPU 3. This results in peak performance quadrupling, making NPU 4 a powerhouse for demanding AI applications. The new MAC array features advanced data conversion capabilities on a chip, which allow for a datatype conversion on the fly, fused operations, and layout of the output data to make the data flow optimal with minimal latency.
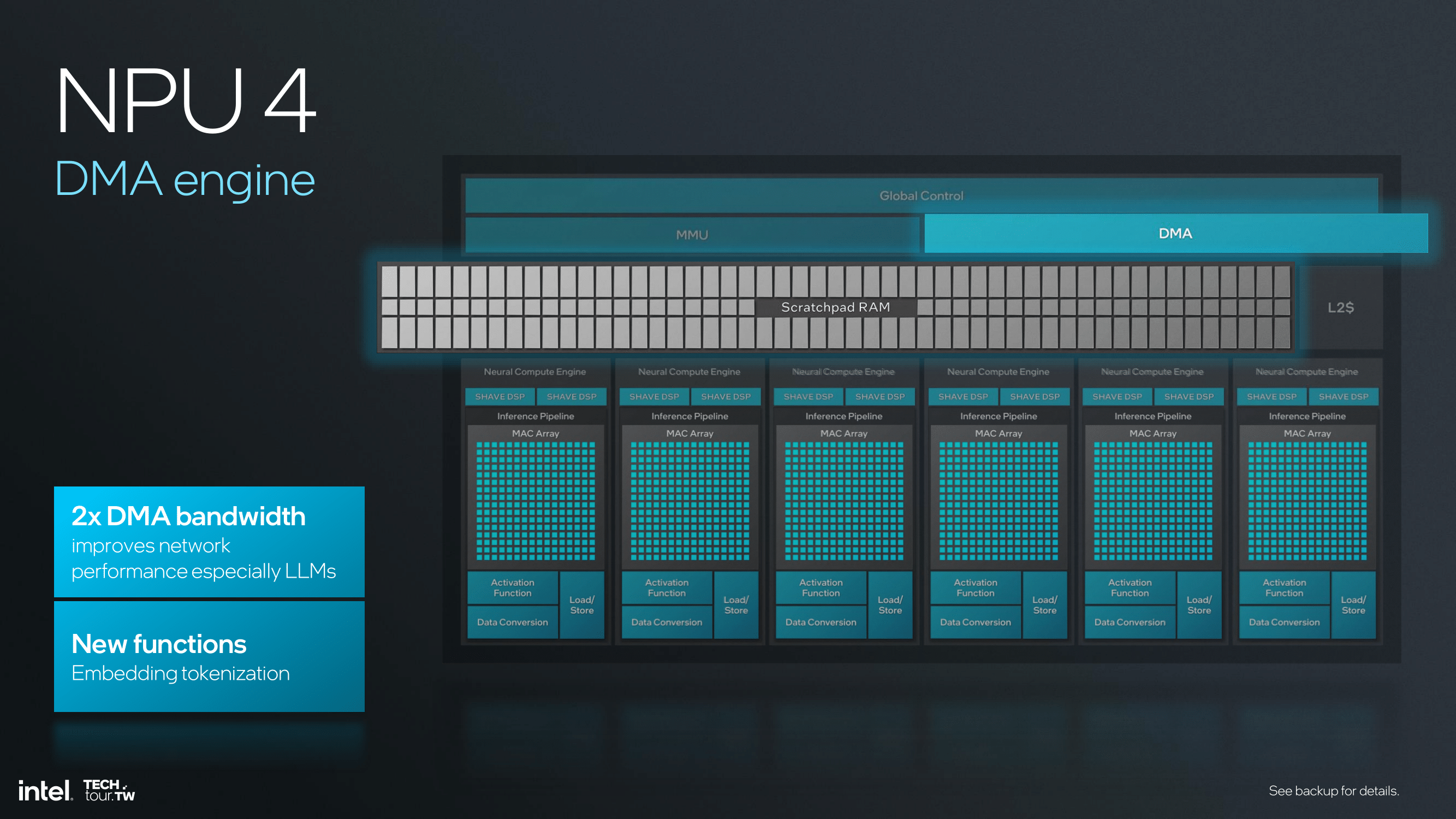
The bandwidth improvements in NPU 4 are essential to handle bigger models and data sets, especially in transformer language model-based applications. The architecture supports higher data flow, thus reducing the bottleneck and ensuring it runs smoothly even when in operation. The DMA (Direct Memory Access) engine of NPU 4 doubles the DMA bandwidth—an essential addition in improving network performance and an effective handler of heavy neural network models. More functions, including embedding tokenization, are further supported, expanding the potential of what NPU 4 can do.
The significant improvement of NPU 4 is in the matrix multiplication and convolutional operations, whereby the MAC array can process up to 2048 MAC operations in a single cycle for INT8 and 1024 for FP16. This, in turn, makes an NPU capable of processing much more complex neural network calculations at a higher speed and lower power. That makes a difference in the dimension of the vector register file; NPU 4 is 512-bit wide. This implies that in one clock cycle, more vector operations can be done; this, in turn, carries on the efficiency of the calculations.
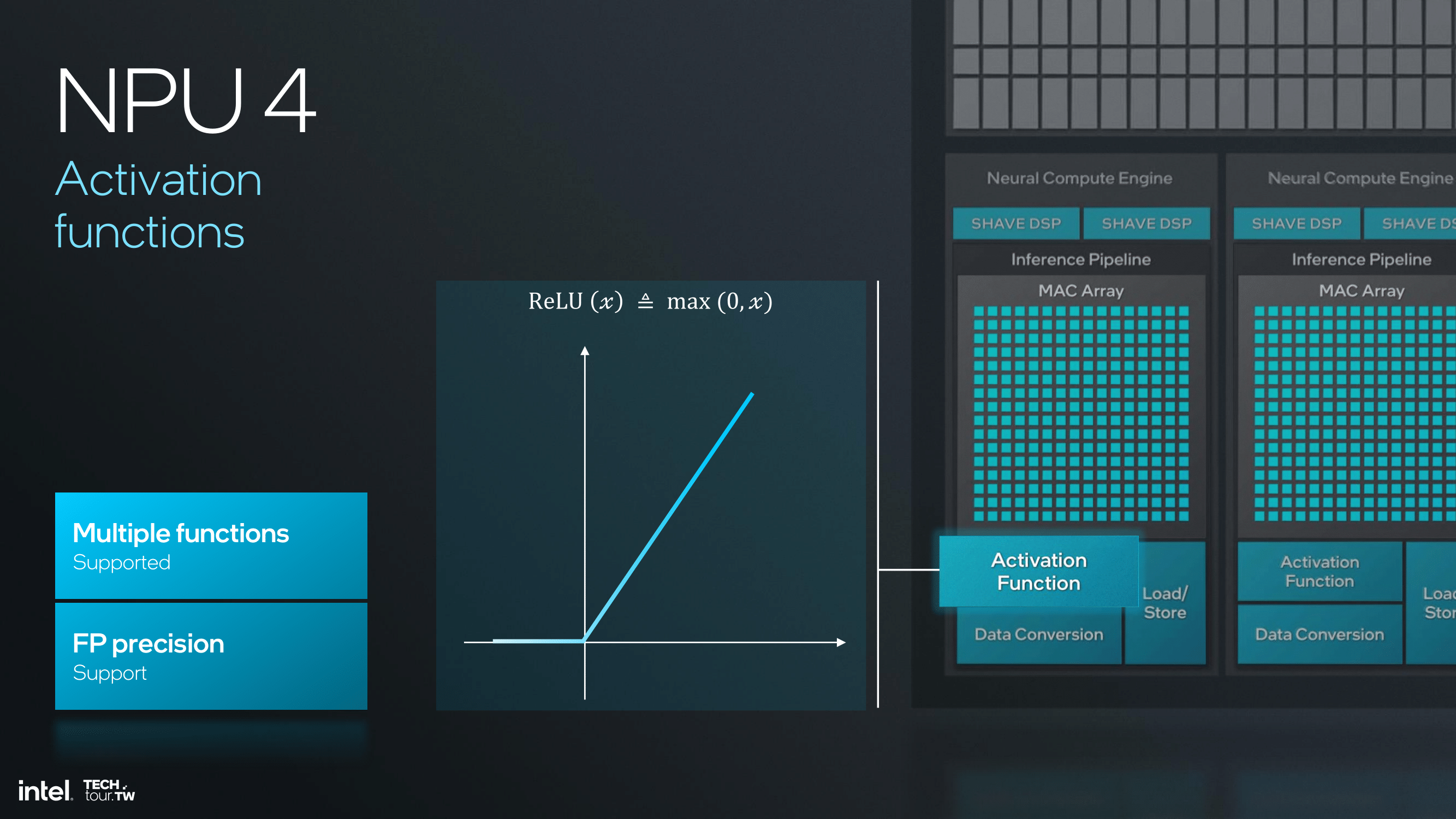
NPU 4 supports activation functions and a wider variety is available now that supports and treats any neural network, with the choice of precision to support the floating-point calculations, which should make the computations more precise and reliable. Improved activation functions and an optimized pipeline for inference will empower it to do more complicated and nuanced neuro-network models with much better speed and accuracy.
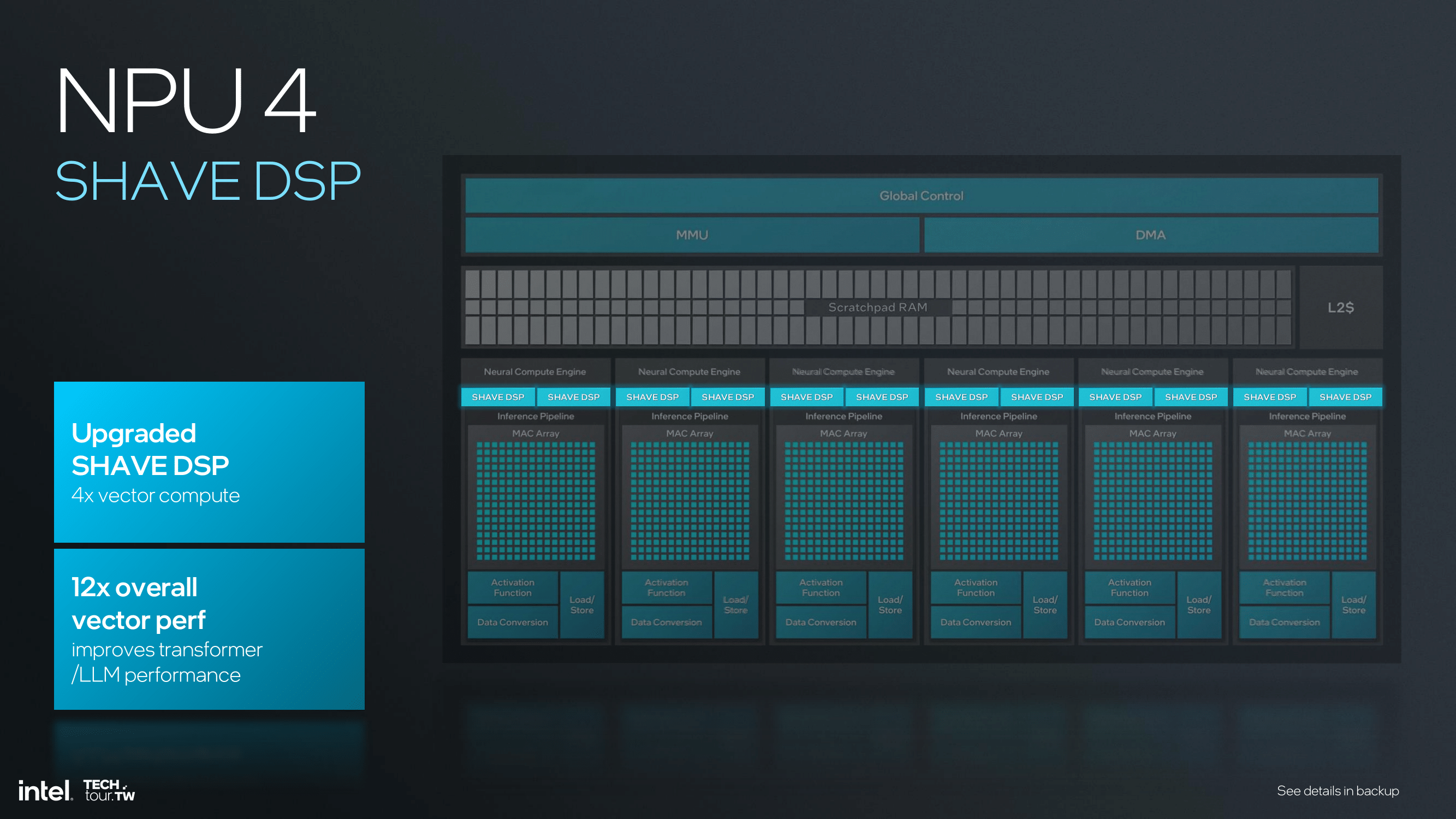
Upgrading to SHAVE DSP within NPU 4, with four times the vector compute power compared to NPU 3, will bring a 12x overall increase in vector performance. This would be most useful for transformer and large language model (LLM) performance, making it more prompt and energy efficient. Increasing vector operations per clock cycle enables the larger vector register file size, which significantly boosts the computation capabilities of NPU 4.
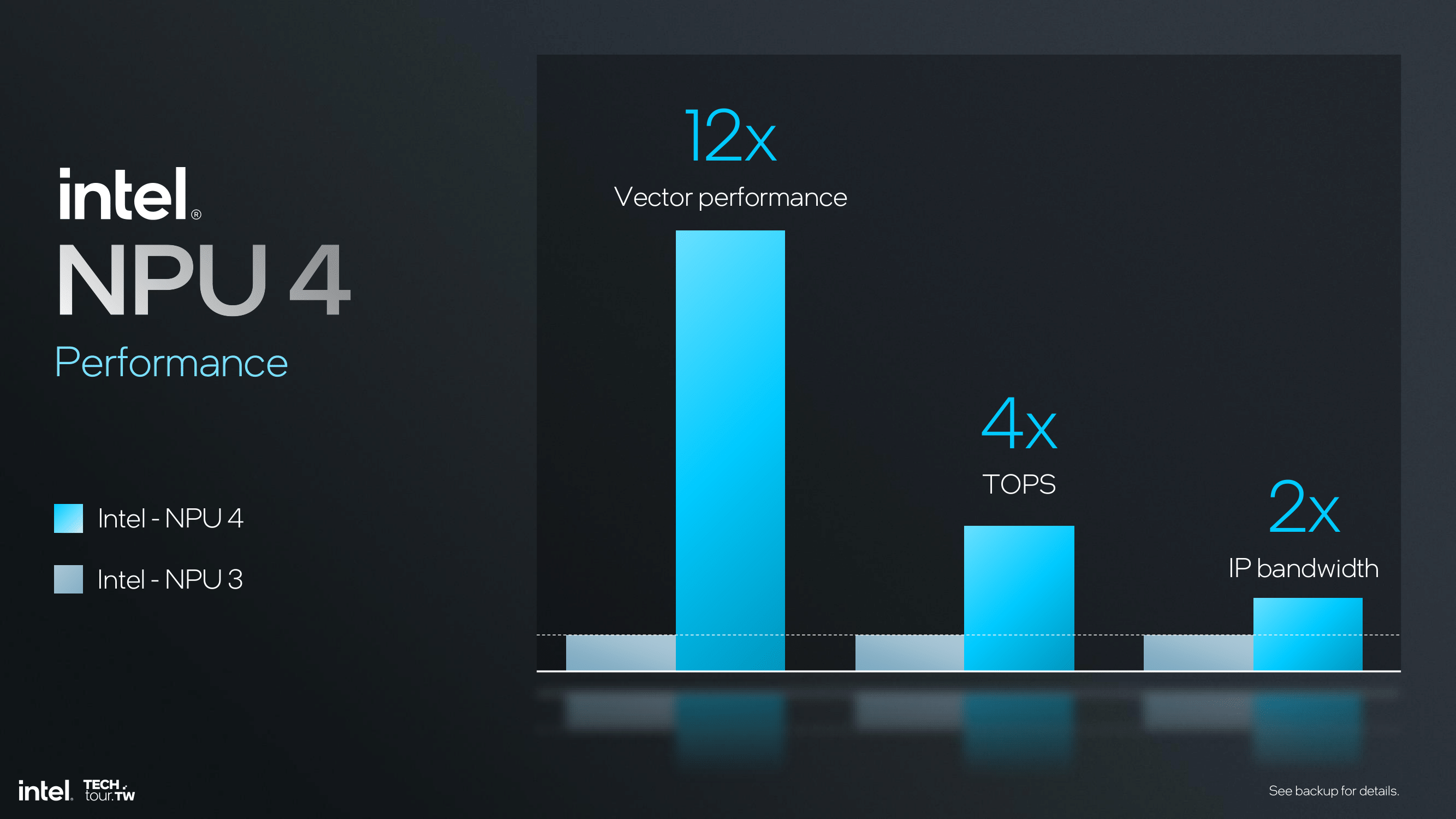
In general, NPU 4 presents a big performance jump over NPU 3, with 12 times vector performance, four times TOPS, and two times IP bandwidth. These improvements make NPU 4 a high-performing and efficient fit for up-to-date AI and machine learning applications where performance and latency are critical. These architectural improvements, along with steps in data conversion and bandwidth improvements, make NPU 4 the top-of-the-line solution for managing very demanding AI workloads.








91 Comments
View All Comments
Silver5urfer - Tuesday, June 4, 2024 - link
Disaster for Intel. Finally they folded. Intel fabs are now not even used for their high volume BGA junk processors. Instead using TSMC.Second thing is as everyone pointed out they are comparing LP-E to E cores lol to inflate the graphs. Also the IPC is meager at best, Raptor Cove is faster than Meteor one and they are using that figure.
ARL will lack HT on top of this reduced clockrate, interesting times ahead for Desktop battle. Reply
Drumsticks - Tuesday, June 4, 2024 - link
They aren’t comparing LP E-Cores to E-Cores. LNL E-cores are separated from the LLC, same as MTL island cores. It’s an apt comparison.On the flip side, the comparison to Raptor cove is with E-cores connected to the LLC and ring bus, just as Raptor cove would be. It’s also an apt comparison. You’ll see island E-cores only on LNL (because of the power advantages) and ring bus connected E-cores on Arrow Lake (because of the performance advantages). Reply
Kangal - Wednesday, June 5, 2024 - link
I don't know, but I am pretty underwhelmed.Intel is the least trusted tech giant, even Nvidia look better when it comes to honesty.
Here it seems like Intel took two steps forward, and three steps back. They are probably at a loss in either pricing, efficiency, or performance. Or more likely all three. That's why they use smoke and mirrors and try to trick the viewers/shareholders with the technicalities.
It's not like AMD didn't do the same, but they stand behind their technology, and actually showcased real products. And they also gave benchmarks. That's how you know they are confident.
It seems the CPU and GPU space is going to be a bloodbath for Intel. And we need all the competition we can get. But it is a little amusing to seeing Intel squirm. Ironically Intel is going the way of Bulldozer (shared cores) whilst AMD is sticking with Hyperthreading (extra bits per core) design. It's only amusing because Intel did unethical and illegal business practices that led to AMDs bankruptcy more than a decade ago. Microsoft is also complicit in that.
Reply
Terry_Craig - Wednesday, June 5, 2024 - link
Sounds like an intel employee. People care about performance, not excuses, the problem with the comparison is that the LP-E cores are much inferior to the already deficient E-Cores.https://chipsandcheese.com/2024/05/20/comparing-cr... Reply
Drumsticks - Tuesday, June 11, 2024 - link
Not sure if this was a reply to me because of page breaks, but if it was, what about what I said is untrue or biased?From the (excellent, by the way) Chips article: "I wonder if Intel could give low power Crestmont a larger L2 cache, or even drop some blocks on Meteor Lake’s SoC tile to make room for a system level cache." - this is exactly what was done in Lunar Lake. The LNL E-Cores don't access the same L3 as the P-Cores, but there's an 8MB System level cache that they can access (that the rest of the chip also can I think, P-Cores, GPU, and NPU included). That probably is a big part of the giant 40-70% performance gain they show.
And E-Cores connected to the ring bus ARE much better, by Intel's own admission and by, again, the Chips article. Skymont E-Cores coming to ARL are (presumably) on the ring bus, and should punch much better than LNL E-Cores because of it.
None of this means that Intel's design is the best, or that it's not going to fall flat. That devil is still in the details, which Intel still needs to give to us. But I'm not sure how we can argue that the explicit details of the implementation are somehow biased or an excuse. That IS how Intel designed the chip; whether or not it is a good design remains to be seen. IMO, it seems like a pretty decent concept, but we'll have to see how much power the new P-Cores are really saving. With a 4P+4e design, they will need to be pretty efficient to match what Zen 5 will be up to, even in low power setups. (I assume 15W and above will get an arrow lake design that has more p cores and/or E cores on the ring bus). Reply
Drumsticks - Tuesday, June 11, 2024 - link
One other thought - based on the Chips and Cheese article, LP E-Cores seem to be anywhere from 10-30% slower without access to an L3 cache. That Intel is calling out a 40-70% gain in Skymont LPE core performance over Crestmont LP-E is pretty noteworthy if nothing else. Even at their 10% (which is nuts) margin of error, the LPE core Skymont cores (albeit at least with access to a system cache) are as fast as Crestmont cores with a full blown 24MB L3 cache.Again, benchmarks are king, but assuming Skymont LP-E is bad because Crestmont LP-E was bad seems like a poor assumption given the underlying conditions are completely different. Reply
GeoffreyA - Tuesday, June 4, 2024 - link
On the P side, most interesting is Lion Cove's moving to a split-scheduler design, saying good-bye to their classic unified approach there since the P6. AMD, always thinking ahead, has been using the split scheduler since the Athlon. ReplyBlastdoor - Tuesday, June 4, 2024 - link
This really looks like a SOC made for a MacBook Air. Replylmcd - Wednesday, June 12, 2024 - link
Or intended to beat out Snapdragon Elite if its date didn't slip. ReplyNextGen_Gamer - Tuesday, June 4, 2024 - link
With confirmation that the entire compute tile is made on TSMC's N3B process, I guess we can take that to mean Intel was not super confident in mass yields on its own 20A process. Intel's 20A will be used in Arrow Lake, the desktop equivalent to Lunar Lake. Desktop shipments are a small fraction of laptop chips nowadays, so that makes sense. This does create a really interesting opportunity that I hope Anandtech will explore, where you could take a desktop Arrow Lake processor, disable enough P-cores and E-cores to make it equal to Lunar Lake, and see how they compare. Same architectures, but one on TSMC N3B versus Intel 20A. Reply