Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM ESTNew NPU: Intel NPU 4, Up to 48 Peak TOPS
Perhaps Intel's main focal point, from a marketing point of view, is the latest generational change to its Neural Processing Unit or NPU.Intel has made some significant breakthroughs with its latest NPU, aptly called NPU 4. Although AMD disclosed a faster NPU during their Computex keynote, Intel claims up to 48 TOPS of peak AI performance.NPU 4, compared with the previous model, NPU 3, is a giant leap in enhancing power and efficiency in neural processing. The improvements in NPU 4 have been made possible by achieving higher frequencies, better power architectures, and a higher number of engines, thus giving it better performance and efficiency.

In NPU 4, these improvements are enhanced in vector performance architecture, with higher numbers of compute tiles and better optimality in matrix computations.This incurs a great deal of neural processing bandwidth; in other words, it is critical for applications that demand ultra-high-speed data processing and real-time inference. The architecture supports INT8 and FP16 precisions, with a maximum of 2048 MAC (multiply-accumulate) operations per cycle for INT8 and 1024 MAC operations for FP16, clearly showing a significant increase in computational efficiency.

A more in-depth look at the architecture reveals increased layering in the NPU 4. Each of the neural compute engines in this 4th version has an incredibly excellent inference pipeline embedded — comprising MAC arrays and many dedicated DSPs for different types of computing. The pipeline is built for numerous parallel operations, thus enhancing performance and efficiency. The new SHAVE DSP is optimized to four times the vector compute power it had in the previous generation, enabling more complex neural networks to be processed.

A significant improvement of NPU 4 is an increase in clock speed and introducing a new node that doubles the performance at the same power level as NPU 3. This results in peak performance quadrupling, making NPU 4 a powerhouse for demanding AI applications. The new MAC array features advanced data conversion capabilities on a chip, which allow for a datatype conversion on the fly, fused operations, and layout of the output data to make the data flow optimal with minimal latency.
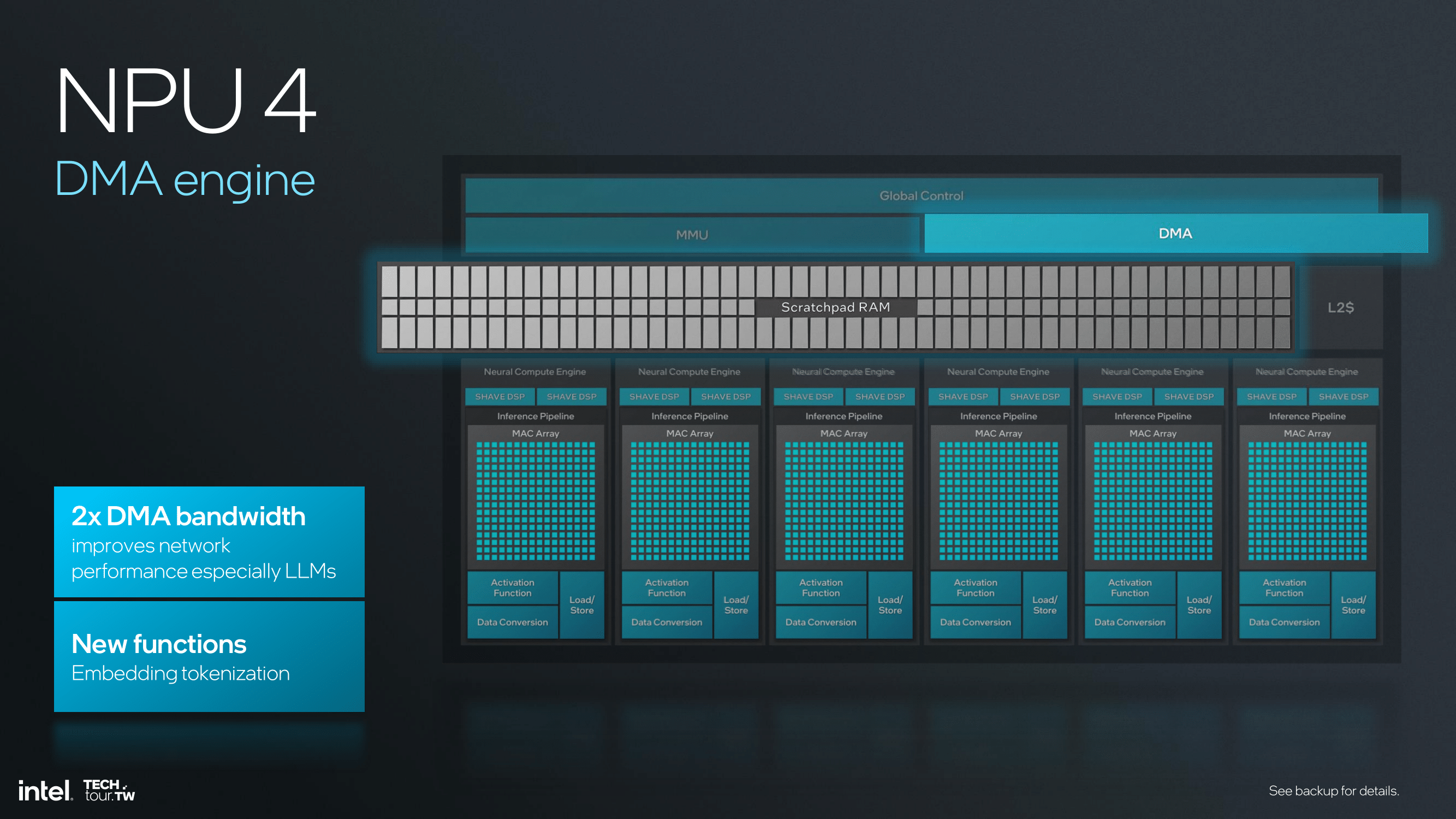
The bandwidth improvements in NPU 4 are essential to handle bigger models and data sets, especially in transformer language model-based applications. The architecture supports higher data flow, thus reducing the bottleneck and ensuring it runs smoothly even when in operation. The DMA (Direct Memory Access) engine of NPU 4 doubles the DMA bandwidth—an essential addition in improving network performance and an effective handler of heavy neural network models. More functions, including embedding tokenization, are further supported, expanding the potential of what NPU 4 can do.
The significant improvement of NPU 4 is in the matrix multiplication and convolutional operations, whereby the MAC array can process up to 2048 MAC operations in a single cycle for INT8 and 1024 for FP16. This, in turn, makes an NPU capable of processing much more complex neural network calculations at a higher speed and lower power. That makes a difference in the dimension of the vector register file; NPU 4 is 512-bit wide. This implies that in one clock cycle, more vector operations can be done; this, in turn, carries on the efficiency of the calculations.
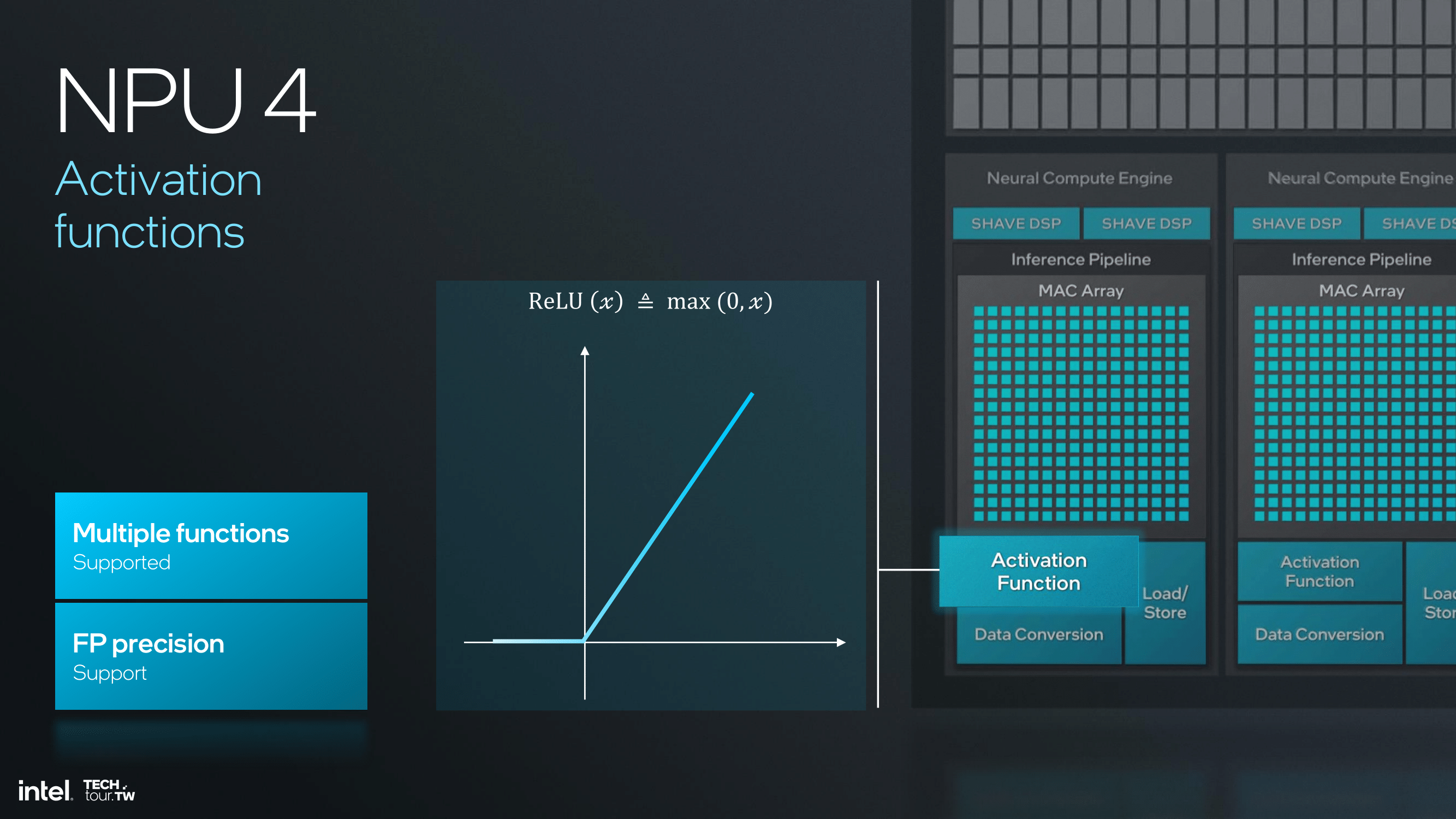
NPU 4 supports activation functions and a wider variety is available now that supports and treats any neural network, with the choice of precision to support the floating-point calculations, which should make the computations more precise and reliable. Improved activation functions and an optimized pipeline for inference will empower it to do more complicated and nuanced neuro-network models with much better speed and accuracy.
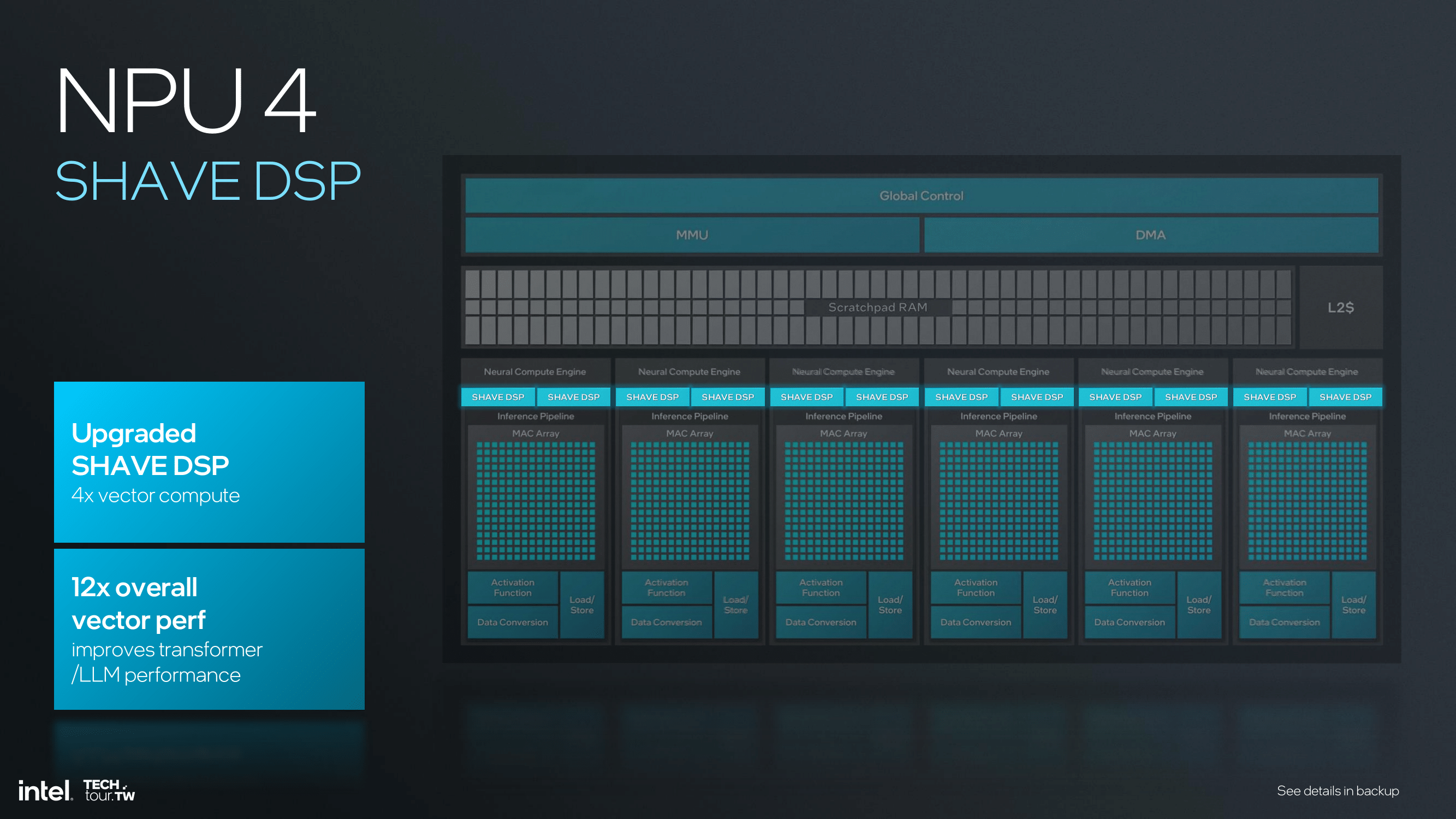
Upgrading to SHAVE DSP within NPU 4, with four times the vector compute power compared to NPU 3, will bring a 12x overall increase in vector performance. This would be most useful for transformer and large language model (LLM) performance, making it more prompt and energy efficient. Increasing vector operations per clock cycle enables the larger vector register file size, which significantly boosts the computation capabilities of NPU 4.
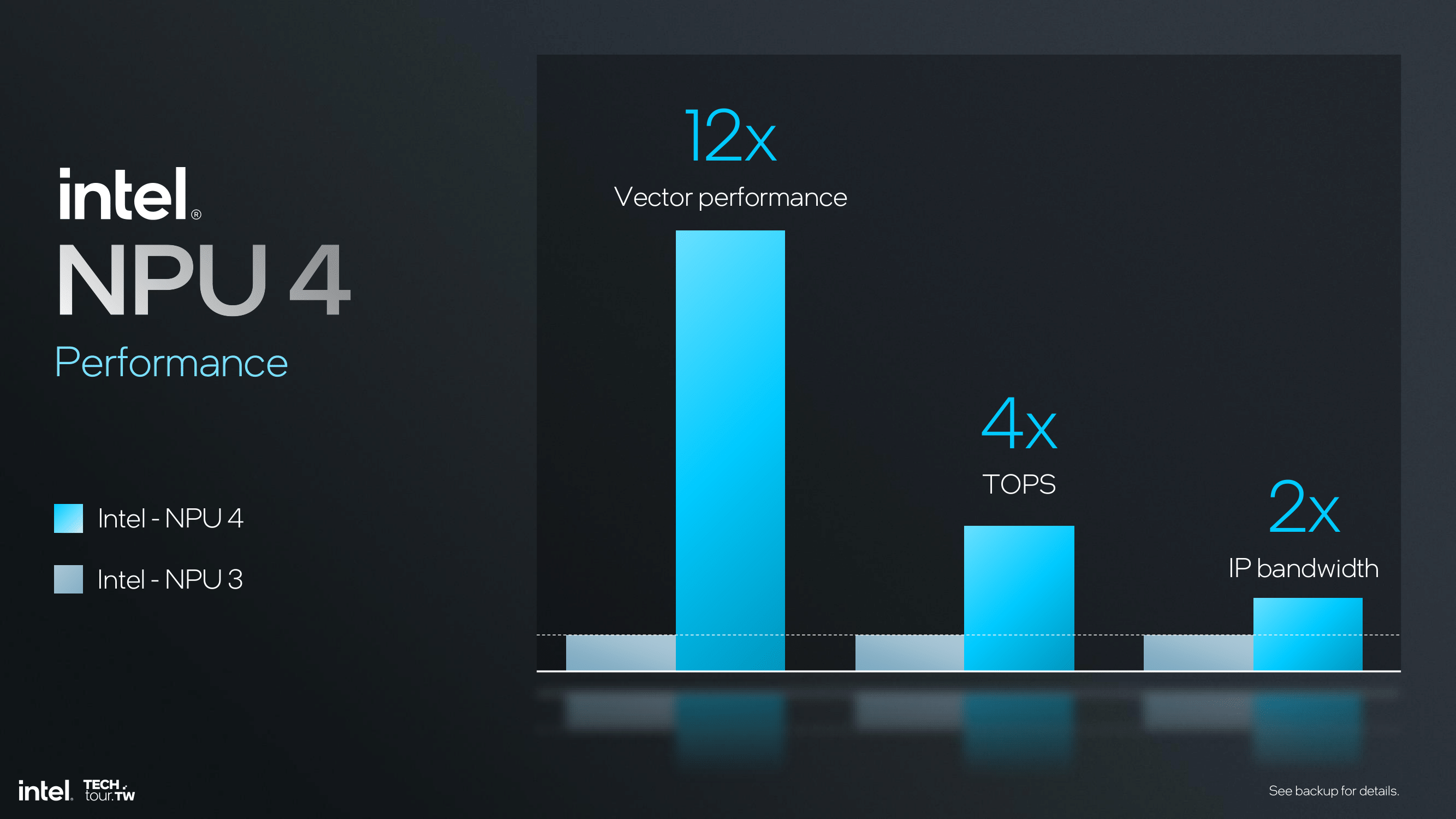
In general, NPU 4 presents a big performance jump over NPU 3, with 12 times vector performance, four times TOPS, and two times IP bandwidth. These improvements make NPU 4 a high-performing and efficient fit for up-to-date AI and machine learning applications where performance and latency are critical. These architectural improvements, along with steps in data conversion and bandwidth improvements, make NPU 4 the top-of-the-line solution for managing very demanding AI workloads.








91 Comments
View All Comments
Ryan Smith - Tuesday, June 4, 2024 - link
"Was there a deadline push to get it out as soon as Intel released the information on Lunar Lake?"Yes. There was a hard deadline on this. Copyediting is ongoing. Reply
Drumsticks - Tuesday, June 4, 2024 - link
Thank you for responding. I hope there’s an opportunity to address some of the writing at a bare minimum and maybe inject some of your own voice.Lunar Lake honestly looks like a pretty big deal. The process is great, the microarchs seem impressive on paper, and it’s coming out to market within a quarter of when it needs to, not within three years. Looking forward to deeper analysis and comparisons, wherever they come from, when the time comes. Reply
NetMage - Tuesday, June 4, 2024 - link
A deadline for what? To regurgitate Intel PR hype as an LLM enhanced unreadable English as a second language article before everyone else publishes their copy of Intel’s Press Release? This article should have never been published.The Xe2 page is particularly horrendous. Reply
Terry_Craig - Thursday, June 6, 2024 - link
There's nothing particularly interesting about Lunar Lake that deserves all this hunger for high-quality content. Replymode_13h - Friday, June 7, 2024 - link
Sarcasm detected. Replyeastcoast_pete - Tuesday, June 4, 2024 - link
Now, I also like good copy editing, but this kind of coverage is done almost in real time. That, plus the time zone difference makes it hard to have a fully copy-edited and proofed article posted, all within hours of the presentation. ReplyDrumsticks - Wednesday, June 5, 2024 - link
I understand that. Anandtech has done it in the past, and produced really stellar coverage that way. I'm a little surprised that some of the paragraphs haven't gotten complete, proper rewrites more than 36 hours after the article went live. (To be fair, that's one business day really). But it's a headliner article on their front page; I'd hoped for more love. Replyskavi - Tuesday, June 4, 2024 - link
Thank you for writing this out. Similar feelings, but I could not have put it so well. Here’s hoping AnandTech can figure out how to get back to that level of quality. ReplyStrom- - Tuesday, June 4, 2024 - link
I loved reading about the benefits of Thunderbolt 5. ReplyEthiaW - Tuesday, June 4, 2024 - link
Well done Intel, receiving enormous CHIPS subsidy while hollowing out production to TSMC tile by tile. Reply