Arm Unveils 2024 CPU Core Designs, Cortex X925, A725 and A520: Arm v9.2 Redefined For 3nm
by Gavin Bonshor on May 29, 2024 11:00 AM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex
- 3nm
- Armv9.2
- Cortex-A520
- Cortex X925
- Cortex A725
Arm Cortex A520: Same 2023 Core Optimized For 3 nm
The Arm Cortex-A520 isn't architecturally different, nor has it been changed compared with last year's TCS2023 introduction. Instead, it has been optimized for the latest 3 nm process technology, enhancing its efficiency and performance. This core, part of the second-generation Armv9.2 architecture, delivers some additional compute power for everyday tasks in mobile and embedded devices while maintaining peak levels of energy efficiency and reducing power consumption expected from Arm's smallest core.
These architectural tweaks ensure that the Cortex-A520 can maximize the potential of the 3 nm process, achieving higher transistor density and better overall performance without any significant changes to its fundamental design.
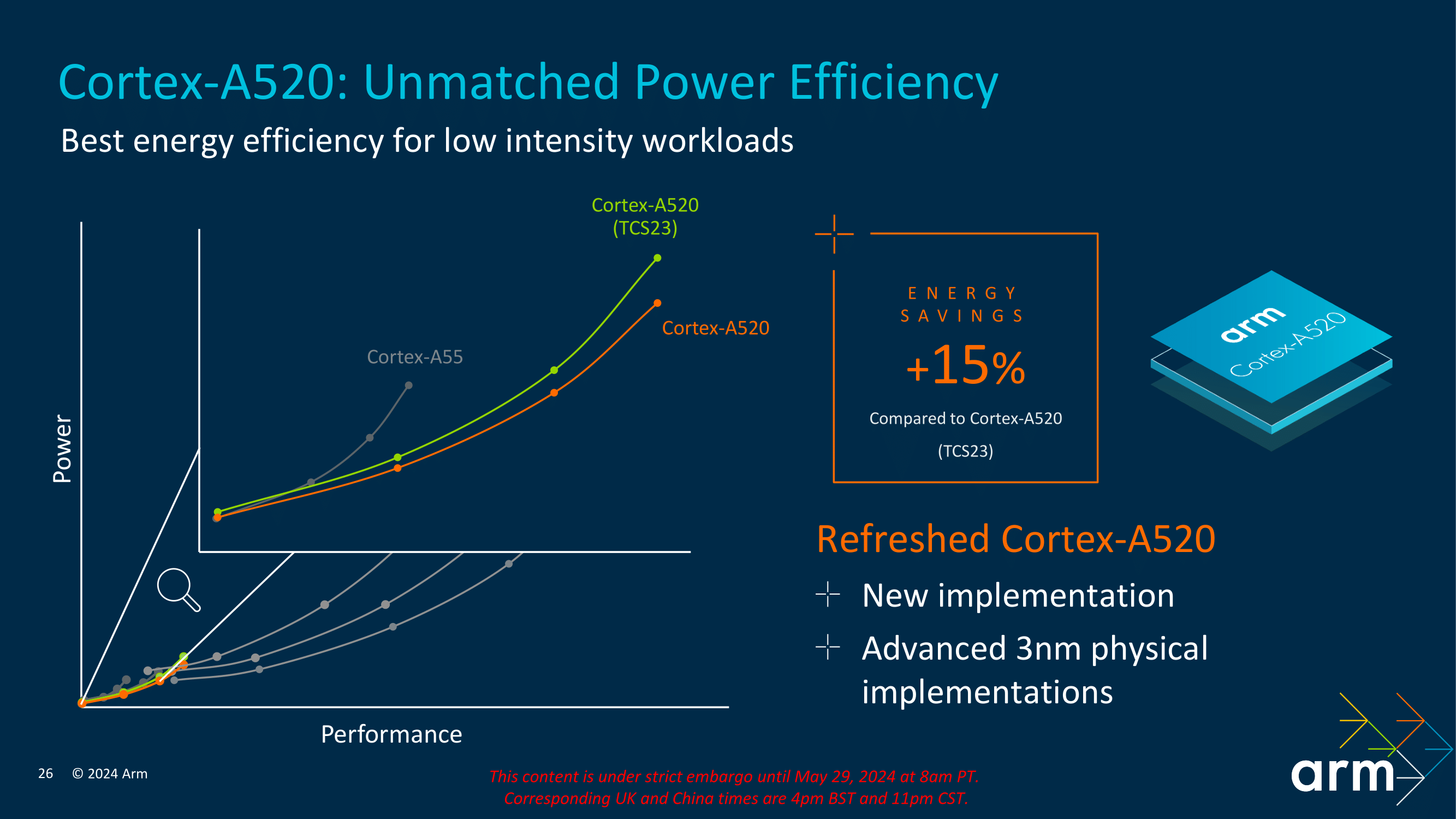
The Cortex-A520 showcases a significant 15% energy saving compared to the Cortex-A520 (TCS23). This improvement is critical for devices with prolonged battery life, such as smartphones and Internet of Things (IoT) devices. By optimizing power consumption, the Cortex-A520 ensures efficient performance without compromising energy usage.
The graph on the above slide clearly illustrates the relationship between power and performance for the Cortex-A520 compared to its predecessor, the Cortex-A55, and the previous Cortex-A520 (TCS23). The latest Cortex-A520 explicitly designed for the 3 nm notably improves power efficiency across various performance levels. This means that the Cortex-A520 consumes significantly less power for a given performance point, demonstrating Arm's commitment to providing performance gains across 2024's Core Cluster and focusing on refining things from a power standpoint to the smallest of the three Cortex cores.








55 Comments
View All Comments
StormyParis - Wednesday, May 29, 2024 - link
Do these processors have anything to prevent exploits such as RowHammer etc ... ? Those & variants have been a big story, then disappeared, but we were never told about an actual solution ? ReplyGeoffreyA - Wednesday, May 29, 2024 - link
Are these companies so lame with their AI desperation? Replyabufrejoval - Wednesday, May 29, 2024 - link
Memory tagging extensions have been around since ARM 8.5. When you say ARM 9.2 MTE, does that mean they have been significantly upgraded e.g. in the direction of what CHERI does for RISC-V?I've been trying to find out if ARM has an "AVX-512" issue with their different big/middle/small designs, too. That is if these distinct cores might actually differ in the range of instruction set extensions they support. And I can't get a clear picture, either.
So if say the big cores support some clever new vector formats for AI and the middle or small cores won't, how will apps and OS deal with the issue? Reply
GeoffreyA - Wednesday, May 29, 2024 - link
I don't know enough about ARM to comment, but should think that there are compatibility issues, with instructions, spanning different models and generations. Perhaps there's a feature-level type of method? ReplyFindecanor - Wednesday, May 29, 2024 - link
ARM MTE is much cruder than CHERI. It can be described as "memory colouring": Every allocation in memory is tagged with one of 16 colours. Two adjacent allocations can't have the same colour. When you use a pointer the colour bits in otherwise unused top bits of the pointer have to match the colour of the allocation it points into.With SVE both E and P cores need to have the same vector length, yes. The vector length is usually no larger than a cache line which have to be the same size anyway.
I don't know specifically about SME but many extensions have to first be enabled by the OS on a core to be available to user-mode programs. If not all cores have an extension, the OS may choose to not enable it on any. Reply
mode_13h - Thursday, May 30, 2024 - link
> The vector length is usually no larger than a cache line which have to be the same size anyway.Cache lines are usually 64 bytes, which is 512 bits. Presumably, the A520 has only SVE2 @ 128 bits. So, don't let ARM off the hook *that* easily! Reply
eastcoast_pete - Wednesday, May 29, 2024 - link
That is very much something I am wondering, too. Reports/rumors have it that, for example, Qualcomm chose not to enable SVE in the big cores of their SD 8 Gen3. Qualcomm isn't exactly forthcoming with information about that, not that I would expect them to comment. Replyname99 - Wednesday, May 29, 2024 - link
That's a silly response. It's like being present at the birth of Mac or Windows and saying "why are these stupid hardware companies trying so hard to make their chips run graphics fast?"The hope of LLMs is that they will provide a substantial augmentation to existing UI. So instead of having to understand a complicated set of Photoshop commands, you'll be able to say something like "Highlight the subject of the photo. Now move it about an inch left. Now remove that power line in the background".
This is not a trivial task; it requires substantial replumbing on existing apps, along with a fair degree of rethinking app architecture. Well, no-one said it would be easy to convert Visicalc to Excel...
But that is where things are headed. And because ARM (and Apple, and QC, and MS) are not controlled by idiots who think only in terms of tweets and snark, each of these companies is moving heaven and earth to ensure that they will not be irrelevant during this shift.
(Oh, you thought the entire world consisted of LLMs answering questions did you? Strange how the QUESTION-ANSWERING COMPANY, ie Google, has created that impression...
Try thinking independently for once. Everything in the world happens along a dozen dimensions at once. All it takes to be a genius is to be able to hold *more than one* dimension in your head simultaneously.) Reply
FunBunny2 - Wednesday, May 29, 2024 - link
Well, no-one said it would be easy to convert Visicalc to Excel..well... Mitch did it, in assembler at first, and called it Lotus 1-2-3 Reply
GeoffreyA - Thursday, May 30, 2024 - link
You can go on with your ad hominen and air of superiority; it won't change that these companies are tripping over themselves, in insecurity and desperation, to grab dollars from the AI pot or not be left behind.You make assumptions about my ideas based on one sentence. In fact, AI is quite interesting to me. Not how it's going to help someone in Photoshop or Visual Studio, but where LLMs eventually lead; whether they end up being the language faculty in strong AI, or more; what's missing from today's LLMs (state, being trained in real-time, connecting to the sense modalities, using little power in a small space, etc.); and whether consciousness, the last great riddle, will ever be solved, how, and the moral implications. That's of interest to me.
But when one see Microsoft and Intel making an "AI PC," or AMD calling their CPU "Ryzen AI," and so on, it is little about true AI and more about money, checklists, and the bandwagon. Independence of thought is about seeing past fashion and the in-thing. And no thank you: I have got no desire, nor the insecurity, to want to be a genius. Reply